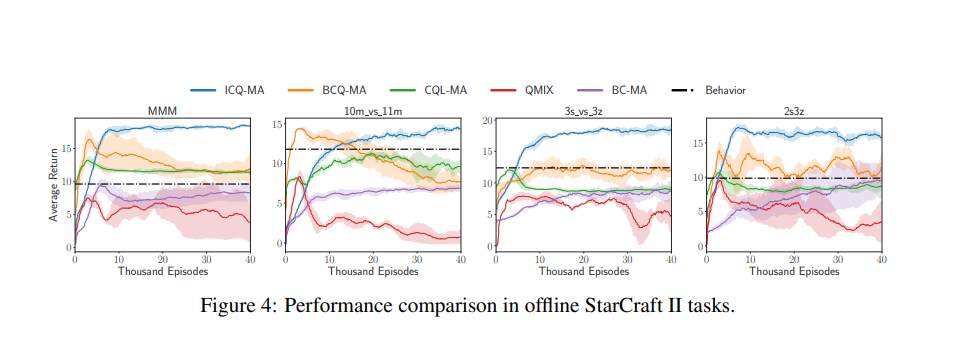
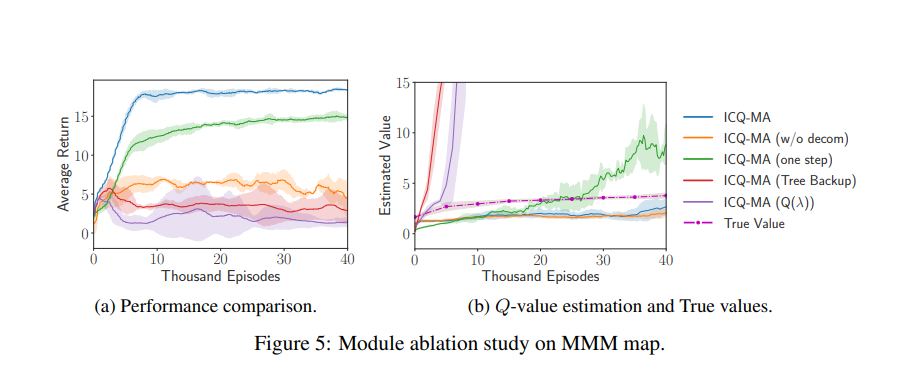
在不与环境交互的情况下从数据集学习(离线学习)是在真实世界场景中应用强化学习(RL)算法的重要步骤。然而,与单智能体对应物相比,离线多智能体RL引入了更多具有更大状态和动作空间的智能体,这更具挑战性,但很少引起关注。我们证明,由于累积的外推误差,当前的离线RL算法在多智能体系统中是无效的。在本文中,我们提出了一种新的离线RL算法,名为隐式约束Q学习(ICQ),该算法通过仅信任数据集中给出的状态-动作对进行值估计,有效地减轻了外推误差。此外,我们通过在隐式约束下分解联合策略,将ICQ扩展到多agent任务。实验结果表明,外推误差成功地控制在合理的范围内,并且对智能体的数量不敏感。我们进一步表明,ICQ在具有挑战性的多智能体离线任务(星际争霸II)中实现了最先进的性能。

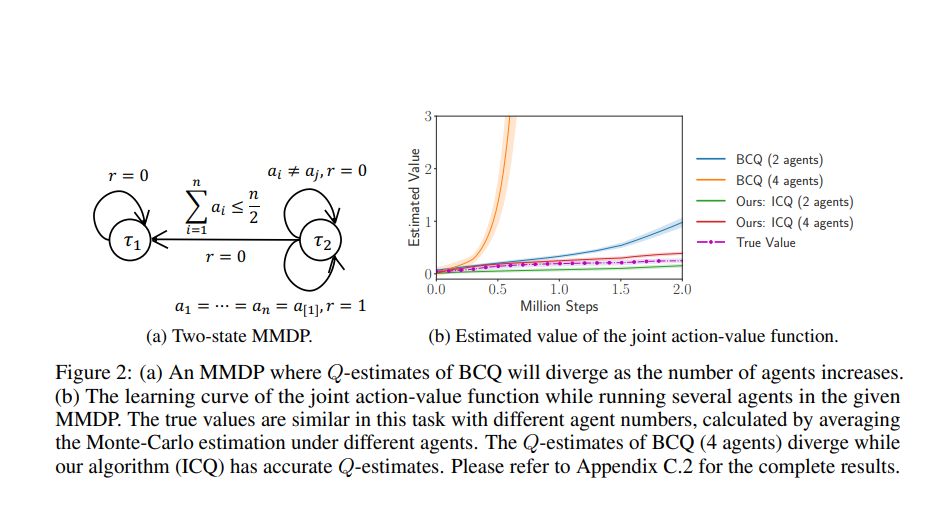
最近,强化学习(RL)这一主动学习过程在从战略游戏[59]到推荐系统[8]的各个领域取得了巨大成功。然而,将RL应用于现实世界场景带来了实际挑战:与现实世界的交互,如自动驾驶,通常是昂贵或风险的。为了解决这些问题,离线RL是处理实际问题的最佳选择[3,24,35,42,15,28,4,23,54,12],旨在从固定数据集学习而不与环境交互。离线RL的最大障碍是分布偏移问题[16],这会导致外推误差,这是一种错误估计未看到的状态动作对的现象。与在线设置不同的是,无法通过与环境交互来校正看不见的对的不准确估计值。因此,由于难以解决的过度泛化,大多数非策略RL算法在离线任务中失败。现代离线方法(例如,批量约束深度Q学习(BCQ)[16])旨在强制学习策略接近行为策略或直接抑制Q值。这些方法在挑战D4RL等单智能体离线任务方面取得了巨大成功[14]。然而,现实世界场景中的许多决策过程属于多智能体系统,如智能交通系统[2]、传感器网络[37]和电网[7]。与单智能体系统相比,多智能体系统具有更大的行动空间,随着智能体数量的增加,行动空间呈指数增长。当进入离线场景时,看不见的状态动作对将随着智能体数量的增加而呈指数增长,从而快速累积外推误差。当前的离线算法在多智能体任务中不成功,尽管它们采用了现代价值分解结构[26,48,25]。如图2所示,我们的结果表明,BCQ,一种最先进的离线算法,在简单的多智能体MDP环境(例如,BCQ(4个智能体))中具有发散的Q估计。随着智能体数量的增加,值估计的外推误差会迅速累积,从而显著降低性能。基于这些分析,我们提出了隐式约束Q学习(ICQ)算法,该算法有效地减轻了外推误差,因为在估计Q值时不涉及未发现的对。受隐式约束优化问题的激励,ICQ采用类似SARSA的方法[49]来评估Q值,然后将策略学习转化为监督回归问题。通过在隐式约束下分解联合策略,我们成功地将ICQ扩展到多agent任务。据我们所知,我们的工作是第一次分析和解决多智能体强化学习中的外推错误的研究。我们基于星际争霸II[40]评估了我们在具有挑战性的多智能体离线任务上的算法,其中大量智能体协同完成任务。实验结果表明,ICQ可以在任意数量的智能体下将外推误差控制在合理范围内,并从复杂的多智能体数据集中学习。此外,我们在D4RL中评估了ICQ的单智能体版本,这是一个标准的单智能体离线基准测试。结果证明了ICQ在从单智能体到多智能体、从离散控制到连续控制的广泛任务场景中的通用性。