一、简要介绍
和其它机器学习方向(监督、无监督)相似,强化学习也面临着维度灾难的问题。而且因为强化学习本身研究序列化决策问题,当任务复杂时,面临的考验也会更加严峻。具体在强化学习领域,这些问题包括了 如何高效采样、如何实现大规模、探索、抽象等等。
强化学习作为一种主动式学习范式,非常符合人类在学习新知识时的行为:通过和环境交互 ,获得反馈来学习得到某种技能。那么自然地,在解决这些复杂的问题的时候,可以参考到人的一些做法——将问题抽象成不同的层级,从不同层面来处理,这也是HRL的核心思想。
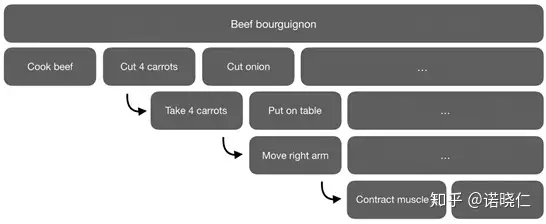
烤牛排的层次做法
比如在烤牛排的时候,我们将从宏观对问题进行分解,烤牛排需要切牛排、切胡萝卜、切洋葱,再深入,我们则可以了解,每个食材应该如何切,切几段。这种将原问题分层解决的方法,就是分层强化学习。
通过分层强化学习,我们希望可以解决长期信度分配的问题,实现更快的学习和更好的泛化;另外,下层策略往往包含语义信息,既可以实现结构化的探索,比如,具体去探索如何切牛肉,同时,这些下层策略也更方便进行迁移。
形式化上,强化学习研究MDP问题,而HRL则研究SMDP问题。
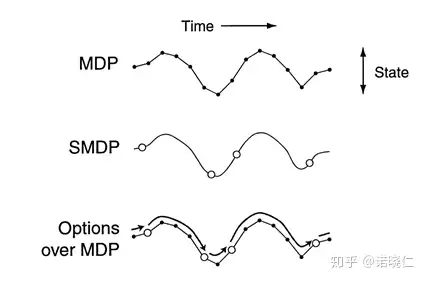
MDP vs SMDP
MDP是每个timepoint,s -> s';而SMDP则允许经过多个timepoint,s -> s'。更直观的,MDP每次和环境交互(一个action)都发生状态的改变,而SMDP则是多次和环境交互(一系列的actions)后,状态才会发生改变。对应到HRL中,我们一般将这 一系列actions 视为一个option。
二、历史
分层强化学习最早一般视为1993 年封建强化学习的提出。
1. 封建强化学习 [3]
封建强化学习是一种从封建等级制度获得灵感,从而设计的一种很朴素的,符合常识的HRL范式。它将整个要解决的问题分为多个层级,上层调用下层来解决任务,下层执行上层的命令(也就是reward设计其实是根据上层的需求实现的)。
封建学习主要的特征有两个:
这种简单的范式虽然没有很好的应用,也蕴含了大量的工程工作,但是这种思想还是给后面的工作提供了很多的思路。
2. Options [4]
Options 框架可以说是最有名也是应用最广的一个框架。既然原始的RL受限于复杂的MDP,尤其是长序列的MDP,那么我们就可以采取某种方式来缩短时间序列,比如,将多个action进行组合,形成一个子技能。
形式化上,我们定义了Options ,包含了进入这个option的初始状态集、当前option的策略以及终止状态。上层策略求解一个semi-MDP问题,来获得对下层Option的调用。 注意,这里的当个action也可以作为一种特殊的option来看待。

Option Framework
Option由三元组<I, π,β>定义。分别表示:能够进入该option的初始状态集合;该option代表的子策略;终止该option的概率(从状态到[0,1]的mapping)。
3. HAM [5]
HAM的全称是Hierarchical of abstraction machine。这里是将原本的MDP问题,直接使用先验知识,来建立一个状态转换机。这个状态转换机分为四种状态:
迷宫环境(存在很多相似的结构)
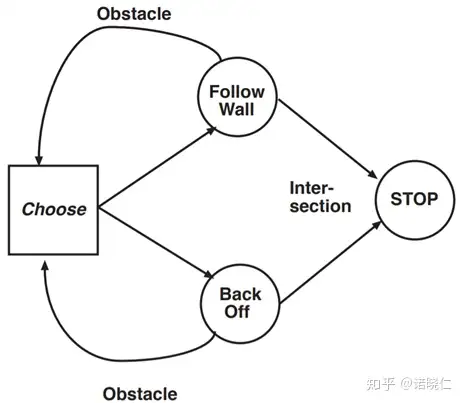
HAM例子
通过设置状态转换机,原始的状态转移被大大缩减了,但HAM的问题是设计起来过于复杂,需要对任务本身有足够多的理解。
4. MAXQ [6]
不同于options框架是从action的视角来进行分层,MAXQ是从任务分解的角度出发的。每个子任务,定义为一个三元组,分别包含了可选的动作、终止状态、以及专属的奖赏函数。

MAXQ
MAXQ每个子任务建模成了一个SMDP问题(也就意味着,没有了Options框架显著的层次关系),每个子任务都可以调用其它的子任务(像调用action一样)。