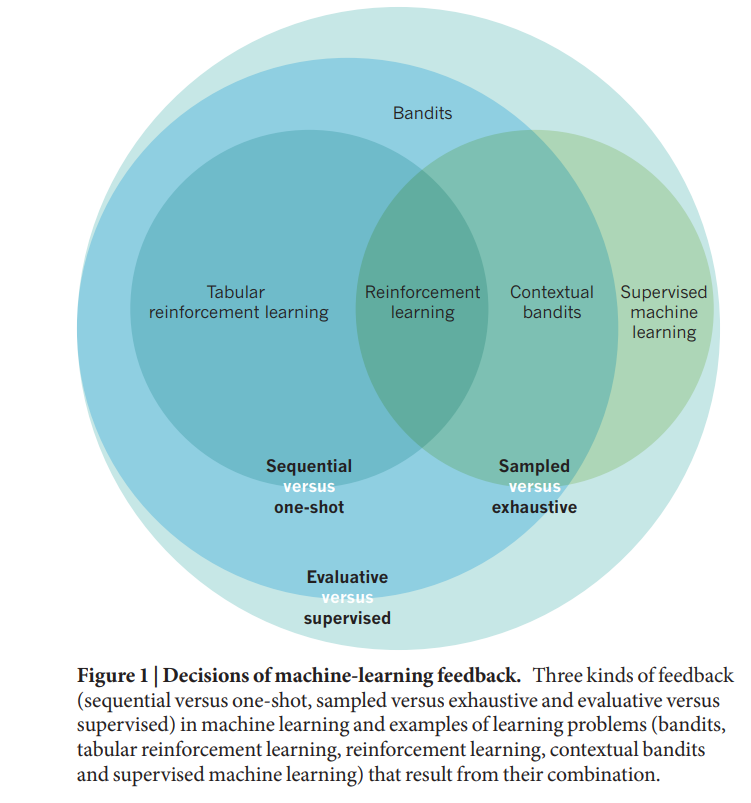
强化学习算法1,2的灵感来源于我们对人类和其他动物决策的理解,在这些决策中,学习通过使用奖励信号来响应观察到的行动结果来进行监督。随着我们对这类问题的理解的提高,我们将其应用于实际环境的能力也随之提高。强化学习对诸如如何创建更有效的个性化网络体验等根本问题以及诸如如何为传统棋牌游戏围棋或20世纪80年代的电子游戏设计更好的计算机化玩家等深奥问题产生了重大影响。强化学习也为心理学、认知科学、行为经济学和神经科学的工作提供了一个有价值的概念框架,试图解释自然世界中的决策过程。一种思考机器学习的方法是作为一组技术来尝试回答这个问题:当我处于情况x时,我应该选择什么反应?作为一个具体的例子,考虑将顾客分配到餐厅的桌子上的问题。不同大小的参与者以未知的顺序到达,主机将每个参与者分配到一个表中。主机将当前情况x(最新一方的大小以及关于哪些表被占用以及占用时间的信息)映射到一个决策(将哪个表分配给该方),试图满足一组相互竞争的目标,例如最小化表的等待时间、平衡各服务器之间的负载以及确保一方的成员可以坐在一起。类似的分配挑战出现在俄罗斯方块等游戏和数据中心任务分配等计算问题中。从更广泛的角度来看,该框架适用于需要做出一系列决策以最大化不确定结果的评分功能的任何问题。学习顾客分配问题良好行为所需的方法类型取决于决策者在学习时可获得的反馈信息类型(图1)。穷尽反馈与抽样反馈与训练示例的覆盖范围有关。给予详尽反馈的学习者会接触到所有可能的情况。抽样反馈较弱,因为学习者只能获得一部分情况的经验。经典监督学习的核心问题是从样本中概括。监督反馈与评估反馈的关系在于如何告知学习者正确和错误的答案。应用监督学习方法的一个要求是具有已知最优决策的示例的可用性。在客户分配问题中,培训中的主持人可以作为更有经验的主管的学徒,学习如何处理各种情况。然而,如果学徒只能从监督反馈中学习,那么在学徒期结束后,她将没有机会提高。相比之下,评价性反馈为学习者提供了对其所做决策有效性的评估;没有关于替代方案适当性的信息。例如,主机可能会通过反复尝试了解服务器处理不守规矩的客户的能力:当主机分配给一个困难的客户时,可以判断所选服务器是否进展顺利,但没有直接信息表明其他服务器中的一个是否是更好的选择。强化学习领域的核心问题是应对评价反馈的挑战。单次与顺序反馈的关系涉及学习信号的相对定时。评估反馈可细分为是否直接为每个决策提供,或是否具有在一系列决策中评估的长期影响。例如,如果一位主人需要为一个12人的聚会安排座位,而没有大桌子可供选择,那么过去决定让一个小聚会坐在一张大桌子上可能会受到指责。强化学习者必须解决这个时间信用分配问题,才能在面对这种弱的顺序反馈时获得良好的行为。从一开始,强化学习方法就同时对抗了所有三种形式的弱反馈——抽样反馈、评估反馈和顺序反馈。因此,这个问题比监督学习要困难得多。然而,可以从薄弱的反馈来源中学习的方法更普遍适用,并且可以映射到各种自然发生的问题,如赞助人分配问题所建议的。以下章节描述了强化学习的几个子领域的最新进展,这些领域正在扩展其功能和适用性。