
作者:曾伊言
仿真环境的采样速度慢,是强化学习的一个瓶颈。例如,论文中常用的MuJoCo环境,台式机或服务器的CPU上运行仿真环境,一小时大概采集十万或百万步(1e5或1e6步);训练一个智能体(收敛后)需要十多个小时。
加快仿真环境的采样速度,通常有以下方法:
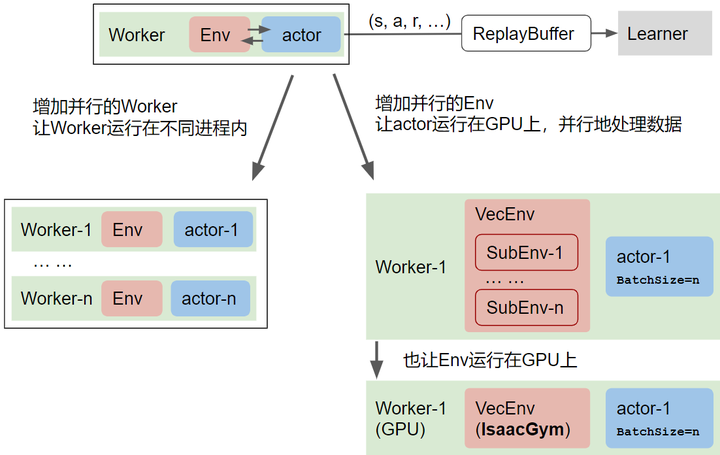 解决仿真环境采样速度慢的问题,有两类方法:增加并行的Worker数和Env数.
解决仿真环境采样速度慢的问题,有两类方法:增加并行的Worker数和Env数.
NVIDIA的Isaac Gym(上图中右下角),用单块GPU一小时内可以采集一亿步(1e8步)。也就是说,GPU上的并行仿真环境,采样速度快了两个量级! 下图是我们的一组测试结果
Isaac Gym 的命名根据 Isaac Newton 艾萨克·牛顿
 在Isaac Gym并行仿真环境的Ant测出来的结果 (注意,它与MuJoCo的同名环境不一样,不要直接对比)
在Isaac Gym并行仿真环境的Ant测出来的结果 (注意,它与MuJoCo的同名环境不一样,不要直接对比)
左图以采样数#samples 为横坐标,右图以训练时间 (hours) 为横坐标。上图中可以看到,GPU并行仿真环境在一天内就达到1e9步。我们也测试了 Isaac Gym 的 Humanoid 环境:
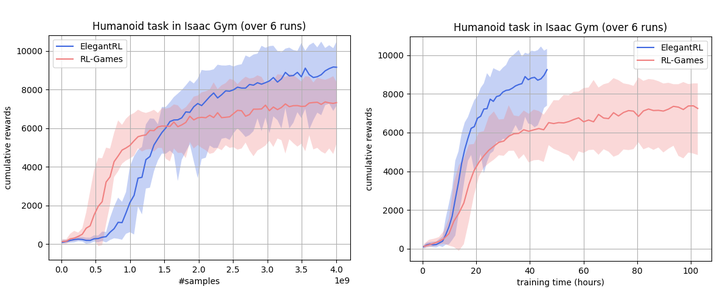 在Isaac Gym并行仿真环境的Humanoid测出来的结果 (注意,它与MuJoCo的同名环境不一样,不要直接对比)
在Isaac Gym并行仿真环境的Humanoid测出来的结果 (注意,它与MuJoCo的同名环境不一样,不要直接对比)
在Isaac Gym之前,也有其他方案:在CPU上,并行地开启多个物理引擎对应多个子环境,然后把子环境的交互数据收集起来。例如 MuJoCo+stable baselines3 的 subprocVecEnv,详见目录的「路线2.1:增加worker内部的并行程度」
Isaac Gym 的大规模并行仿真方法与其他方案有很大不同:它在GPU上,只开启一个物理引擎,在其中并行的运行多个子智能体。由于用GPU进行并行仿真,所以它的计算效率很高。由于只开启一个物理引擎,所以它的资源占用低。详见「路线2.2:用一个物理引擎跑并行仿真环境」

Isaac Gym并行仿真环境的Ant
在Isaac Gym 之前,在一台服务器上,很难想象开启上百个环境做并行仿真,而Isaac Gym在GPU开启上千个并行环境。

Isaac Gym并行仿真环境的Humanoid
知乎上,关于Isaac Gym的资料不多,开源的DRL库对接 Isaac Gym的也少,所以我们准备分享相关的代码和测试结果。以下三篇文章,将陆续更新超链接:
并行环境让采样速度快两个量级:Isaac Gym提速强化学习(这篇文章帮助网友了解GPU并行采样)
并行环境让采样速度快两个量级:安装Isaac Gym Preview 3,并配置训练Isaac Gym的ElegantRL库的代码(第二篇文章,帮助网友体验GPU并行采样)
并行环境让采样速度快两个量级:交流适配并行环境的强化学习库设计思路(第三篇文章,深入GPU并行采样,交流设计思路)
如果对GPU并行仿真环境感兴趣,请接着看下面的讨论:
如何一步步提高强化学习的采样速度?
采样速度慢如何拖慢强化学习训练?
在Isaac Gym之前,强化学习的机器人仿真物理环境有:MuJoCo,PyBullet 等,采用标准的OpenAI gym 环境,调用 env.step(...) 函数让智能体与仿真环境交互,并返回 state, reward, done等交互结果:运行 env.step (加上env.reset)的次数,就是智能体在环境中的采样步数。完整的强化学习训练流程可以用下图表示,下图中红色框Env就是仿真环境:

在Worker里,代表智能体agent 的策略网络actor 与环境交互
产生的数据存放在 ReplayBuffer 的这个数据集里
在Learner里,强化学习算法使用ReplayBuffer中的数据对策略网络进行更新
从第二步开始,ReplayBuffer数据就被存放在GPU的显存里,在第三步,Learner可以用GPU进行高效训练(曾伊言:小雅 ElegantRL: 基于PyTorch的轻量-高效-稳定的深度强化学习框架)。**由于env.step是在太慢了,**第一步的Worker成为性能瓶颈。相关的研究人员针对这个瓶颈给出了多种并行方法:
路线1:一个worker慢?那么可以用多进程开多个worker
几百个CPU核心在单台、多台服务器上被用满后,CPU资源被充分利用。好的强化学习库就应该有开多个worker的功能(multiple workers)。开多少个worker,速度就提高多少,开到CPU计算资源快用尽了为止。
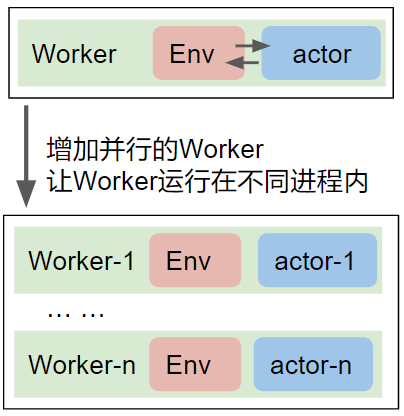
路线2.1:增加worker内的并行度
一些简单例子中,常用2~3层全连接层作为策略网络,这种条件下,在Worker里,既然红色的仿真环境Env运行在CPU上,那么蓝色的策略网络Actor也用CPU去运行反而更快。这是因为:
当强化学习“加上”深度神经网络“变成”深度强化学习后,GPU开始成为加速强化学习研究必的重要设备。所以,路线2开始想办法让Actor网络运行在GPU上,且尽量让并行数大于1,于是并行仿真环境 Vectorized Env 的思路出现了。
一个标准的仿真环境如下:
env = gym.make('env_name')
state = env.reset()
action = Actor(state)
state, reward, done, info = env.step(action)
以PyTorch 为例,注意到使用策略网络推理时,并行数等于1的情况,需要先把state传入GPU,还要用 unsqueeze 给张量增加一个维度,以适应深度学习框架的默认张量格式,输出action后,同样需要降维度,并传回CPU。
# action = Actor(state)
tensor_state = torch.tensor(state, device=gpu_device).unsqueeze(0) # 传入GPU,增加一个维度
tensor_action = actor_network(tensor_state)
action = tensor_action.detach().squeeze(0).cpu().numpy() # 传回CPU,降低一个维度
assert state.shape == (state_dim, )
assert tensor_state.shape == (1, state_dim)
改为 并行环境 Vectorized Env 后(并行个数为 N),除了不需要升降维度的操作外,更重要的是,actor_network在GPU上,可以一次性将N个 state 映射到 action,计算速度、效率大大提高:
# action = Actor(state)
tensor_state = torch.tensor(state, device=gpu_device).unsqueeze(0) # 传入GPU,增加一个维度
tensor_action = actor_network(tensor_state)
action = tensor_action.detach().squeeze(0).cpu().numpy() # 传回CPU,降低一个维度
assert state.shape == (state_dim, )
assert tensor_state.shape == (1, state_dim)
 BatchSize 表示策略网络推理时的并行数
BatchSize 表示策略网络推理时的并行数
有了并行环境的设计思路后,接下来就需要在上图红色的 Vectorized Env上继续改进了,相关的工作有:
策略网络并行+串行环境(同步),Stable Baselines 3 DummyVecEnv
策略网络并行+并行环境(同步),Stable Baselines 3 SubprocVecEnv
策略网络并行+并行环境(异步),EnvPool
以上的工作中,EnvPool已经是把设备性能发挥得很好的开源作品了,大部分标准的 gym 仿真环境都能用 EnvPool 在CPU上得到非常明显的加速。
路线2.2:用一个物理引擎跑并行仿真环境

如果你想要尝试物理引擎上的GPU并行仿真加速,那么NVIDIA推出的Isaac Gym 可以满足这个需求
以往的并行仿真需要为N个子环境开启N个物理引擎,这造成资源的极大浪费。MuJoCo等环境用CPU去支持物理引擎的计算,由于CPU算力有限,因此一个物理引擎里放上一个智能体已经让env.step的计算耗时变得足够慢了。而Isaac Gym 把这些计算搬到了GPU上,然后利用GPU的并行计算优势,往物理引擎里放上上千个智能体(如上图)
它基于 PhyX,目前支持物理仿真。用户可以使用Isaac Gym 提供的实例环境(如下图),也用PhyX自己去写。

其他:提供一个GPU并行仿真示例环境(待补充)
Isaac Gym 提供了一个物理引擎,用于仿真并行环境的搭建。下图左部 (Apple Action + Sim) 是计算密集的部分,需要和 中部 (Obs & Reward Calc) 计算稀疏的部分分开。
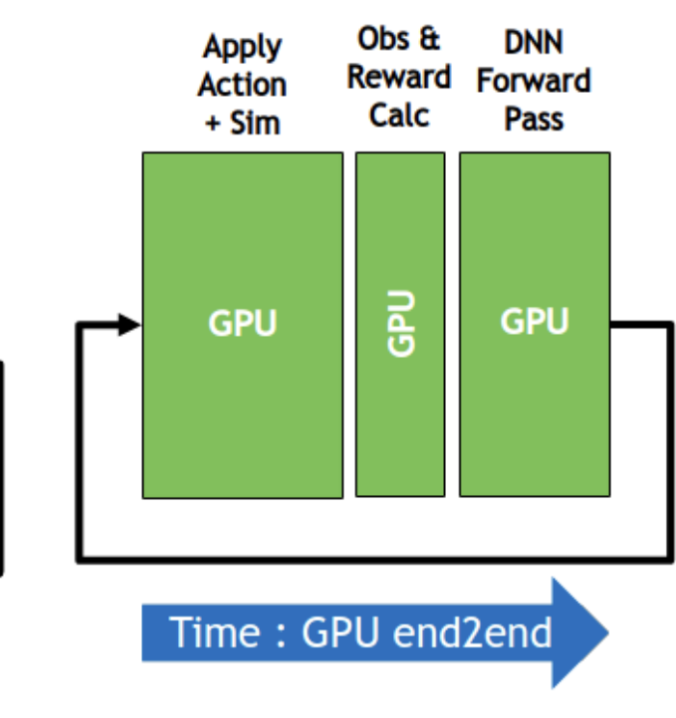
按照这个思想,我们可以仿照Isaac Gym 的并行仿真思路,用PyTorch实现一个自己的并行环境:
尽量在设计并行仿真环境时,把计算密集的部分提取并放置在左部
尽量用GPU计算中部的内容(有需要频繁访问内存的计算操作,或者是无法用GPU实现的操作,可以统一在中部用CPU去计算)
传出仿真环境的数据,要放在连续的内存上,用张量格式直接保存在GPU上,这样才可以直接 传给GPU上的DNN或者ReplayBuffer
How to create a VecEnv on GPU (eg. PointChasingEnv)
其他:增加一个维度给强化学习库数据处理带来的挑战(待补充)
当采样速度不再是RL瓶颈后,强化学习需要做一些改变:
我们选择算法时,可以不追求选用样本利用效率高的算法,而是可以直接暴力地选用工业界最常用的PPO算法或其变体【加一张 on-policy off-policy 轨迹图】。选择超参数时,由于在环境中采样充分,所以超参数的设置可以更加激进(可以追求训练速度而不用担心牺牲稳定性)
我们需要让ReplayBuffer 的数据格式适应这种“多一个维度”的数据。这样才能为并行仿真环境提供充分的加速。打算写到这里→「用并行环境让采样速度快两个量级:交流适配并行环境的强化学习库设计思路(第三篇文章,深入GPU并行采样,交流设计思路)」