为了提高基于策略梯度的强化学习算法的样本效率,我们提出了隐式分配行为体批评者(IDAC),它由一个基于两个深度生成器网络(DGN)的分配评论者和一个由灵活的策略分布支持的半隐式行为体(SIA)组成。我们对贴现累积收益采用分布观点,并用依赖于状态动作的隐式分布对其进行建模,该隐式分布由以状态动作对和随机噪声作为输入的DGN近似。此外,我们使用SIA来提供半隐式策略分布,它将策略参数与不受分析密度函数约束的可重新参数化分布混合。这样,政策的边际分布是隐式的,提供了对协方差结构和偏度等复杂属性建模的潜力,但其参数和熵仍然可以估计。我们将这些特性与非策略算法框架相结合,以解决具有连续动作空间的问题,并将IDAC与代表性OpenAI健身房环境中的最新算法进行比较。我们观察到,IDAC在大多数任务中都优于这些基线。提供了Python代码。



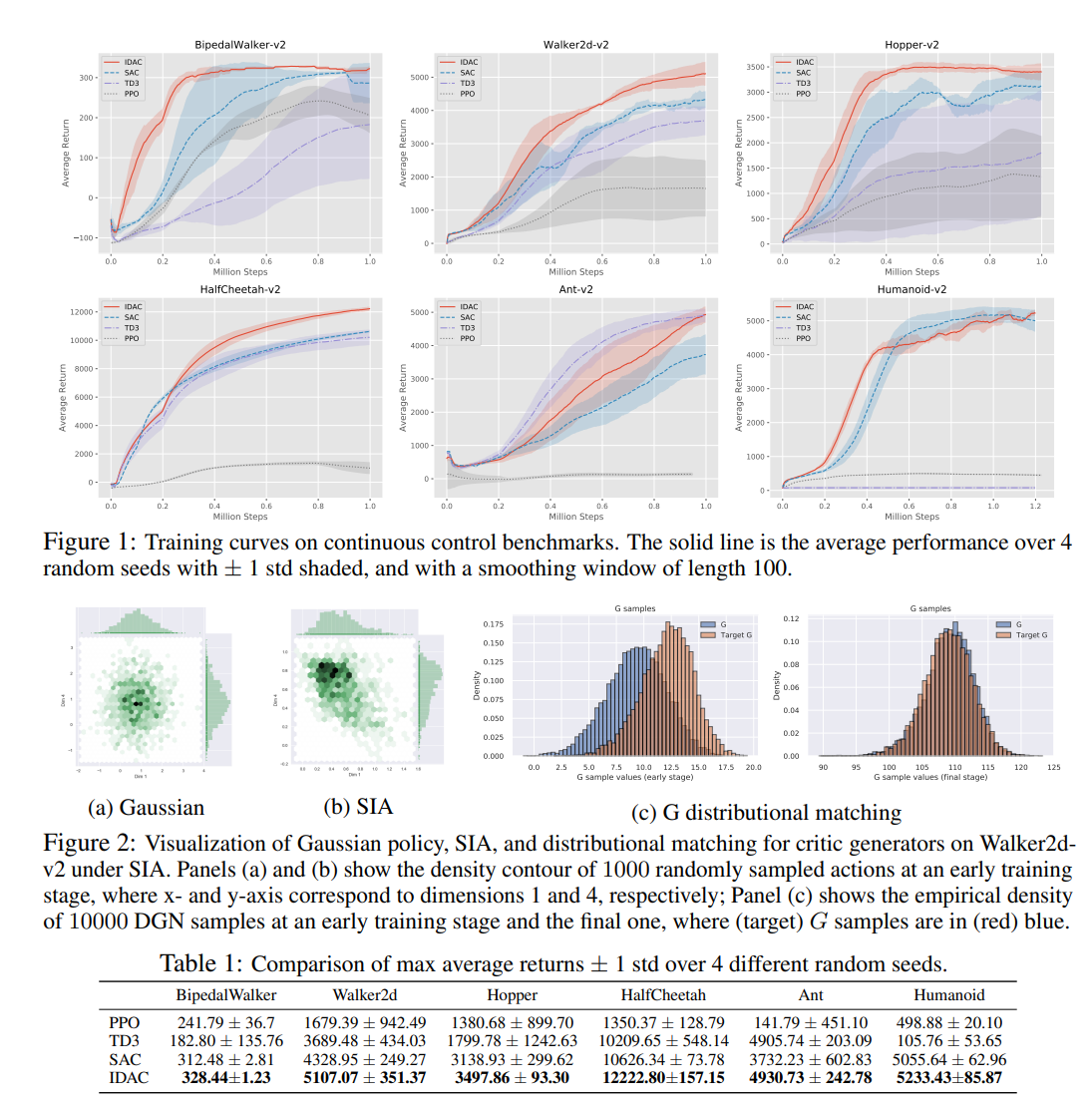
无模型强化学习(RL)在解决复杂的现实世界顺序决策任务中发挥着重要作用(MacAlpine和Stone,2017;Silver等人,2018;OpenAI,2018)。在深度神经网络的帮助下,无模型深度RL算法已成功地应用于各种任务,包括游戏(Silver等人,2016;Mnih等人,2013)和机器人控制(Levine等人,2016)。深度Q网络(DQN)(Mnih等人,2015年)使RL代理在Atari游戏上具有人类水平的性能(Bellemare等人,2013年),从而推动了许多后续工作的进一步改进(Wang等人,2016年;Andrychowicz等人,2017年)。Bellemare等人(2017a)提出的一个新想法是,对深层RL问题采取分布视角,该模型对所选行为在某一状态下的贴现累积回报率的完全分布进行建模,而不仅仅是对其期望值的建模,从而使模型能够捕捉其内在随机性,而不是一阶矩。具体而言,分布Bellman算子可以帮助捕获状态行为值分布中的偏斜性和多模态,这可能导致更稳定的学习过程,并且接近完全分布也可以减轻从非平稳政策中学习的挑战。在这种分布式框架下,Bellemare等人(2017a)提出了C51算法,该算法在一系列Atari游戏中优于之前最先进的基于Q学习的经典算法。然而,C51中的理论和实现之间存在一些差异,促使Dabney等人(2018b)引入QR-DQN,该方法借用了Wasserstein距离和分位数回归相关技术,以缩小理论与实践之间的差距。随后,分布式视图也被纳入了用于连续控制任务的深度确定性策略梯度(DDPG)框架(Lillicrap et al.,2015),产生了高效算法,如分布式分布式DDPG(D4PG)(Barth Maron等人,2018)和基于样本的分布式策略梯度(SDPG))(Singh等人,2020)。由于策略的确定性,这些算法总是在训练过程中手动将随机噪声添加到动作中,以避免陷入糟糕的局部最优。相比之下,随机策略将这种随机性作为策略的一部分,在训练过程中学习它,并实现最先进的性能,Haarnoja等人(2018)的软行为批评(SAC)算法就是一个成功的例子。受分配行动价值学习和随机政策的有前景的方向的激励,本文将这两个框架整合起来,希望使它们相互加强。我们使用深度生成网络(DGN)对一个状态下的行为的贴现累积回报率分布进行建模,该网络的输入由状态-行为对和随机噪声组成,并应用分布Bellman方程来更新其参数。DGN扮演分配评论家的角色,其对状态-动作对的输出条件遵循隐式分布。直观地说,仅对累积收益率的预期进行建模,就不可避免地会丢弃训练期间随时可用的有用信息,而对其完全分布进行建模可以捕获更多有用信息,以帮助更好地训练和稳定随机政策。换言之,用分布而不是期望来指导分布的训练有着巨大的潜在收益。对于随机策略,连续控制下的默认分布选择是对角高斯分布。然而,假设每个维度的单峰和对称密度以及不同维度之间的独立性使得它无法捕捉复杂的分布特性,如偏度、峰度、多峰和协方差结构。为了充分利用DGN建模的分配回报,我们因此提出了一种半隐式行为体(SIA)作为政策分布,它采用了半隐式层次结构(Yin和Zhou,2018),可以根据需要进行复杂化,同时通过随机梯度下降(SGD)进行优化。然而,在行动者-批评家政策梯度框架内,DGN(一种隐性的分配评论家)和SIA(一种半隐性的行动者)的天真组合只会带来平庸的表现,达不到预期的效果。我们将其成果不足归因于传统基于价值的算法中普遍存在的高估问题(Van Hasselt et al.,2016),该问题在分配环境下不会自动消失。受先前减轻深度Q学习中高估问题的工作启发(Fujimoto等人,2018),我们提出了一个基于双延迟DGN的批评者,利用该批评者,我们提供了一种新的解决方案,将目标值作为这两个DG的排序输出值的元素最小值