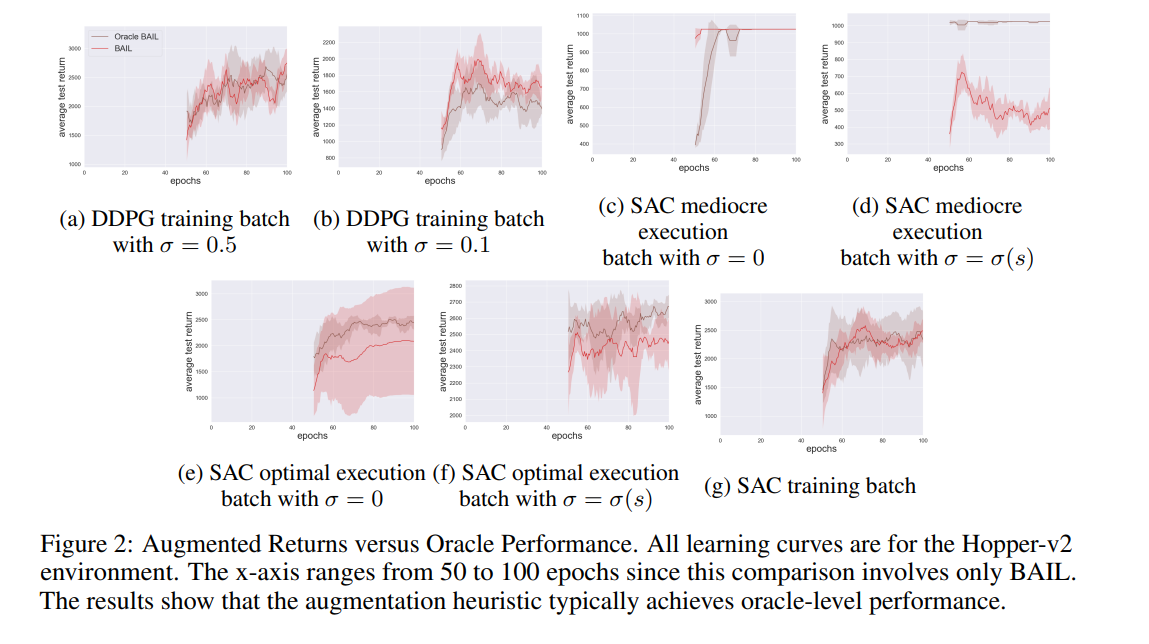
最近,离线深度强化学习(DRL)的研究激增,该研究旨在从给定数据集学习高性能策略,而不需要与环境进行额外交互。我们提出了一种新的算法,最佳动作模仿学习(BAIL),它力求简单和性能。BAIL学习一个V函数,使用V函数来选择它认为高性能的动作,然后使用这些动作来使用模仿学习来训练策略网络。对于MuJoCo基准测试,我们对BAIL进行了全面的实验研究,将其性能与其他四种批量Q学习和模拟学习方案进行了比较,以获得大量批量数据集。我们的实验表明,BAIL的性能远高于其他方案,并且在计算上也比批量Q学习方案快得多。


深度强化学习(DRL)领域最近出现了批量强化学习研究的激增,这是一个在不与环境进行额外交互的情况下从给定数据集进行样本高效学习的问题。Batch RL允许重用策略收集的数据,以可能改进策略,而无需与环境进行进一步交互,它有可能利用现有的大型数据集来获得更好的采样效率。批处理RL算法也可以作为增长批处理算法的一部分进行部署,其中批处理算法使用经验回放缓冲区中的数据来寻求高性能的利用策略[18],将该策略与探索相结合,以将新数据添加到缓冲区,然后重复整个过程[15,3]。批次RL对于学习安全关键系统中的策略也可能是必要的,在该系统中,部分培训的策略无法在线部署以收集数据。Fujimoto等人[8]进行了关键性观察,即当传统的基于Q函数的算法,如深度确定性策略梯度(DDPG)直接应用于批量强化学习时,它们学习非常差,甚至由于外推误差而完全偏离。因此,为了从批处理数据中获得高性能策略,需要新的算法。最近的批量DRL算法大致分为两类:基于Q函数的算法,如BCQ[8]和BEAR[14];以及基于模拟学习(IL)的算法,如MARWIL[27]和AWR[20]。我们提出了一种新的算法,最佳动作模仿学习(BAIL),它力求简单和性能。BAIL是一种先进的IL方法,其值估计仅用批次中的数据更新,给出稳定的估计。BAIL不仅提供了最先进的性能,而且计算速度也很快。此外,它在概念和算法上都很简单,从而满足了奥卡姆剃刀的原理。BAIL有三个步骤。在第一步中,BAIL通过训练神经网络来学习V函数,以获得“数据的上包络线”。在第二步中,它从数据集中选择Monte Carlo返回的接近上包络的状态-动作对。在最后一步中,它简单地使用所选的动作训练一个具有普通模仿学习的策略网络。因此,该方法将一种新的V学习方法与IL相结合。由于BCQ和BEAR代码是公开的,我们能够使用Mujoco基准对BAIL、BCQ、BEAR、MARWIL和香草行为克隆(BC)的性能进行仔细和全面的比较。对于我们的实验,我们以与BCQ论文中相同的方式创建训练批次(使用DDPG[17]创建批次),并使用SAC[10]为Ant和Humanoid环境添加额外的训练批次,总共22个训练批次包含非专家数据。我们的实验结果表明,BAIL在22个批次中的20个批次中获胜,总体性能比其他算法高42%或更多。此外,BAIL的计算速度比Q学习算法快30-50倍。因此,BAIL实现了最先进的性能,同时比BCQ和BEAR更简单、更快。总之,本文的贡献如下:(i)BAIL,一种新的高性能批量DRL算法,以及“数据的上包络”的新概念;(ii)广泛、精心设计的实验,在不同的数据集上比较五个批量DRL算法。计算结果为不同类型的批处理DRL算法如何对不同类型的数据集执行提供了重要的见解。我们为可再现性2提供公开的开源代码。我们还将公开我们的数据集,以便将来进行基准测试。