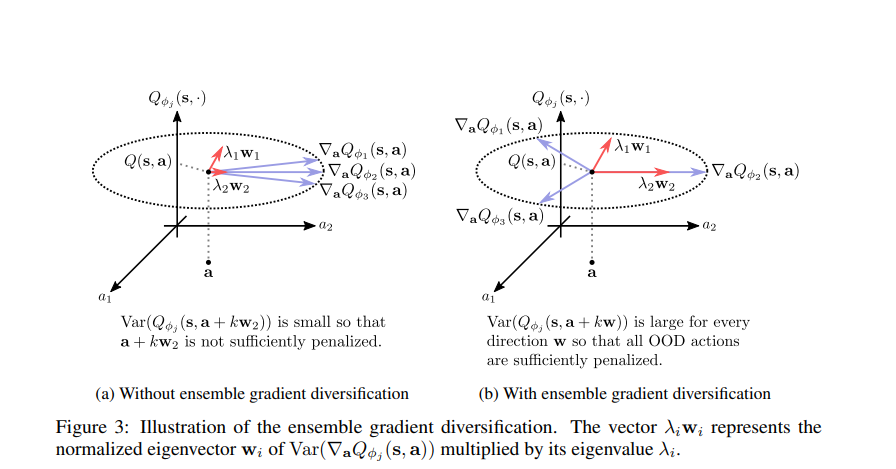
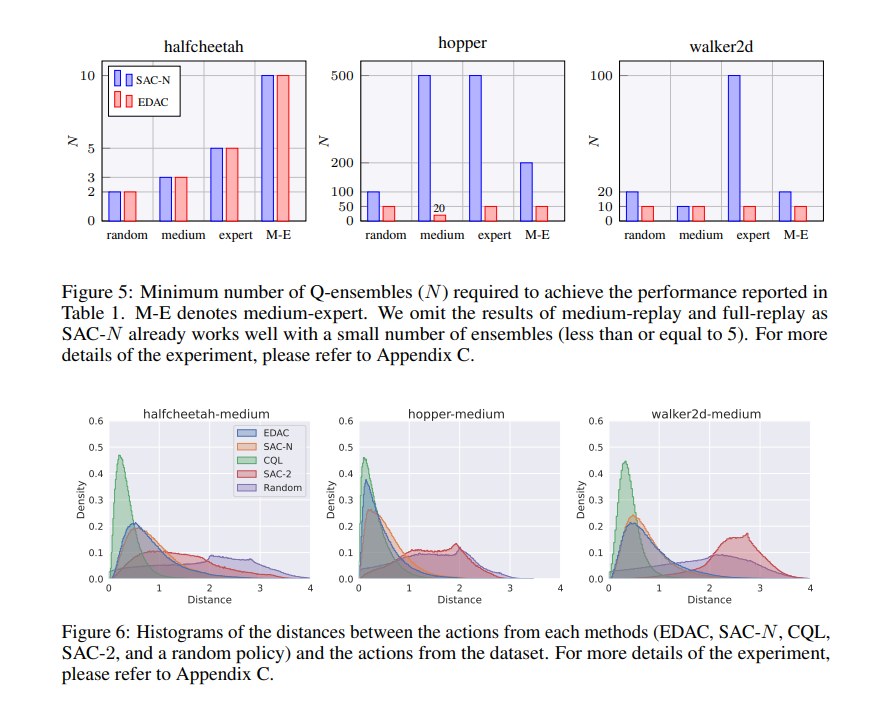
离线强化学习(离线RL)旨在从先前收集的静态数据集中找到最优策略,但由于分布外(OOD)数据点的函数近似误差,它在算法上存在困难。为此,离线RL算法采用约束或惩罚项,明确引导策略保持接近给定数据集。然而,先前的方法通常需要精确估计行为策略或从OOD数据点采样,这本身可能是一个非平凡的问题。此外,这些方法没有充分利用深度神经网络的泛化能力,常常陷入与给定数据集过于接近的次优解。在这项工作中,我们提出了一种基于不确定性的离线RL方法,该方法考虑了Q值预测的置信度,并且不需要对数据分布进行任何估计或采样。我们表明,在线RL中广泛使用的限幅Q学习技术可以成功地惩罚具有高预测不确定性的OOD数据点。令人惊讶的是,我们发现,通过简单地增加Q网络的数量以及限幅Q学习,有可能在各种任务上大大优于现有的离线RL方法。基于这一观察,我们提出了一种集成多样化的演员-评论家算法,与原始集成相比,该算法将所需集成网络的数量减少到十分之一,同时在所考虑的大多数D4RL基准上实现最先进的性能。

近年来,深度强化学习(deep RL)在机器人学[20]、推荐系统[6]和策略游戏[26]等各个领域取得了相当大的成功。然而,RL算法的一个主要缺点是它们采用了主动学习过程,其中训练步骤需要与环境进行主动交互。当将RL扩展到自动驾驶和医疗保健等现实应用时,这种试错程序可能会令人望而却步,因为探索行为可能会对智能体或环境造成严重损害[19]。离线RL,也称为批量RL,旨在通过仅使用先前收集的数据而不与环境进行进一步交互来学习策略来克服此问题[2,11,19]。尽管离线RL是一个很有前途的方向,可以引领一种更为数据驱动的解决RL问题的方法,但最近的研究表明,离线RL面临着新的算法挑战[19]。通常,如果数据集的覆盖范围不够,普通RL算法会严重受到外推误差的影响,从而高估了分布外(OOD)状态动作对的Q值[15]。为此,大多数离线RL方法在现有RL算法之上应用一些约束或惩罚项,以强制学习过程更加保守。例如,一些先前的工作明确地将策略规则化为接近用于收集数据的行为策略[11,15]。最近的一项工作反而惩罚了OOD状态动作对的Q值,以使Q值更悲观[16]。虽然这些方法比普通的RL方法获得了显著的性能提升,但它们要么需要对行为策略进行估计,要么需要从OOD数据点进行显式采样,而这本身可能很难解决。此外,这些方法没有利用Q函数网络的泛化能力,并且在不考虑它们是好是坏的情况下禁止智能体接近任何OOD状态动作。然而,如果我们能够识别OOD数据点,在这些数据点中我们可以以高置信度预测它们的Q值,那么不限制智能体选择这些数据点更有效。根据这种直觉,我们提出了一种基于不确定性的无模型离线RL方法,该方法通过Q函数网络的集合有效地量化Q值估计的不确定性,并且不需要对数据分布进行任何估计或采样。为了实现这一点,我们首先展示了在线RL中的一种众所周知的技术,即限幅Q学习[10],可以成功地用作基于不确定性的惩罚项。我们的实验表明,仅通过增加集成大小,我们就可以在各种离线RL任务上实现最先进的性能。为了进一步提高该方法的实用性,我们开发了一个集成多样化目标,该目标显著减少了所需的集成网络的数量。我们在D4RL基准上评估了我们提出的方法[9],并验证了所提出的方法在各种类型的环境和数据集上大大优于先前的最新技术。