在强化学习(RL)中有效利用以前收集的大型数据集是大规模现实应用的关键挑战。离线RL算法承诺从以前收集的静态数据集中学习有效的策略,而无需进一步交互。然而,在实践中,离线RL是一个重大挑战,标准的非策略RL方法可能会失败,因为数据集和学习策略之间的分布变化导致的值的高估,尤其是在复杂和多模式数据分布的训练中。在本文中,我们提出了保守Q学习(CQL),其目的是通过学习保守Q函数来解决这些限制,使得在该Q函数下策略的期望值低于其真实值。我们从理论上证明了CQL在当前策略的值上产生了一个下限,并且它可以被纳入到具有理论改进保证的策略学习过程中。在实践中,CQL使用一个简单的Q值正则化器来增强标准的Bellman误差目标,该正则化器可以在现有的深度Q学习和演员-评论家实现的基础上直接实现。在离散和连续控制域上,我们表明CQL大大优于现有的离线RL方法,通常学习策略的最终回报率高2-5倍,尤其是在从复杂和多模态数据分布中学习时。


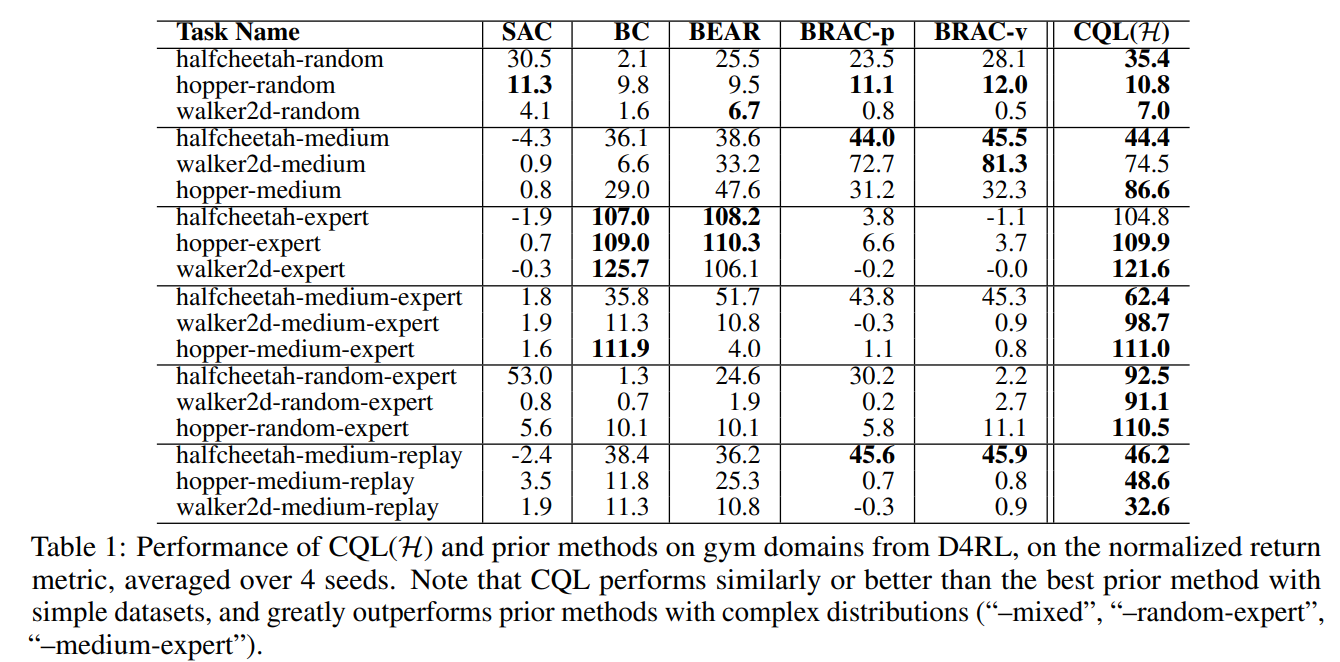
强化学习(RL)的最新进展,尤其是与表达型深度网络函数逼近器相结合时,在机器人[29]、策略游戏[4]和推荐系统[35]等领域产生了有希望的结果。然而,将RL应用于现实问题始终会带来实际挑战:与在监督学习中取得成功的数据驱动方法不同[22,10],RL通常被视为一个主动学习过程,其中每次训练运行都需要与环境进行积极互动。与现实世界的交互可能成本高昂且危险,在线收集的数据量远低于监督学习中使用的离线数据集[9],而离线数据集只需要收集一次。离线RL,也称为批量RL,提供了一种极具吸引力的替代方案[11,15,30,3,27,54,34]。离线RL算法从以前收集的大型数据集学习,无需交互。原则上,这可以使利用大型数据集成为可能,但在实践中,完全离线的RL方法带来了重大的技术困难,这源于收集数据的策略和学习到的策略之间的分布变化。这使得目前的结果与此类方法的全部承诺相去甚远。在离线设置中直接使用现有的基于值的非策略RL算法通常会导致性能不佳,这是由于分布外行为的自举问题[30,15]和过拟合问题[13,30,3]。这通常表现为错误的乐观值函数估计。如果我们可以学习值函数的保守估计,它提供了真实值的下限,那么这个高估问题就可以得到解决。事实上,由于政策评估和改进通常只使用政策的值,因此我们可以学习一个不太保守的Q函数下界,使得只有政策下Q函数的期望值是下界,而不是逐点的下界。我们提出了一种通过对基于标准值的RL算法进行简单修改来学习这种保守Q函数的新方法。我们的方法背后的关键思想是在适当选择的状态动作元组分布下最小化值,然后通过在数据分布上加入最大化项来进一步收紧这个界限。我们的主要贡献是一个算法框架,我们称之为保守Q学习(CQL),通过在训练期间正则化Q值来学习值函数的保守下限估计。我们对CQL的理论分析表明,只有该Q函数在策略下界下的期望值才是真实的策略值,防止了点式下界Q函数可能出现的额外低估,这在探索文献[46,26]中通常在相反的背景下进行了探索。我们还通过经验证明了我们的方法对Q函数估计误差的鲁棒性。我们的实际算法将这些保守估计用于策略评估和离线RL。只需将CQL正则化项添加到Q函数更新中,CQL就可以在许多标准的在线RL算法[19,8]之上用不到20行代码来实现。在我们的实验中,我们证明了CQL对离线RL的有效性,在具有复杂数据集组成的域中,其中已知现有方法通常表现不佳[12],在具有高维视觉输入的域中[5,3]。在许多基准任务中,CQL的性能比以前的方法高达2-5倍,是唯一一种可以在从人类交互中收集的大量真实数据集上优于简单行为克隆的方法。