本文讨论了基于离线模型的强化学习(MBRL)中的模型估计,这对于后续使用估计模型改进策略非常重要。从协变量转移的观点来看,一个自然的想法是通过离线数据和真实未来数据的状态行为分布的比率加权模型估计。然而,估计这样的自然权重是政策外评估的主要挑战之一,这并不容易使用。作为一种人工选择,本文考虑使用离线数据和模拟未来数据的状态-动作分布比进行加权,这可以通过用于监督学习的标准密度比估计技术相对容易地估计。基于人工权重,本文定义了离线MBRL的损失函数,并提出了一种优化算法。使用人工权重进行加权被证明是评估策略评估误差的上限。数值实验证明了人工加权的有效性。

强化学习(RL)是一种在未知环境中学习策略的框架[1]。基于模型的RL(MBRL)是一种明确估计过渡模型并利用它改进策略的方法。与无模型RL相比,MBRL的一个主要优势是数据效率[2-4],这对于数据收集昂贵的应用程序(如机器人或医疗保健)非常重要。本文关注离线MBRL,即从先前收集的数据集学习策略的MBRL。离线MBRL的主要挑战之一是分销转移[5]。离线数据的分发与将来应用改进策略时获得的数据的分发不同。这是一种称为协变量转移的情况,其中使用标准监督学习技术(如经验风险最小化(ERM))估计的模型可能无法推广到测试数据。MBRL的一个主要思想是使用这种标准方法估计模型,并在预测准确的地区使用估计模型改进政策[6-8]。这里需要改进的一点是不考虑协变量偏移的模型估计。在协变量转移下的监督学习中,重要性加权ERM可以获得良好的预测性能[9]。如果离线MBRL中的模型可以以类似的方式进行估计,那么估计的模型将做出更准确的预测,从而提高策略改进。基于此,本文解决了离线MBRL中考虑协变量移位的加权模型估计问题。从协变量转移的角度来看,一个自然的想法是用离线数据和真实未来数据的状态行为分布的比率进行加权,因为代理使用模型来预测真实未来数据。为了方便起见,本文将该比率称为“自然权重”。然而,估计自然权重是政策外评估的主要挑战之一[5,10]。与监督学习的密度比估计[11]相比,非策略评估的困难在于无法从真实未来数据的分布中获取样本。
作为替代方案,本文考虑使用离线数据和“模拟”未来数据的状态行为分布比进行加权。这篇论文将这一比例称为“人造重量”,与自然重量形成对比。与真实的未来数据不同,模拟的未来数据可以在离线模拟中生成。由于来自两种分布的样本都是可用的,因此可以通过用于监督学习的标准密度比估计技术相对容易地获得人工权重。基于人工权重,本文在第4节中定义了离线MBRL的损失函数。本文在第5节中提出了一种优化算法。这里的问题是使用人工权重进行加权的有效性,因为这对于协变量移位可能不是自然的。本文在第4节中将其证明为评估政策评估误差的上限。本文在第6节的数值实验中证明了其在实践中的有效性。以上是本文的贡献。

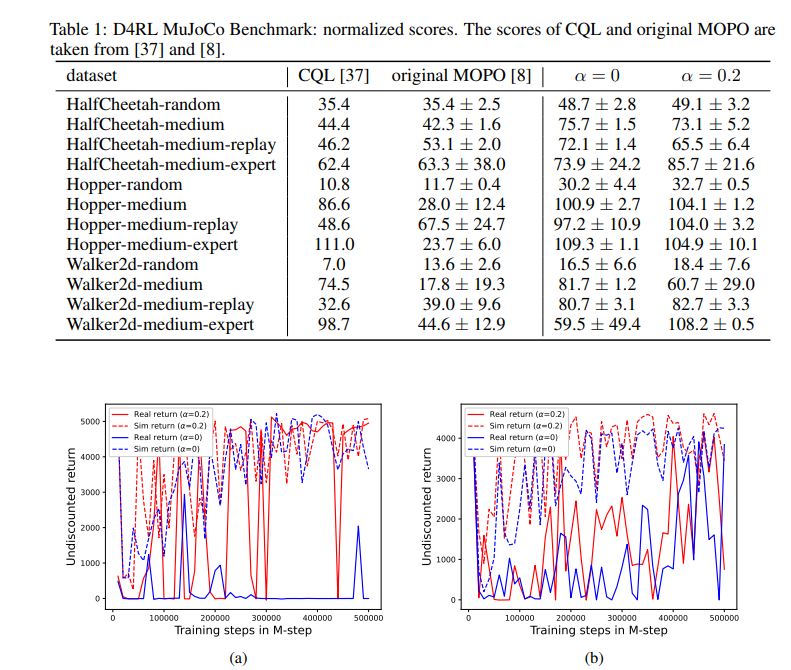
本文讨论了离线MBRL中考虑协变量移位的加权模型估计。本文的主要思想是用人工权重加权,这相对容易估计。基于这一思想,本文定义了离线MBRL的损失函数,并提出了优化算法。本文证明了这一观点是对政策评估误差上限的评估。本文证明了这一思想在数值实验中的有效性。本文的主要贡献是证明了人工加权的有效性。建议的算法在第6.1节中显示了明显的改进,而在第6.2节中仅改进了一个情况。造成这种差距的一个原因可能是第6.1节需要插值,而第6.2节需要外推。虽然内插和近外推可以通过重要性加权来解决,但远外推需要额外的想法,例如使用结构化先验。由于需要进一步讨论,我们将其留给未来的工作。另一个有趣的方向是扩展到贝叶斯MBRL[38,39]。在协变量移位下的监督学习中,可以使用加权似然函数来定义后验分布[9]。如本文所示,在离线MBRL中,用人工权重加权的似然函数是有效的。结合这些思想,将在贝叶斯MBRL中引入考虑协变量移位的加权后验。