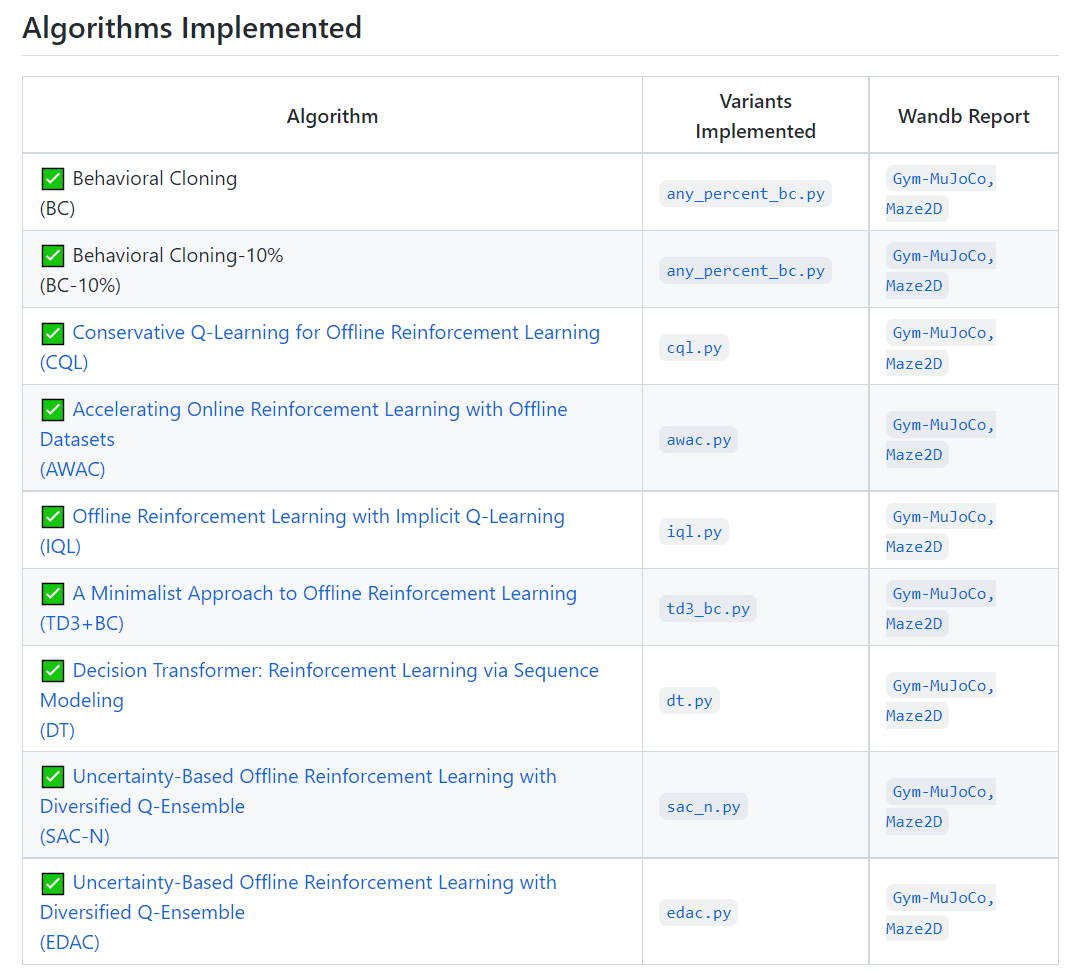
CORL是一个离线强化学习库,它提供高质量且易于遵循的SOTA ORL算法的单文件实现。每个实现都有一个便于研究的代码库支持,允许您运行或调整数千个实验。深受在线RL的clearl的启发,也来看看吧!


Citing CORL
If you use CORL in your work, please use the following bibtex
@inproceedings{
tarasov2022corl,
title={{CORL}: Research-oriented Deep Offline Reinforcement Learning Library},
author={Denis Tarasov and Alexander Nikulin and Dmitry Akimov and Vladislav Kurenkov and Sergey Kolesnikov},
booktitle={3rd Offline RL Workshop: Offline RL as a ''Launchpad''},
year={2022},
url={https://openreview.net/forum?id=SyAS49bBcv}
}