腾讯觉悟AI作为一款策略对抗游戏AI取得了显著成绩,可以击败97%的玩家,并且多次击败顶尖职业团队,这一成绩对于作战推演的研究提供了重要的研究思路,虽然作战推演相比较于王者荣耀这类策略对抗游戏要复杂的多,但是其整体思路对于作战推演的智能AI构建依然具有很大的参考价值。因此,全面研究了腾讯AI lab发表的相关论文,总结了一下其研究思路,考虑是否可以借鉴到作战推演的AI设计中,通俗易懂的描述其基本原理。总的来说觉悟AI基本结构就是人工神经网络三大件,同时腾讯觉悟AI定义了两类标签、两类特征、两类神经网络。三大件包括模型输入、模型本身、模型输出;两类标签包括意图标签和动作标签;两类特征包括向量特征和图像特征;两类神经网络包括全连接网络和卷积网络
一、模型输入
模型输入:由于玩游戏时,每个时刻的画面不止一张,而是有多张(比如游戏主画面、英雄属性页),所以把模型每次的输入分成了四个部分
1 地图空间,就是游戏主视野及小地图,利用图像特征输入(包括地形空间,各个英雄之间的相对位置、小兵位置等)
2 单元体的状态特征,单元体就是各个英雄、跑车、龙王等,利用向量特征输入(也在有金币、装备、血量等)
3 游戏内的状态特征,就是游戏中整体的一些特征,利用向量特征输入(比如游戏开始时间、游戏结束时间等)
4 看不见的敌人信息,就是看不见的敌人可能所在的位置、当前血量等,利用向量特征输入,这部分会根据前面提取到的信息来学习如何做出正确的动作。如果击杀成功给一个正奖励,如果被击杀给一个负奖励,同时因为是输入全部的游戏特征信息,所以还会整体考虑动作执行后的效果。比如这次击杀了英雄,却被偷家,即发现整局输掉倒扣更多的分数,这一部分是强化学习的奖赏函数设立,这个在文章中的附录中也给出了,详细请见图1。
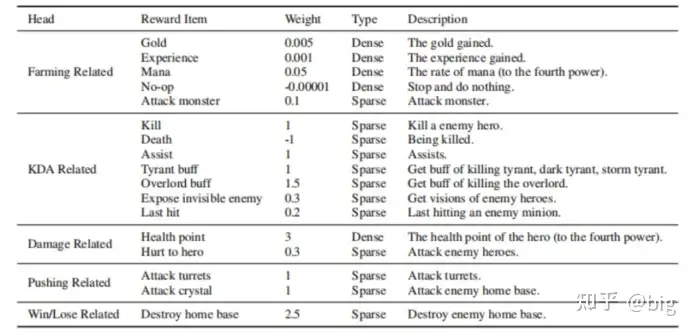
图1 奖赏值设置
二、模型本身
四个部分的输入分别输入到四个小网络中,让他们单独处理,其中向量特征输入的信息比较完整,利用结构相对简单的全连接网络来处理,而对于游戏主视野和小地图信息利用图像特征输入,空间结构相对复杂,所以利用卷积网络来处理。这里卷积网络利用一个一个小区域来提取特征,并且能把各个小区域之间的信息有效的关联起来,然后提取出来的这些特征信息最后还是用向量表示。
但是,这样虽然把一个对抗界面的所有特征提取出来了,但是提取的是一个静态的某一帧的界面信息,并没有把时间步与时间步之间的信息关联起来,所谓一个时间步一般指一帧,当然可以指多帧,那么如何把前面历时的帧信息和现在的信息关联起来?这里就引入了LSTM(Long Short-Term Memory)长短期记忆网络,所以后面加上一个LSTM网络。让LSTM一次接收多个时间步信息来学习这些时间步之间的关联信息,从而让LSTM帮助英雄学习技能组合,并选择英雄应该关注的点应该在主画面和小地图的哪个方面,进而综合输出合理的动作,如图2所示。整个模型流程对于作战推演的模型建立具有很高的参考价值,虽然总体上还难以处理作战推演复杂的环境问题,但是对战役、战术态势图分别建立向量特征和图像特征,提取作战中的单元体的作战属性信息,比如装备速度、弹药量、装甲厚度等等;也可以提取战役经济指标、储备动员数量等宏观战役指标;同时输入整体战略态势图以卷积网络提取对应态势图各算子特征;以及未知区域预测特征信息共同输入LSTM进行动作判断和输出,以及机器关注点输出等,对于作战推演的模型设计来说具有一定的参考价值。那么整个模型执行流程大概如上述,动作输出又是如何执行的?
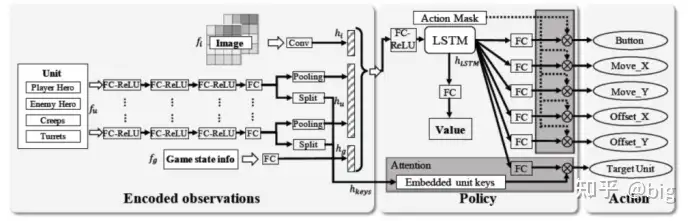
图2 模型执行流程
三、模型输出
这里模型的输出分为了意图标签和动作标签来分别定义。
意图标签。具体来说,意图标签是从游戏中玩家的注意力中抽象出来的,是多视图的。其包括了一个全局意图标签(Global intent)和一个局部意图标签(Local intent)。全局意图标签即把小地图划分为N×N区域并分别进行编号,通过历史数据分析每一个区域的主要作用,比如在小地图中最中间为直接发生对抗的地区,定义为对抗区,野怪密集的地区定位为打野区等等,这样通过历史数据的大量训练后就可以让不同英雄选择各自针对性的策略,比如打野英雄就开局学会往打野区的编号游走,如图3等。而局部意图标签是局部作战中的短期计划,包括在丛林或安全地点集合,撤退到附近的炮塔,或等待目标英雄,最后攻击目标。为了定义局部意图标签,将局部视图地图划分为细粒度的M×M区域(王者荣耀里定义M=12),其中每个局部区域的分辨率设计为大致等于英雄的物理边长度。通过历史数据训练就可以让英雄学会在局部区域学会在哪个位置比较安全,哪个位置比较容易击杀对方英雄。如图4所示,英雄在小地图中选择攻击区域,即确定全局意图标签,然后在主视野中选择蹲草丛区域比较安全,适合埋伏击杀对手英雄。最后,使用多模态特征对这两个意图标签进行训练,然后将它们的softmax结果作为辅助特征提供给动作标签训练任务。我认为这种意图分层的思路完全可以借鉴到兵棋推演或者说作战推演中,推演分为战略、战役、战术层,同样也需要建立不同级别的意图标签,甚至更多层级的意图标签,层次细化解决作战推演所面临的复杂决策问题。
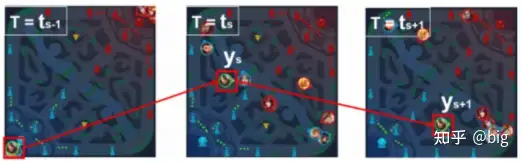
图3 全局意图标签引导走位
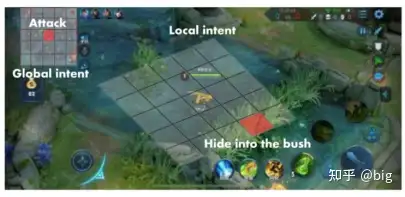
图4 全局意图标签和局部意图标签
动作标签。在觉悟AI中也定义了层次化的动作标签。觉悟AI设计了层次化的动作标签来控制英雄的微观操作,如图5所示。具体来说,每个标签由两个层级(或子标签)组成,它们表示1级和2级操作。第一个动作,即一级动作,表示要采取的动作,包括移动、普通攻击、一技能、二技能、三技能、回血、回城等。第二个是二级动作,它告诉我们如何根据动作类型具体地执行动作。例如,如果第一个层级是移动动作,那么第二个层级就是选择一个二维坐标来选择移动的方向。当第一个层级为普通攻击时,第二个层级将成为选择攻击目标,是哪个英雄,还是小兵,还是防御塔等。如果第一个层级是技能1(或2,或3),那么第二个层级将针对不同技能选择释放技能的类型、目标和区域,如图5所示。这对于兵棋推演中不同算子如何执行动作也具有参考价值,每一个类型的算子同样存在着不同的动作,比如坦克可以选择直瞄射击、间瞄射击,移动方向等,对于实际作战推演不同装备同样有众多复杂的动作,通过这样的特征和标签设计,人工智能建模任务可以作为一个层次化的多类分类问题来解决。具体来说,一个深层次的神经网络模型被训练来预测在给定的情境下要采取什么行动。对于作战推演也可以参考层次化的动作标签来不断细化动作执行过程,进而训练解决复杂的动作执行难题。
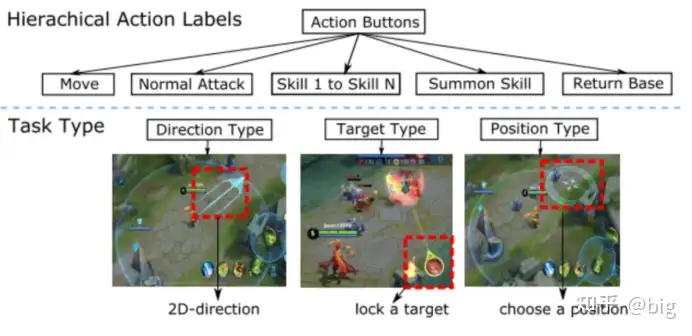
图5 觉悟AI层次化动作标签
整个意图标签和动作标签的流程如图6所示,图6也是对图2的补充细化描述
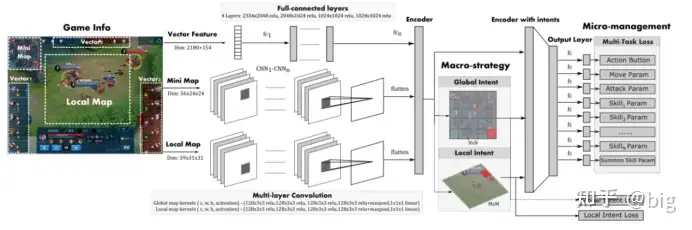
图6 意图标签和动作标签输出流程
四、课程学习
上面所述,已经建立了一个完整的游戏AI模型,但是觉悟AI并没有停止于此。觉悟AI为了训练出一个更为强大的智能AI模型,引入了课程学习(The flow of curriculum self-play learning)思路,这个思路在DeepMind团队的AlphaStar中也使用过,AI效果也得到了明显提升。因为MOBA游戏中英雄数量过多,如果随机地将这些无序的英雄组合呈现给一个学习系统,可能会导致学习崩溃。因此,觉悟AI整个流程就是预先选择N套固定的英雄组合模式,通过上述的AI模型进行训练,作为老师AI模型。当这些老师AI模型达到了Elo一定的分数后全部教育一个学生AI模型,所有这些老师AI模型的经验存储到Replay Buffer中,再让学生AI模型和老师AI模型预测结果进行交叉熵和预测值均方误差计算loss值,不断修正学生AI模型,这些学生AI模型在达到Elo分数阶段后又可以成为新的老师AI模型指导后面的学生AI模型,并最终建立一个可以适用于随机选择英雄搭配的AI模型,如图所示。
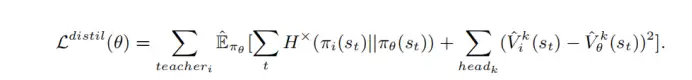
图7 老师AI模型和学生AI模型 Loss值计算
同样在作战推演中也面临着这个问题,作战单元种类更加复杂,直升机、步兵、坦克、舰艇等等,型号也更加复杂,所以如何在作战推演中解决作战兵力搭配问题,这一思路也非常具有参考价值。
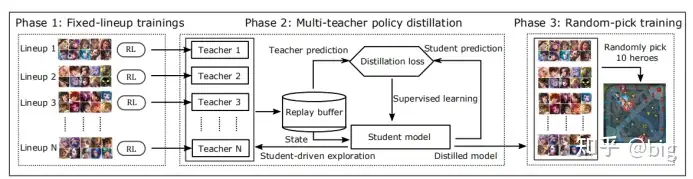
图8 课程学习流程
五、深度学习技术应用
最后,补充一点图像特征的卷积提取。在觉悟AI中图像特征的提取也采取了分层的思想,对于主视野和小地图都采取了不同种类的要素提取到一层,最终每层都提取到一类关键属性节点信息,形成英雄、野怪、小兵位置矩阵,如图9所示。最终将多尺度特征的信息融合形成全局态势特征信息,这一工作在AlphaStar中也是这样利用的。对于作战推演来说,态势理解一直是研究的难点,那么考虑利用深度学习技术来实现态势图像特征的提取,进而最终输出态势图的关键信息将是必由之路。
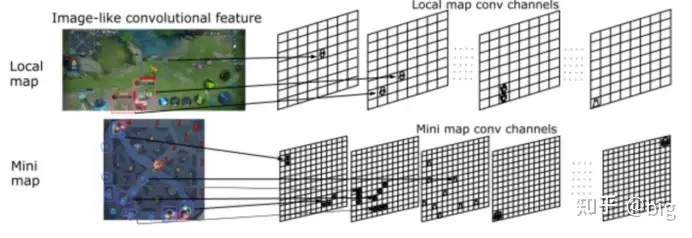
图9 图像特征提取
参考文献
[1] Ye D, Chen G, Zhang W, et al. Towards playing full moba games with deep reinforcement learning[J]. arXiv preprint arXiv:2011.12692, 2020.
[2] Ye D, Chen G, Zhao P, et al. Supervised Learning Achieves Human-Level Performance in MOBA Games: A Case Study of Honor of Kings[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020.