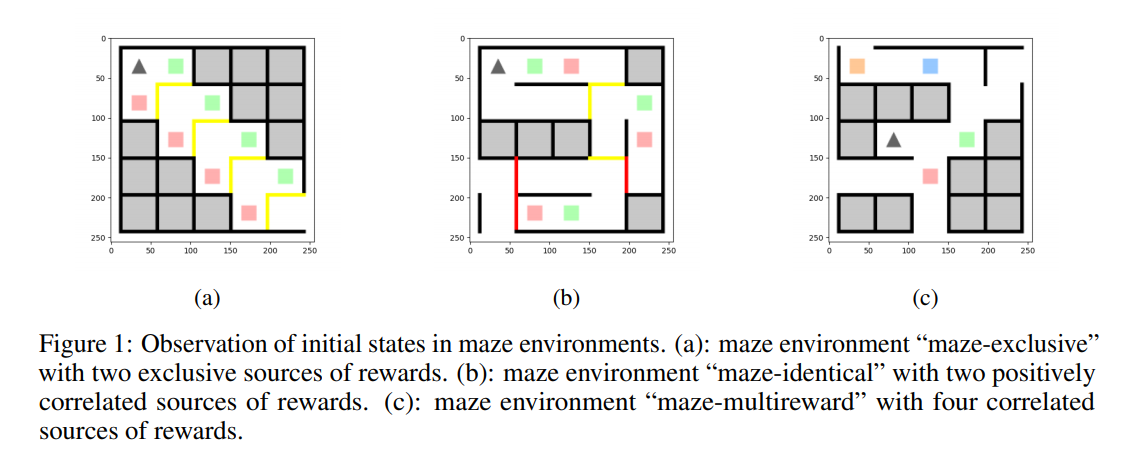
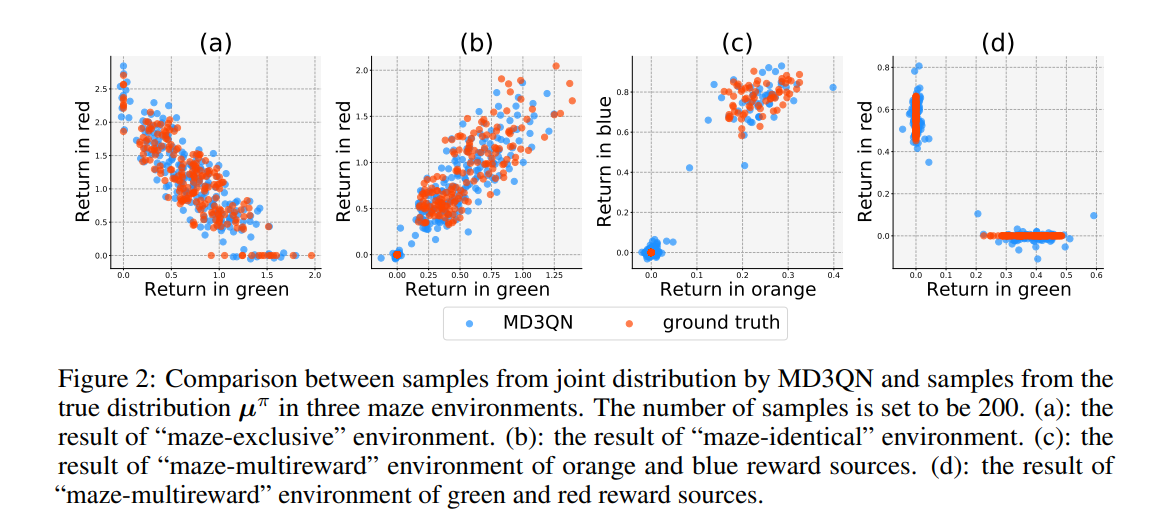
基于价值的强化学习(RL)算法的一个增长趋势是在价值网络中捕获比标量值函数更多的信息。该分支中最著名的方法之一是分布RL,它对返回分布而不是标量值进行建模。在另一项工作中,RL中的混合奖励架构(HRA)已经研究了为每个奖励源建模特定于源的价值函数,这也被证明在性能方面是有益的。为了充分继承分布式RL和混合奖励架构的优势,我们引入了多维分布式DQN(MD3QN),它扩展了分布式RL,以模拟来自多个奖励源的联合回报分布。作为联合分配建模的副产品,MD3QN不仅可以捕捉每个奖励来源的回报的随机性,还可以捕捉不同来源的随机性之间的丰富奖励相关性。我们证明了联合分布Bellman算子的收敛性,并通过最小化联合收益分布与其Bellman目标之间的最大平均差来构建我们的经验算法。在实验中,我们的方法准确地模拟了具有丰富相关奖励函数的环境中的联合回报分布,并在控制设置中优于以前使用多维奖励函数的RL方法。

使价值网络捕获比标量值函数更多的信息是基于价值的强化学习的一个日益增长的趋势,这有助于主体获得更多关于环境的知识,并有助于提高RL主体的样本效率。在深度强化学习的早期阶段,DQN(Mnih等人,2013)使用神经网络的标量输出来表示值函数。随着基于值的RL算法的发展,分布式RL算法开始使用神经网络来近似每个状态-动作对的回报分布,并基于回报分布的期望采取行动。通过捕获随机性作为辅助任务,分布式RL代理可以获得更多关于环境的知识,并学习更好的表示,以避免状态混淆(Bellemare等人,2017)。与DQN相比,分布式RL算法(包括C51(Bellemare等人,2017)、QR-DQN(Dabney等人,2018b)、IQN(Dabney et al.,2018a)、FQF(Yang等人,2019)和MMDQN(Nguyen等人,2020)实现了显著的性能增益。在另一项工作中,HRA(Van Seijen等人,2017)和RD2(Lin等人,2020)考虑了环境中存在多个奖励源的情况,并修改了价值网络,以对每个奖励源的源特定价值函数进行建模。在这些工作中,价值网络的输出可以被解释为多个源特定的价值函数,代理基于所有源特定的值函数的总和采取行动。与收益分配类似,估算源特定的价值函数可以被视为辅助任务,它可以作为对总报酬如何构成的额外监督,并使代理人能够更好地学习表示。之前的几项工作支持,它有利于建模源特定值函数(Boutilier等人,1995;Sutton等人,2011a;Van Seijen等人,2017;Lin等人,2020)。为了提供更多的监督信号并使代理能够获得更多关于环境的知识,我们建议捕获源特定回报中的相关随机性。具体而言,我们将所有奖励来源的特定来源回报视为多维随机变量,并捕获其联合分布,以模拟不同来源回报的随机性。这为我们的代理商提供了一个信息丰富的学习目标。该框架是通用的,可以扩展以捕获除奖励之外的其他类型随机变量的相关随机性。例如,我们可以捕捉在目标条件强化学习中实现不同目标之间的相关性(Schaul等人,2015),或者在后继表征中访问不同的州(Kulkarni等人,2016)。在本文中,我们将重点放在学习给定来源特定奖励的联合回报分布的方法上,并将扩展留给更一般的设置,以供将来的工作使用。