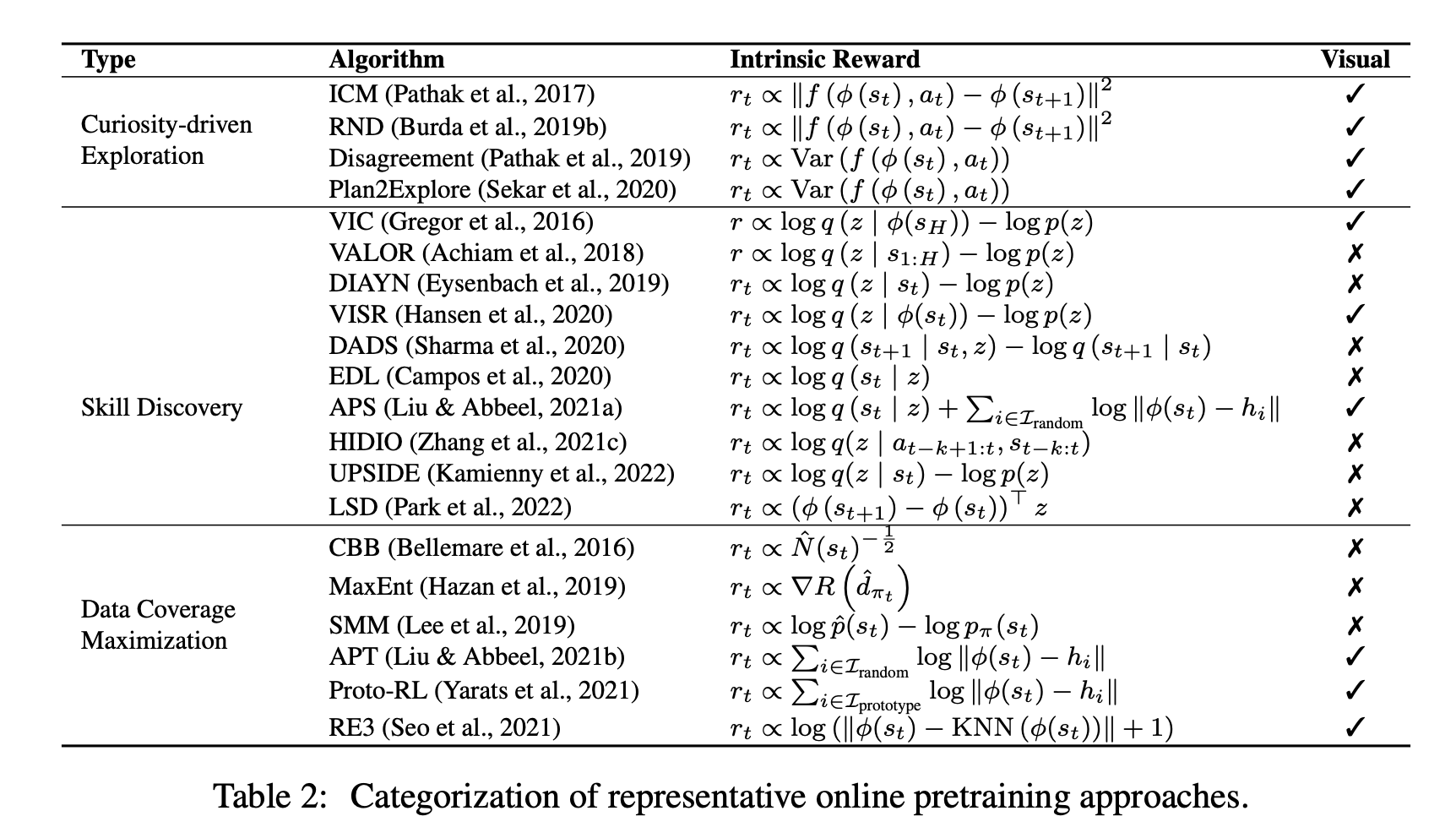
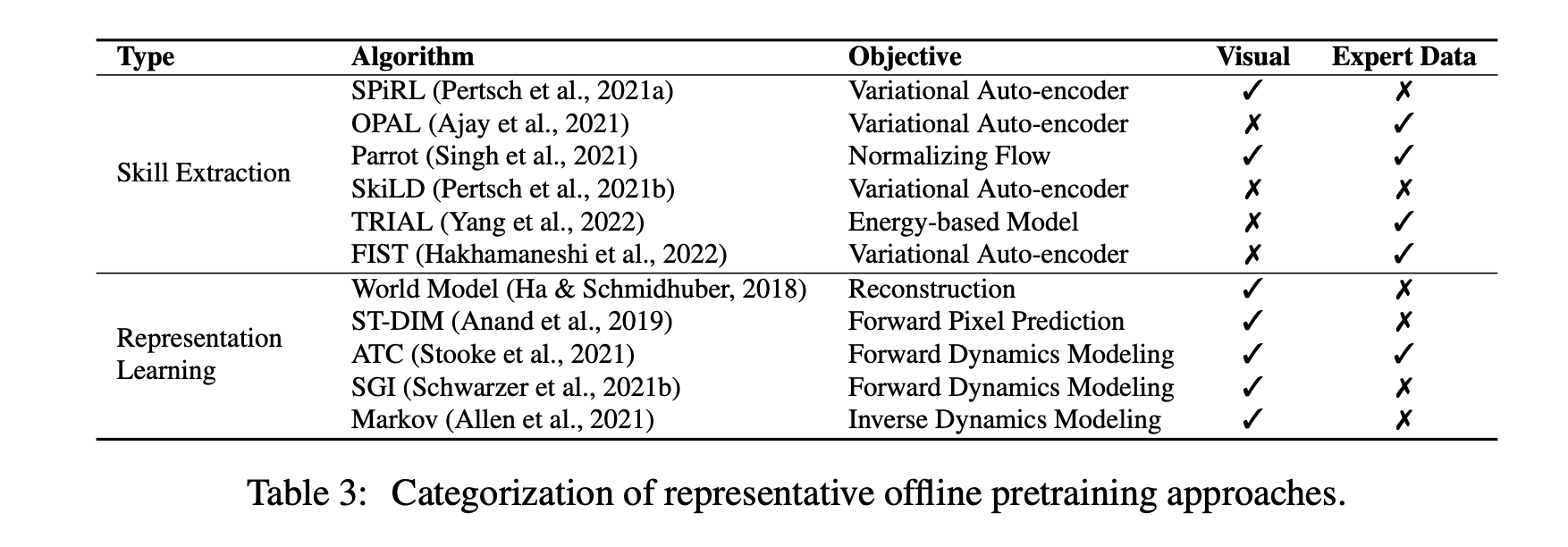
过去几年,强化学习(RL)与深度学习的结合取得了快速进展。从游戏到机器人的各种突破激发了人们对设计复杂RL算法和系统的兴趣。然而,RL中的主流工作流程是学习表格,这可能导致计算效率低下。这排除了RL算法的持续部署,并可能排除了没有大规模计算资源的研究人员。在机器学习的许多其他领域,预训练范式已证明在获取可用于各种下游任务的可转移知识方面是有效的。最近,我们看到了对深度RL预训练的兴趣激增,并取得了令人期待的结果。然而,许多研究都是基于不同的实验环境。由于RL的性质,该领域的预培训面临着独特的挑战,因此需要新的设计原则。在这项调查中,我们试图系统地回顾深度强化学习预训练的现有工作,提供这些方法的分类,讨论每个子领域,并关注开放问题和未来方向

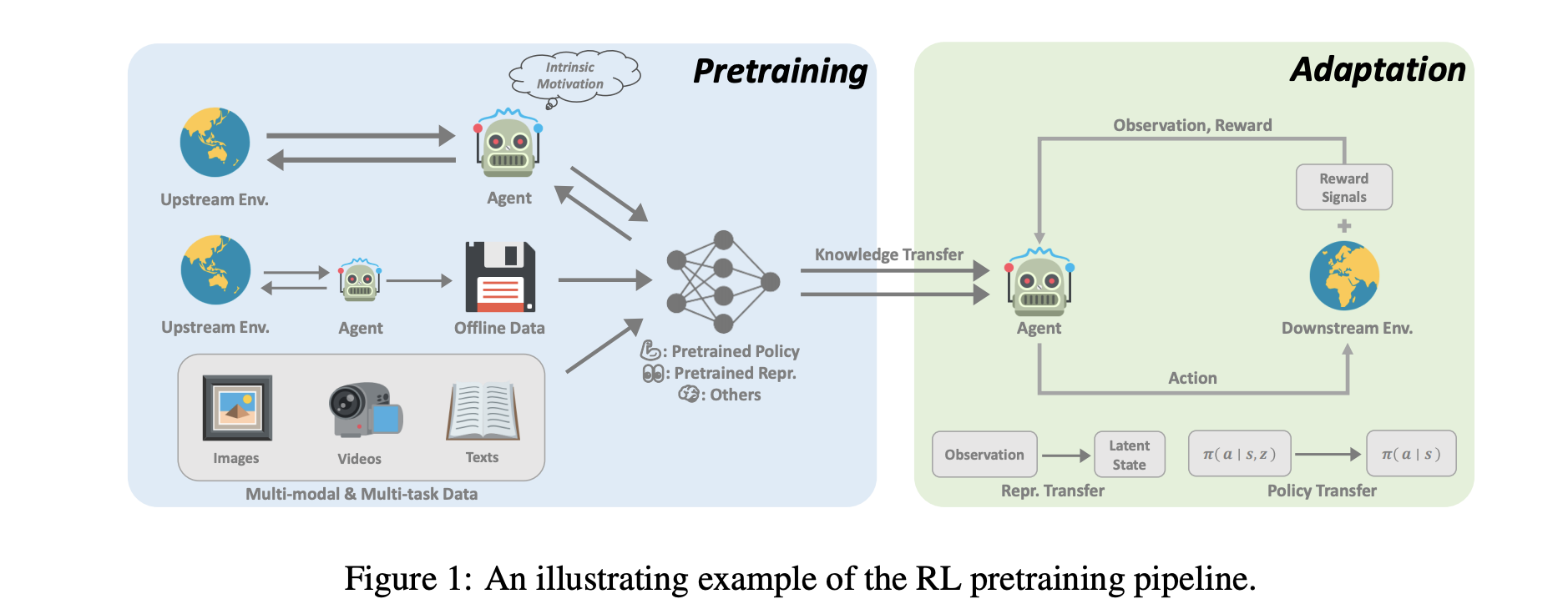
强化学习(RL)为顺序决策提供了一种通用数学形式(Sutton&Barto,2018)。通过将RL算法与深度神经网络结合使用,不同领域的各个里程碑通过以数据驱动的方式优化用户指定的奖励函数实现了超人的性能(Silver等人,2016;Akkaya等人,2019;Vinyals等人,2012019;Ye等人,2020、2020、2022;Chen等人,2021b)。因此,我们最近看到人们对这一研究方向越来越感兴趣。然而,尽管RL已被证明在解决明确指定的任务方面有效,但样本效率(Jin等人,2021)和泛化(Kirk等人,2021)的问题仍然阻碍了其在现实问题中的应用。在RL研究中,一个标准的范例是让主体从自己或他人收集的经验中学习,通常是在单个任务中学习,并通过随机初始化优化神经网络表格。相反,对人类来说,对世界的先验知识对决策过程有很大贡献。如果任务与以前看到的任务有关,人类往往会重复使用已经学到的东西,以快速适应新任务,而无需从头开始从详尽的交互中学习。因此,与人类相比,RL代理通常数据效率低下(Kapturowski等人,2022),并且容易过度拟合(Zhang等人,2018)。然而,机器学习的其他领域的最新进展积极倡导利用大规模预训练建立的先验知识。通过大规模的大数据训练,大型通用模型,也称为基础模型(Bommasani等人,2021),可以快速适应各种下游任务。这种预训练微调范式已被证明在计算机视觉(Chen等人,2020;He等人,2020年;Grill等人,2018年)和自然语言处理(Devlin等人,2019;Brown等人,2020)等领域有效。然而,预训练尚未对RL领域产生重大影响。尽管如此,大规模RL预训练的设计原则仍面临来自许多方面的挑战:1)领域和任务的多样性;2) 有限的数据来源;3) 快速适应以解决下游任务的困难。这些因素源于RL的性质,不可避免地需要考虑。这项调查旨在鸟瞰目前关于深RL预训练的研究。RL中的原则性预训练具有多种潜在益处。首先,RL训练产生的大量计算成本仍然是工业应用的一个障碍。例如,复制AlphaStar的结果(Vinyals等人,2019)大约需要数百万美元(Agarwal等人,2022)。预训练可以通过预训练的世界模型(Sekar等人,2020)或预训练的表示(Schwarzer等人,2021b)来改善这一问题,通过实现快速适应,以零或少量的方式解决任务。此外,RL是众所周知的任务和领域特定的。已经表明,使用大量任务不可知数据进行预训练可以增强这些类型的概括(Lee等人,2022)。最后,我们认为,使用适当的架构进行预训练可以释放缩放定律的力量(Kaplan等人,2020),正如最近在游戏中取得的成功所示(Schwarzer等人,2021b;Lee等人,2022)。通过扩大通用模型并增加计算,我们能够进一步实现超人的结果,正如“痛苦的教训”(Sutton,2019)所教导的那样。