1.因为环境情况的变化,agent会在激进/保守的策略中进行切换,导致优势值在正负方向存在不同的分布(经检查,正态性检验p值远小于0.05,不是正态分布),这种情况下还能使用PPO常用tirck Advantage Normalization(对优势值进行Z-Score Normalization)嘛?
2.我对优势值进行Advantage Normalization(减均值除以标准差)后,分布如下
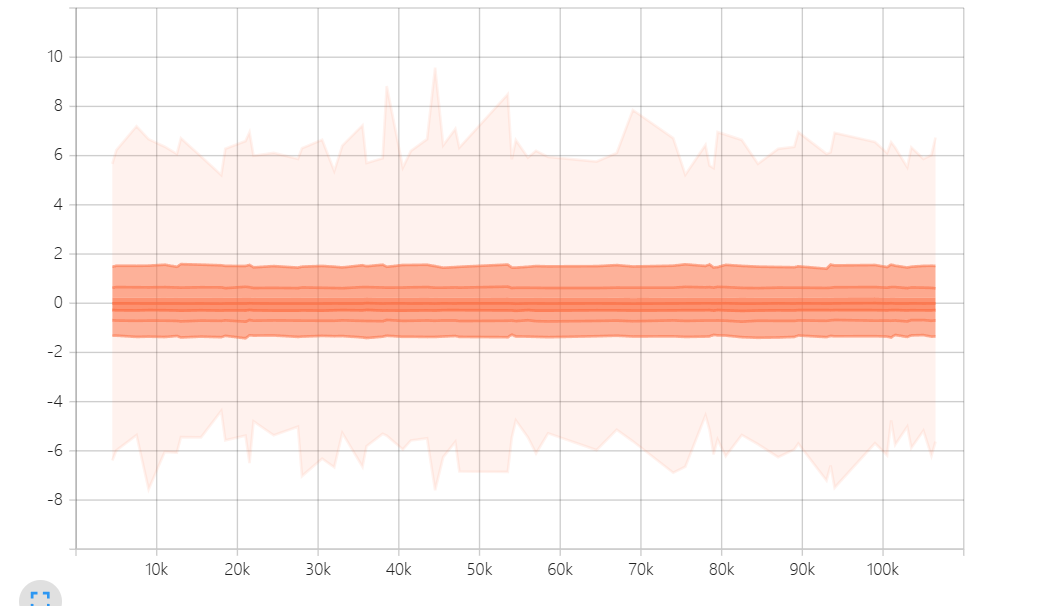
在实践中,我发现越偏离均值的优势值会被高估或者低估(因为环境具有随机性,优势值为8的动作并不比优势值为2的动作好四倍,可能只是略好一点;差动作也是这样)。将优势值强行裁剪到[-2,+2]又会损失很多有效信息,有没有一些比较好的处理方法能解决这种情况?