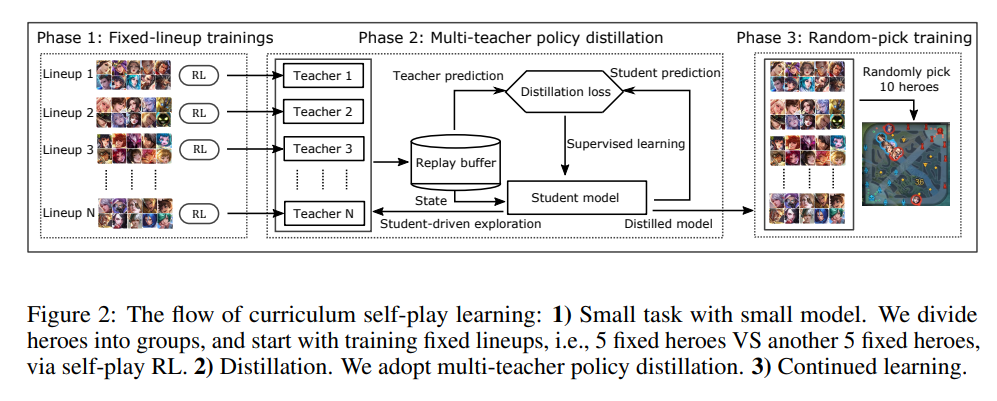
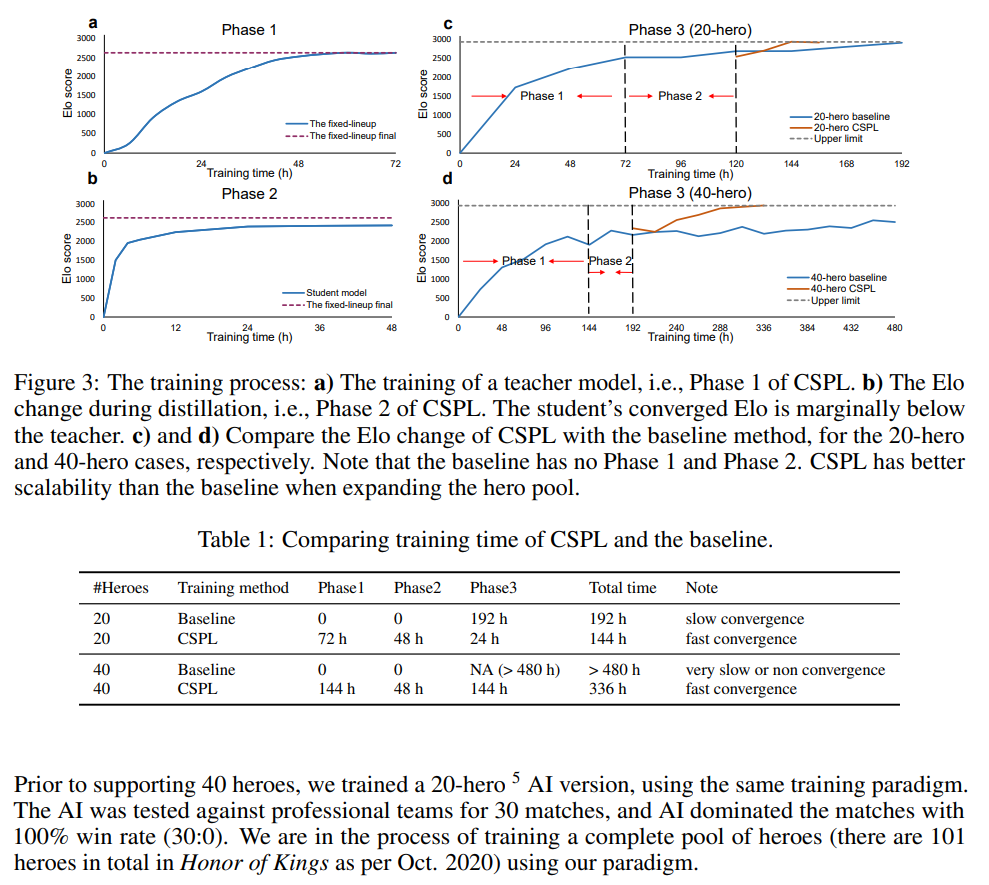
MOBA游戏,如《王者荣耀》、《英雄联盟》和《Dota 2》,对人工智能系统提出了巨大的挑战,如多智能体、巨大的状态动作空间、复杂的动作控制等。因此,开发用于玩MOBA游戏的人工智能引起了广泛关注。然而,在OpenAI的Dota AI将游戏限制在只有17个英雄的情况下,在扩展英雄池时,现有的工作在处理智能体组合(即阵容)爆炸导致的原始游戏复杂性方面存在不足。因此,任何现有的人工智能系统都远远无法掌握无限制的完整MOBA游戏。在本文中,我们提出了一种MOBA AI学习范式,该范式在方法学上支持使用深度强化学习玩完整的MOBA游戏。具体而言,我们开发了一种新颖的和现有的学习技术,包括课程自学、策略蒸馏、非策略自适应、多头价值估计和蒙特卡罗树搜索,用于训练和扮演大量英雄,同时巧妙地解决可扩展性问题。在一款流行的MOBA游戏《王者荣耀》上进行了测试,我们展示了如何构建能够击败顶级电竞玩家的超人AI智能体。文献中首次大规模的MOBA AI智能体性能测试证明了我们的AI的优越性。

游戏人工智能,也称为游戏AI,几十年来一直在积极研究。我们已经见证了AI代理在许多游戏类型中的成功,包括围棋[30]、雅达利系列[21]等棋类游戏、《夺取旗帜》[15]等第一人称射击(FPS)游戏、《超级粉碎兄弟》[6]等电子游戏、扑克[3]等纸牌游戏,AlphaStar在玩通用实时战略(RTS)游戏《星际争霸2》时达到了大师级水平[33]。作为RTS游戏的一个子流派,多玩家在线战斗竞技场(MOBA)最近也备受关注[38,36,2]。由于MOBA的游戏机制涉及多主体竞争与合作、不完全信息、复杂的动作控制和巨大的状态动作空间,因此MOBA被认为是人工智能研究的首选试验台[29,25]。典型的MOBA游戏包括《王者荣耀》、《多塔》和《传奇联盟》。就复杂性而言,MOBA游戏,如《王者荣耀》,即使具有显著的离散化,其状态和动作空间也可能达到1020000[36],而传统游戏AI测试台,如围棋,其状态空间和动作空间最多为10360[30]。MOBA游戏因多个英雄的实时策略而变得更加复杂(每个英雄都被独特地设计为具有不同的游戏机制),特别是在5对5(5v5)模式下,两支队伍(每个队伍有5个从英雄池中选出的英雄)相互竞争1。尽管它适合AI研究,掌握MOBA的玩法仍然是当前人工智能系统面临的巨大挑战。MOBA 5v5游戏的最新作品是用于玩Dota 2的OpenAI Five[2]。它通过自我游戏强化学习(RL)进行训练。然而,OpenAI Five有一个主要限制2,即仅支持17个英雄,尽管英雄变化和团队变化的游戏机制是MOBA的灵魂[38,29]。作为玩完整MOBA游戏的最基本步骤,扩大英雄池对于自我强化学习来说是具有挑战性的,因为代理组合(即阵容)的数量随着英雄池的大小呈多项式增长。17名英雄的代理组合为4900896(C10 17×C5 10),40名英雄的代理人组合为213610453056(C10 40×C5 0)。考虑到每个MOBA英雄都是独一无二的,即使对于经验丰富的人类玩家也有学习曲线,通过将这些无序英雄组合随机呈现给学习系统的现有方法可能会导致“学习崩溃”[1],这已经从OpenAI Five[2]和我们的实验中观察到。例如,OpenAI试图将英雄池扩展到25个英雄,导致训练速度慢得令人无法接受,AI性能下降,甚至有数千个GPU(有关更多详细信息,请参见[24]中的“更多英雄”一节)。因此,我们需要MOBA AI学习方法来处理扩展英雄池导致的可扩展性相关问题。