离线强化学习(RL)为利用大量离线数据进行复杂决策任务提供了一个很有前途的方向。由于分布偏移问题,当前的离线RL算法通常在值估计和动作选择方面被设计为保守的。然而,当在现实条件下遇到观测偏差(例如传感器错误和敌方攻击)时,这种保守主义会损害学习策略的鲁棒性。为了权衡稳健性和保守性,我们提出了一种新的保守性平滑技术——鲁棒离线强化学习(RORL)。在RORL中,我们明确地为数据集附近的状态引入了策略和值函数的正则化,以及对这些状态的额外保守值估计。理论上,我们证明RORL比线性MDP的最近理论结果具有更严格的次优界。我们证明,RORL可以在一般离线RL基准上实现最先进的性能,并且对对抗性观测扰动具有相当强的鲁棒性。

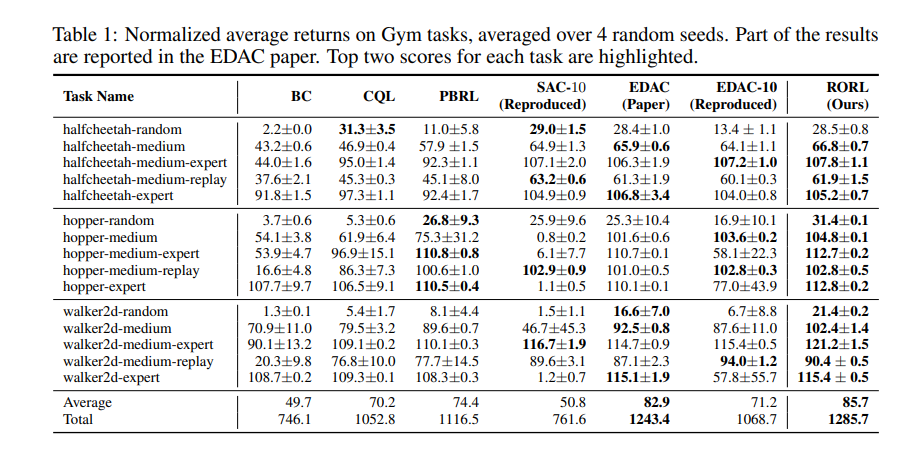
在过去的几年中,深度强化学习(RL)一直是各种决策任务的重要工具[36,49,47,11]。当前深度RL算法的一个主要限制是它们需要与环境进行激烈的在线交互[30,67]。这些数据收集过程在许多现实世界场景中可能成本高昂,甚至令人望而却步,例如机器人和医疗[30,53]。离线RL[14,28]最近越来越受到关注,因为它提供了从完全离线数据集中学习强化决策策略的可能性。离线RL的主要挑战是离线数据集和学习策略之间的分布转移,这将导致严重高估分布外(OOD)行为[14,28]。为了克服这一问题,一系列无模型离线RL工作[59、14、69、29、32、2、66、6]建议庆祝保守主义,例如将学习到的策略限制在支持的分布附近或惩罚OOD行为的Q值。此外,另一系列工作基于基于模型的算法[72,71,58],该算法利用整体动力学模型,通过不确定性惩罚或数据生成来加强悲观主义。然而,当将离线RL应用于现实世界时,保守主义并不是唯一的担忧。由于传感器误差和模型失配,离线RL的鲁棒性在实际工程条件下也是至关重要的,这一点尚未得到很好的研究。在在线RL中,已经研究了一系列工作,以了解在观测[73,41,20]或环境动力学[57,43,44,4]的最坏情况扰动下的最优策略。然而,将在线鲁棒RL技术应用于离线问题并非易事。主要的挑战是,状态的扰动可能会带来OOD观察和对值函数的额外高估。需要新的技术来同时解决离线RL中的保守性和鲁棒性。本文研究了对抗性观测扰动的鲁棒离线RL,其中代理需要在处理具有扰动的潜在OOD观测时保守地学习策略。我们首先证明了当前基于值的离线RL算法缺乏策略所需的平滑度,如图1所示。作为示例,我们展示了著名的基线方法CQL[29]学习了一个非平滑值函数,这导致即使是微小规模的观测扰动也会导致性能显著下降(详见第3节)。此外,简单地对现有方法采用平滑技术可能会导致在支持分布的边界处的额外高估,并将代理引向不安全区域。为此,我们提出了一种新的保守平滑技术——鲁棒离线强化学习(RORL),它明确地处理了OOD状态-动作对的高估。具体地说,我们明确地为接近数据集支持的状态的值函数和策略引入平滑正则化,并基于悲观自举保守地估计这些OOD状态的值。此外,我们从理论上证明了RORL在线性MDP中产生了一个有效的不确定性量词,并且比以前的工作享有更严格的次优界[6]。在我们的实验3中,我们证明RORL可以在D4RL基准[12]中实现最先进的(SOTA)性能,与当前的SOTA方法相比,集成Q网络更少[2]。基准实验的结果表明,鲁棒训练可以在非扰动环境中提高性能。同时,与当前基于集合的基线相比,RORL对观测上的对抗性扰动具有更强的鲁棒性。我们在不同的攻击类型下进行了对抗性实验,在几个连续的控制任务中表现出一贯的优越性能。