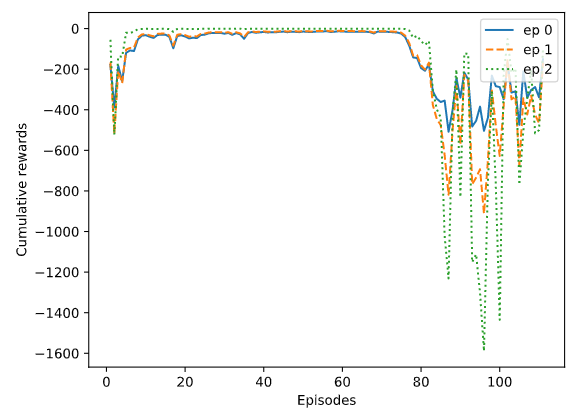
想请教各位:用DDPG来训练agent时,出现了reward开始时收敛、而后发散的问题,求问原因和解决办法,不胜感激!
FYO 一般应该是学习率的原因、或者试试换个优化函数
1、建议参考一下A3C算法论文里的不同学习率对下的收敛速度 2、建议阅读一下Deep Reinforcement learning that matters论文里的各种影响因素对强化学习算法的影响。
尝试调小学习率呢
Air-legend 谢谢!试了很多组学习率,目前看来效果不是特别明显
[未知] 好的!谢谢你的建议!