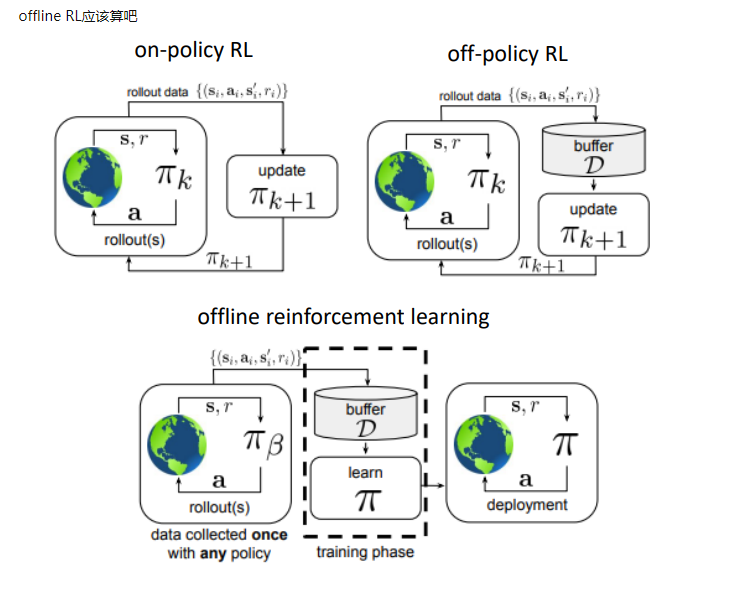
这个问题知乎上俞扬老师已经做过回答,简而言之:on-policy在计算loss时需要求期望,所以不能直接用其他策略产生的样本,如果非要使用Experience Replay(以下称ER),需要用重要性采样(importance sample)进行修正。
举例来说AC算法是on-policy的,ACER就是带重要性采样修正后可以使用ER技巧的off-policy算法。
再简单一个例子:状态s1,动作空间a1、a2,当前策略在s1下选择a1和a2概率分别是0.5,0.5。然后计算发现,选择a1的累计reward比选择a2的更大,所以应该提高s1的概率,经过策略更新后,新策略对于a1、a2的选择概率变成了0.7,0.3。那么问题来了,新策略的选择概率已经变了,如果还用旧样本的0.5,0.5这样的概念计算,就会不对。