引入一个框架来创建可以理解人类指令并在开放式环境中执行操作的 AI 代理
人类行为是非常复杂的。即使是像“把球靠近禁区”这样的简单要求,仍然需要深刻理解位置的意图和语言。像“关闭”这样的词的含义可能很难确定——从技术上讲,将球放在盒子内可能是最接近的,但演讲者很可能希望将球放在盒子旁边。为了使一个人正确地根据请求采取行动,他们必须能够理解和判断情况和周围环境。
大多数人工智能(AI)研究人员现在认为,编写能够捕捉位置交互细微差别的计算机代码是不可能的。或者,现代机器学习(ML)研究人员专注于从数据中学习这些类型的交互。为了探索这些基于学习的方法,并快速构建能够理解人类指令并在开放式条件下安全地执行操作的代理,我们在视频游戏环境中创建了一个研究框架。
今天,我们发表了一篇论文和视频集,展示了我们在构建视频游戏AI方面的早期步骤,这些AI可以理解模糊的人类概念 - 因此,可以开始以自己的方式与人互动。
训练视频游戏AI的最新进展大多依赖于优化游戏的分数。星际争霸和Dota的强大AI代理使用计算机代码计算的明确输赢进行训练。我们不是优化游戏分数,而是要求人们自己发明任务并判断进度。
使用这种方法,我们开发了一种研究范式,使我们能够通过与人类的接地和开放式互动来改善代理行为。虽然仍处于起步阶段,但这种范式创建了可以实时聆听、交谈、提问、导航、搜索和检索、操作对象以及执行许多其他活动的代理。
该汇编显示了代理在人类参与者提出的任务之后的行为:

我们创建了一个虚拟的“剧场”,其中包含数百个可识别的物体和随机配置。该界面专为简单和安全的研究而设计,包括用于不受限制的通信的聊天。
在“剧场”学习
我们的框架始于人们与视频游戏世界中的其他人互动。使用模仿学习,我们向代理灌输了一套广泛但未经提炼的行为。这种“行为先验”对于实现可以被人类判断的交互至关重要。如果没有这个初始模仿阶段,代理是完全随机的,几乎不可能与之交互。人类对智能体行为的进一步判断以及通过强化学习(RL)优化这些判断会产生更好的代理,然后可以再次改进。
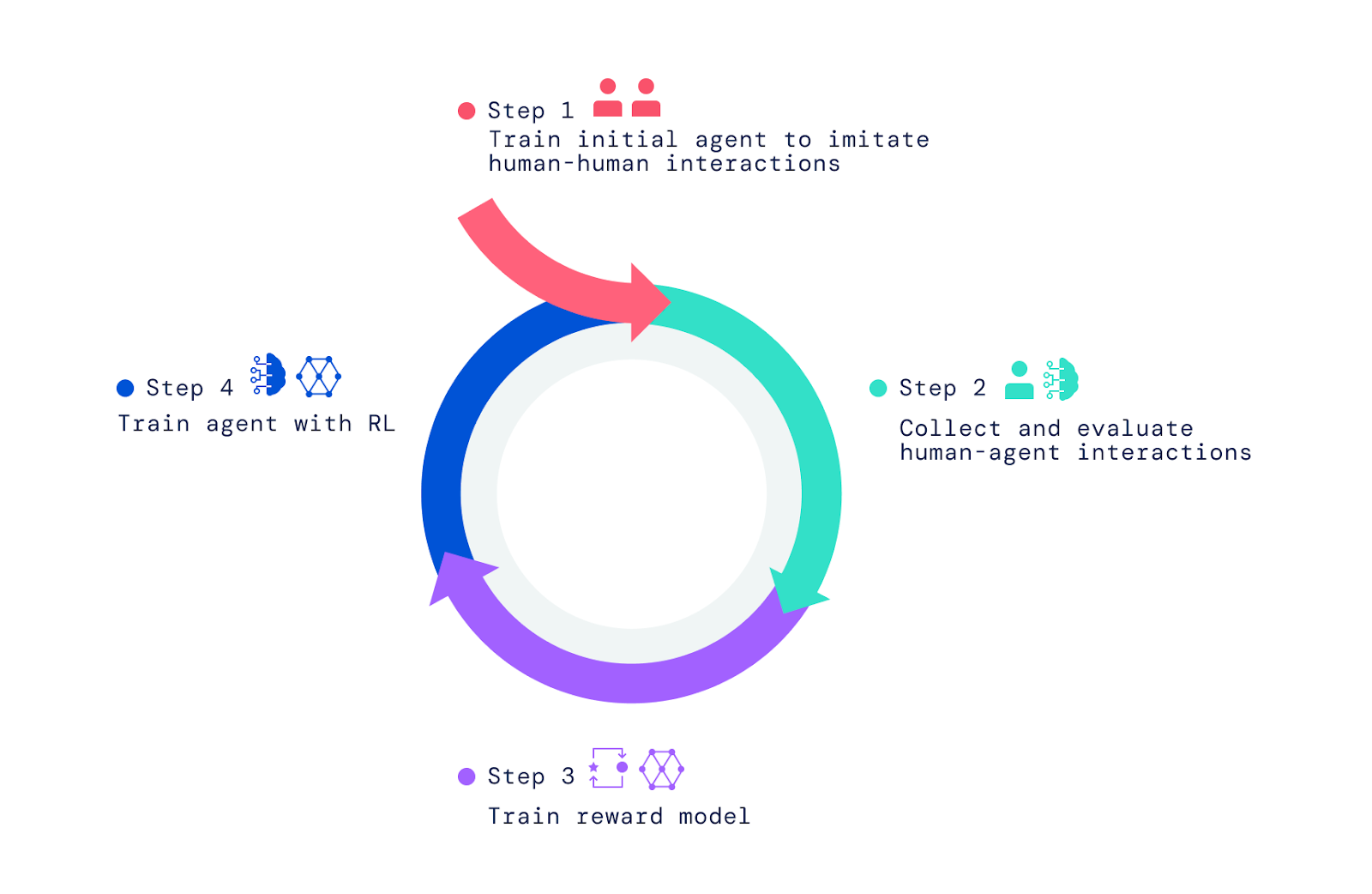
我们通过(1)模仿人与人的交互,然后通过(2)人与人的交互和人类反馈,(3)奖励模型训练和(4)强化学习的循环来改进代理。
首先,我们基于儿童“游戏屋”的概念构建了一个简单的视频游戏世界。此环境为人类和代理交互提供了安全设置,并可以轻松快速收集大量这些交互数据。这所房子的特点是各种房间、家具和物品,每次互动都以新的安排配置。我们还创建了一个交互界面。
人类和智能体在游戏中都有一个化身,使他们能够在环境中移动并操纵环境。他们还可以实时聊天并协作进行活动,例如携带物品并将它们交给对方,建造积木塔或一起打扫房间。人类参与者通过浏览世界、设定目标和向座席提问来设置交互的背景。总的来说,该项目收集了超过25年的代理和数百名(人类)参与者之间的实时交互。
观察出现的行为
我们训练的代理能够完成广泛的任务,其中一些是建造它们的研究人员没有预料到的。例如,我们发现这些代理可以使用两种交替的颜色构建一排对象,或者从与用户持有的另一个对象相似的房屋中检索对象。
之所以出现这些惊喜,是因为语言允许通过简单含义的组合来执行几乎无穷无尽的任务和问题。此外,作为研究人员,我们没有具体说明代理行为的细节。相反,参与互动的数百人在这些互动过程中提出了任务和问题。
构建用于创建这些代理的框架
为了创建我们的 AI 代理,我们应用了三个步骤。我们首先训练智能体模仿简单人际互动的基本要素,其中一个人要求另一个人做某事或回答一个问题。我们将这个阶段称为创建一个行为先验,使代理能够与人类进行高频率的有意义的互动。没有这个模仿阶段,代理只是随机移动并胡说八道。他们几乎不可能以任何合理的方式与之互动,给他们反馈就更加困难了。我们之前的两篇论文《模仿交互式智能》和《创建具有模仿和自监督学习的多模态交互式代理》中涵盖了这一阶段,该论文探讨了构建基于模仿的代理。
超越模仿学习
虽然模仿学习会带来有趣的互动,但它将互动的每一刻都视为同等重要。为了学习有效的、以目标为导向的行为,智能体需要追求目标,并在关键时刻掌握特定的动作和决策。例如,基于模仿的代理不能可靠地走捷径或执行任务,比普通人类玩家更灵巧。
在这里,我们展示了一个基于模仿学习的代理和一个基于RL的代理遵循相同的人类指令:
为了赋予我们的座席一种目标感,超越通过模仿实现的目标,我们依靠 RL,它使用反复试验与性能衡量相结合来迭代改进。当我们的代理尝试不同的操作时,那些提高性能的操作会得到加强,而那些降低性能的操作会受到惩罚。
在Atari,Dota,Go和StarCraft等游戏中,分数提供了需要改进的性能衡量标准。我们没有使用分数,而是要求人类评估情况并提供反馈,这有助于我们的代理学习奖励模型。
训练奖励模型和优化代理
为了训练奖励模型,我们要求人类判断他们是否观察到事件表明朝着当前指示的目标取得了显着进展,或者出现了明显的错误或错误。然后,我们将这些积极和消极的事件与积极和消极的偏好联系起来。由于它们发生在时间之外,我们称这些判断为“跨时间的”。我们训练了一个神经网络来预测这些人类偏好,并因此获得了反映人类反馈的奖励(或效用/评分)模型。
一旦我们使用人类偏好训练了奖励模型,我们就用它来优化代理。我们将代理放入模拟器,并指导他们回答问题并遵循说明。当他们在环境中行动和说话时,我们训练的奖励模型对他们的行为进行评分,我们使用 RL 算法来优化座席绩效。
那么任务说明和问题从何而来呢?为此,我们探索了两种方法。首先,我们回收了人类数据集中提出的任务和问题。其次,我们训练代理模仿人类设置任务和提出问题的方式,如本视频所示,其中两个代理,一个被训练模仿人类设置任务和提出问题(蓝色),一个训练遵循指示和回答问题(黄色),相互交互:
评估和迭代以继续改进代理
我们使用各种独立的机制来评估我们的代理,从手工脚本测试到对人们创建的开放式任务进行离线人工评分的新机制,这是我们之前的工作评估多模态交互式代理中开发的。重要的是,我们要求人们与我们的座席实时互动并判断他们的表现。我们由RL培训的代理比仅通过模仿学习培训的代理表现要好得多。
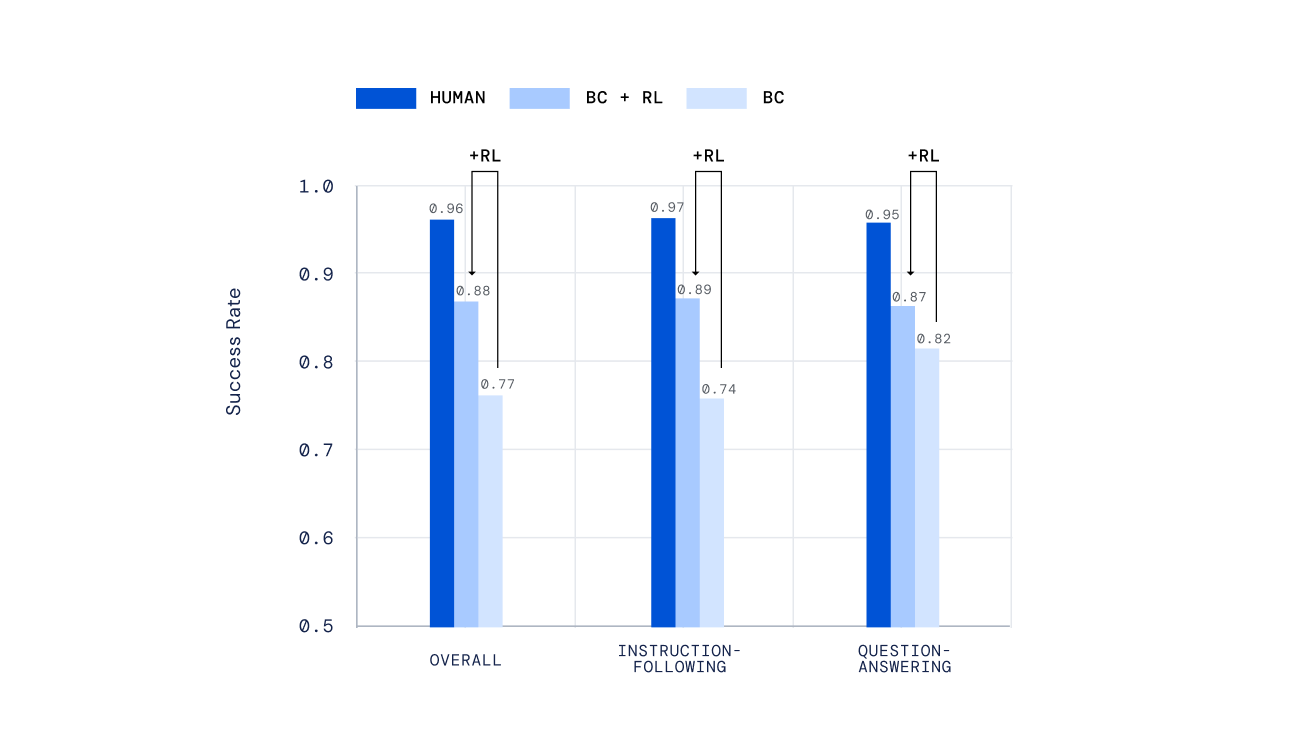
我们要求人们在在线实时互动中评估我们的座席。人类给出指令或问题5分钟,并判断代理的成功。通过使用RL,与单独的模仿学习相比,我们的代理获得了更高的成功率,在类似条件下实现了人类92%的表现。
最后,最近的实验表明,我们可以迭代强化学习过程,以反复改善代理行为。一旦代理通过RL进行了培训,我们要求人们与这个新代理进行交互,注释其行为,更新我们的奖励模型,然后执行RL的另一次迭代。这种方法的结果是越来越有能力的代理人。对于某些类型的复杂指令,我们甚至可以创建平均表现优于人类玩家的代理。
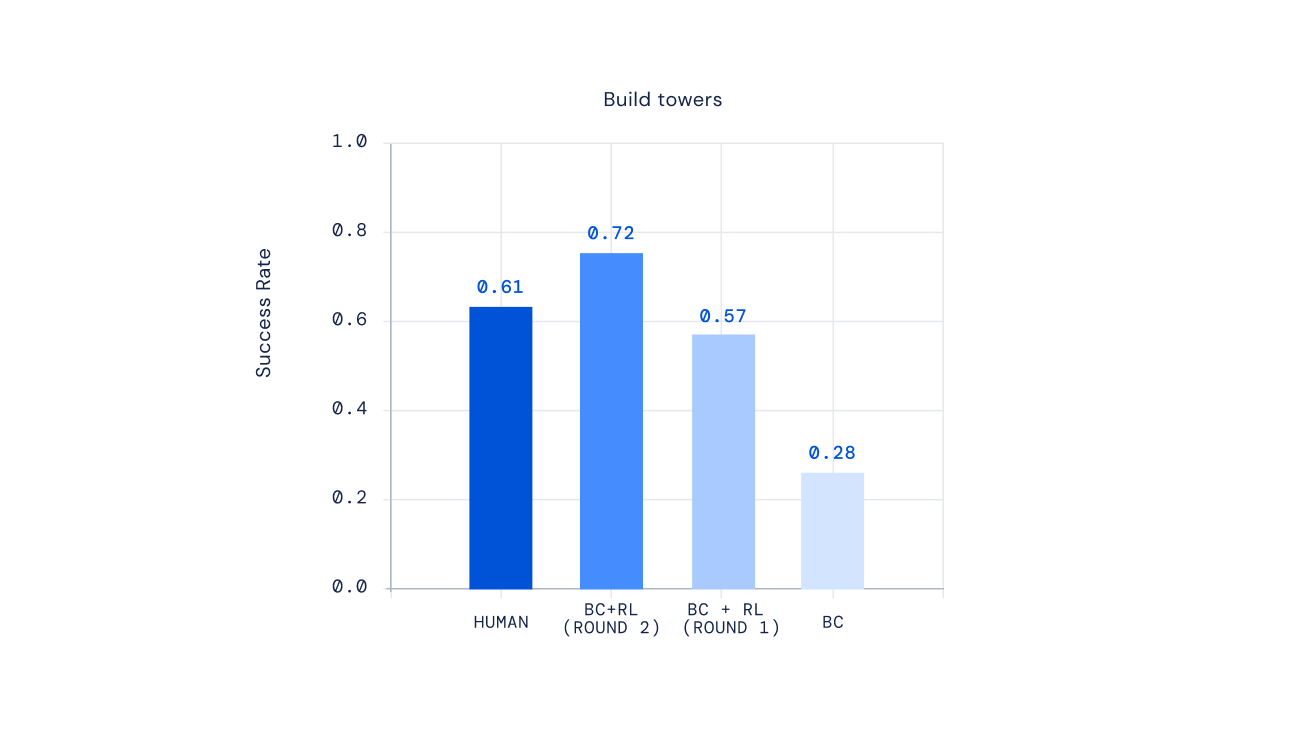
我们迭代了人类反馈和RL循环来讨论建造塔楼的问题。仿制品的性能明显比人类差。连续几轮的反馈和强化学习比人类更频繁地解决塔楼建造问题。
根据人类偏好训练 AI 的未来
使用人类偏好作为奖励来训练人工智能的想法已经存在了很长时间。在从人类偏好中进行深度强化学习中,研究人员开创了将基于神经网络的代理与人类偏好保持一致的最新方法。最近开发回合制对话代理的工作从人类反馈中探索了类似的想法,用于使用 RL 培训助手。我们的研究已经调整和扩展了这些想法,以构建灵活的AI,可以掌握广泛的多模式,具体,与人的实时交互。
我们希望我们的框架有朝一日能够创造出能够响应我们自然表达的意思的游戏AI,而不是依赖于手工编写的行为计划。我们的框架也可用于构建数字和机器人助手,供人们每天与之互动。我们期待探索应用该框架元素来创建真正有用的安全 AI 的可能性。