
本文将首先介绍 ETH 在四足机器人领域的标志性成果(分别发表在 Science Robotics 2020 和 2022),随后介绍强化学习在四足机器人领域的最新成果。
ETH 2020 — Learning Quadrupedal Locomotion over Challenging Terrain
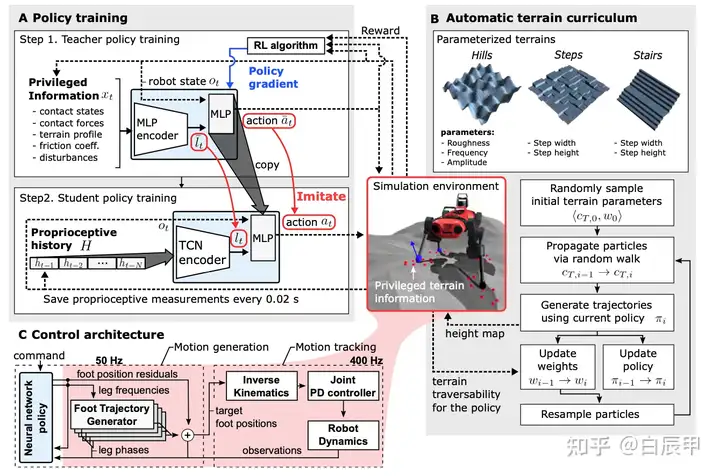
这篇工作的主要特点是仅利用了四足机器人的本体信息(proprioceptive feedback),使用强化学习进行仿真环境训练和 zero-shot 的 sim-to-real 真实环境迁移,得到了能够在许多 challenging terrain 上成功的行走策略。
本文的主要贡献包括以下几个部分。
Domain Randomization & Adaptive Terrain Curriculum
之前的许多工作需要对真实物理环境的状态转移进行准确建模,而这一建模往往是很难的。本文使用了domain randomization 的方法来对模拟器中的物理参数进行 randomize,从而使策略能够更加容易的从仿真器到真实世界中进行迁移。另外在训练中使用了 Adaptive Terrain Curriculum,逐步的改变四足训练的地形参数,从简单的地形开始来使四足不断学习到新的技能,并泛化到新的环境中。
Privileged Learning
直接从真实环境信息中训练策略是不可行的,原因是(1)真实环境中噪声很大;(2)真实环境中无法获得地形信息的真值。特别的,本文的假设是只利用本体信息,不使用视觉和雷达(Blind Setting)。
Privileged Learning 将四足的训练过程分为两个部分:
在第一阶段,使用仿真器中能够获得 Ground Truth 信息训练一个 Teacher Policy。由于该策略在使用完美信息的情况下进行训练,故而能够在很快的时间内达到一个很好的水平。然而,该策略并不能用于真实环境,原因是真实环境下无法获得这些 Ground Truth 信息。在本文中,Ground Truth 信息包括四足周围的地面高度图,contact信息和四足本体信息。Teacher 策略使用 TRPO 策略梯度法进行训练。
在第二阶段,使用 teacher forcing 的方法训练一个 student 策略,其中 student 策略只能获得四足在实际中使用的本体信息。在相同状态下,student 策略使用本体信息作为输入,而对应的 teacher策略使用 gound truth 作为输入;student 的损失函数设定为模仿 teacher 的动作,使用监督学习的方法进行训练。
Student策略使用 Temporal Convolution Network (TCN)网络。使用时序卷积网络TCN来对历史信息进行处理,从而能够获得更长时间的历史信息。特别的,TCN 能够从历史信息中推断 contact 和 slip 的有关信息。
附上文中关于整体结构的细节图。
ETH 2022 — Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild
这篇工作和上一篇工作的主要区别在于使用了感知信息(视觉、雷达)使四足能够获得更加完备的信息。
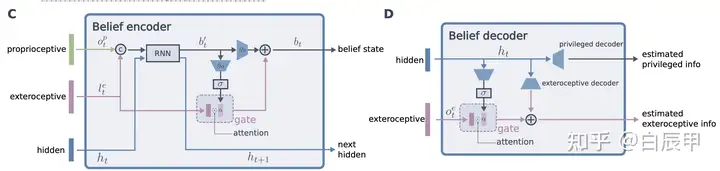
Attention-based Recurrent Encoder
提出了一个基于attention机制的 belief state encoder,可以融合感知信息和本体信息,同时可以对未来进行一定的推断。例如,智能体在通过下图的软体材质时,belief 编码器会记录这一信息,并在后面时间步的推断中修改对地形信息的估计。

Privileged Learning
在学习上仍然沿用了上一篇的做法,首先在仿真环境中利用完备的感知信息和本体信息,基于强化学习算法训练一个 teacher 策略。随后 student 使用 belief state encoder 作为状态信息的编码,使用 teacher 策略产生的动作作为监督信息,通过策略蒸馏得到 student 策略。belief state 的优势是能够通过历史信息推断智能体所看不到的部分信息,从而解决部分可观测的问题。在实际训练中,本文方法也使用了其他的技巧,例如 curriculum Learning, randomization 等。下图显示了 belief encoder 的具体结构,encoder-decoder 的结构在策略蒸馏损失的基础上,额外的给出了 reconstruction 的损失,可以用于加速学习 belief state。
下面介绍近期其他的四足相关工作。
1. Model-Free RL Methods
Learning to Walk in Minutes Using Massively Parallel DRL. CoRL 2022
https://leggedrobotics.github.io/legged_gym/leggedrobotics.github.io/legged_gym/
利用NVIDIA设计的并行仿真环境,可以支持数千个机器人同时的在线训练,从而在很短的时间内学习到稳定的策略,并通过sim-to-real将策略迁移到真实的环境中。

主要的设计点包括:
算法可以适用于不同的四足:ANYmal B, ANYmal C with an attached arm, and the Unitree A1 robots
Curriculum Learning: 在训练中包含了不同的地面情况,如flat, sloped, randomly rough, discrete obstacles, and stairs等,在训练中,从简单的地形开始训练,随后扩展到复杂的地形,例如提升台阶的高度(5cm~20cm)。
RL Formulation: 状态空间(base linear and angular velocities, measurement of the gravity vector, joint positions and velocities, the previous actions selected by the policy, and finally, 108 measurements of the terrain sampled from a grid around the robot’s base)动作空间(desired joint positions sent to the motors,then a PD controller produces motor torque)。
奖励设计:(1)达到固定方向的速度 follow the commanded velocities,同时避免其他方向的速度;(2)penalize joint torques, joint accelerations, joint target changes (3)避免碰撞:通过检测 contacts with the knees, shanks or between the feet and a vertical surface. (4)其他:encouraging the robot to take longer steps。
Sim-to-Real: 使用 domain randomlization,包括地面摩擦力,状态噪声,机器人在周期的初始位置等
Learning to walk in 20 minutes. 2208.07860
https://sites.google.com/berkeley.edu/walk-in-the-parksites.google.com/berkeley.edu/walk-in-the-park
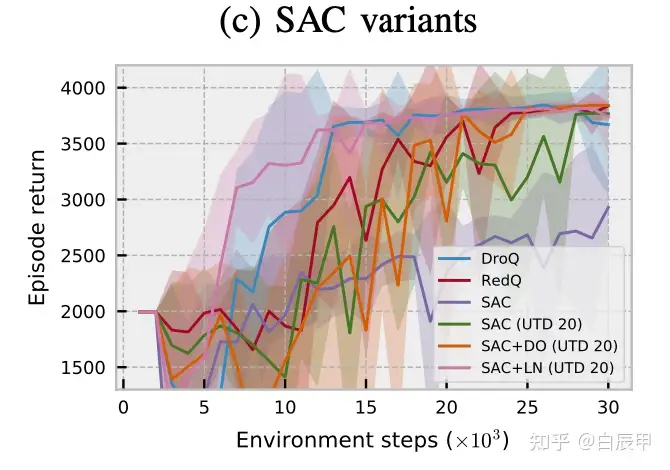
在与实际的环境交互中进行,主要解决的问题是样本利用效率。在RL更新中对应的问题是保持一个较高的 update-to-data (UTD) 值,需要使用REDQ模型。
单纯的增加UTD值对效果的提升有限,研究表明应当在 critic 更新时施加约束,包括:
Ensemble critic,e.g., REDQ 模型包含了一个较大的ensemble Q函数,在更新时随机选取一部分ensemble元素进行更新(SAC-style)。更多的Q函数为学习提供了更好的约束。
DroQ中含有的可行的约束包括 Layer normalization 和 Dropout 等。
实验表明这些约束能够很好的提升性能:
Walk These Ways: Gait-conditioned Policies Yield Diversified Quadrupedal Agility. CoRL 2022
Walk These Wayssites.google.com/view/gait-conditioned-rl/
本文在第一个工作的基础上增加了对步态的控制,包括 trotting, pronking, pacing, and bounding 等几种步态,需要通过配套的视频来感受不同的步态。在运动中,步态相当于一个condition,在步态控制的基础上使用强化学习设置奖励函数来使得四足机器人在满足步态要求的同时,具有一定的行进速度和稳定控制能力。
在步态控制方面,每两对脚运动的 timing offsets 可以进行区分。由于一共有四个脚,两两的组合一共有三种,可以表示为一个三元组。在静止状态下,每两对脚之间的 timing 都为0。(1)当三元组为(0.5, 0, 0)时表示trotting 的步态,对角线的脚部关节交替接触。(2)当三元组为(0, 0.5, 0)时表示 pacing 的步态,左侧和右侧的脚部关节交替接触。(3)当三元组为(0, 0, 0.5)时表示 bounding 的步态,前侧和后侧的脚部关节交替接触。在训练中,使用奖励函数来使智能体达到预期的步态控制。同时,其他的奖励函数包括:使四足运动达到预定的速度,使四足运动具有稳定性和平稳性等。算法使用PPO进行训练,随后进行zero-shot的迁移。

2. Model-based RL Methods
DayDreamer: World Models for Physical Robot Learning. CoRL 2022
DayDreamer: World Models for Physical Robot Learningdanijar.com/project/daydreamer/
本文使用model-based的方法,在多个四足和机械臂任务中进行学习,使用实物直接与环境的交互中学习而不依赖于模拟器,学习非常高效。本文使用的学习环境包括
Dreamer to solve a range of tasks on different robots from scratch in the real world, all with the same hyper parameters and without simulators.
学习使用的是model-based领域的Dreamer算法,具体设计包括:
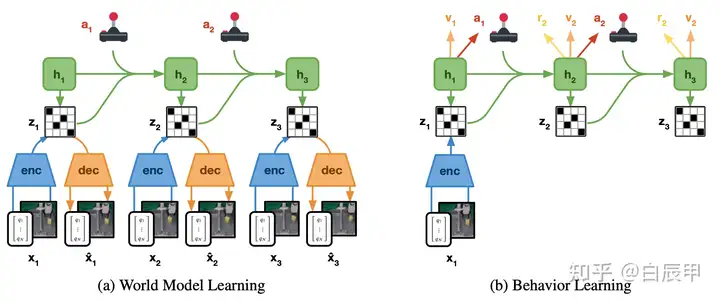
Recurrent state-space model (RSSM)
左图显示了环境模型构建的过程:
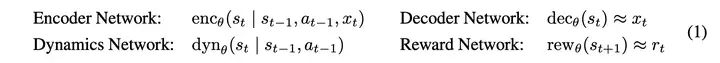
Recurrent state-space model (RSSM)
右图显示了策略学习的过程:
在环境模型中,根据当前的状态向后推演多个时间步,得到多步的隐空间状态
在隐空间中学习策略和值函数。其中,值函数拟合 Math input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input error$Math input error$ -return,使用 REINFORCE 算法或 Direct backpropagate算法进行训练。其中,REINFORCE将环境模型作为黑盒直接优化,而直接策略梯度利用了 RSSM 可微的性质。
在优化时使用了最大熵策略。
3. Vision-based RL Methods
Legged Locomotion in Challenging Terrains using Egocentric Vision. CoRL 2022 Oral
Legged Locomotion in Challenging Terrain using Egocentric Visionblindsupp.github.io/visual-walking/
该文章的特点是将训练分为了两个阶段,第一个阶段中利用了分辨率更低的高程图(elevation map)使用强化学习算法训练得到一个策略;第二个阶段中使用深度图作为输入,将第一阶段的策略蒸馏到第二阶段。在实际的四足机器人中,使用第二阶段的策略并使用Realsense相机采集的深度图作为输入。分为两个阶段的原因是,第一阶段更容易快速学习得到一个策略,而第二阶段不需要智能体与环境交互,仅使用监督学习就可以获得策略。本方法即使在A1这种小型机器人上也获得不错的策略,如越过相比于自身很高的障碍物。
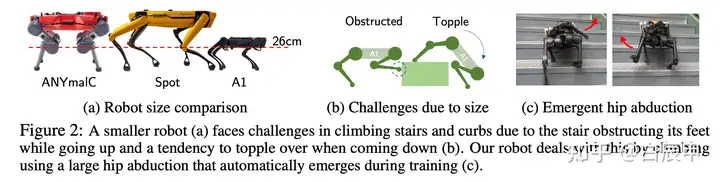
Robot with a standing height of 28cm to traverse the stairs of height upto 25cm
第一阶段过程:
输入状态包括(1)机器人自身信息:IMU information, Joint angles and veclocities, last action(2)Command信息:包括x方向的目标线性速度,yaw角速度(3)Elevation map:是ego-centric图,包含了机器人前向的高度信息,表示为一个mt矩阵,包含88个点。
网络结构包括(1)使用 MLP 网络对 elevation map 提取特征,随后和其他低维的状态信息连接起来作为RNN策略的输入。策略使用PPO进行训练。
奖励的设计较为复杂,如下:

- 在训练中使用 Learning to Walk in Minutes Using Massively Parallel DRL 类似的方法进行环境设计和 curriculum 训练。具体过程如下图(左)所示。
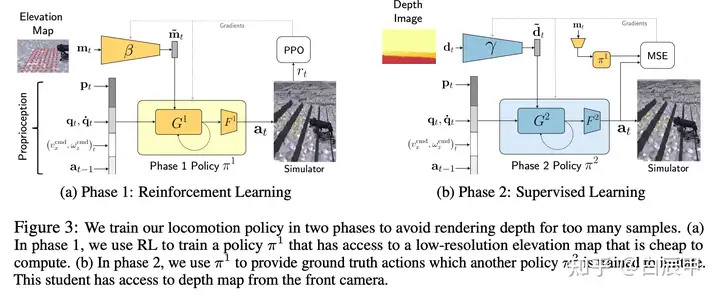
第二阶段过程:
第二阶段的过程是将第一阶段的策略进行蒸馏,不同之处是输入由高程图变成了深度图。其中, Math input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input error$Math input error$ 和 Math input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input error$Math input error$ 中的权重参数由训练好的 Math input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input error$Math input error$ 分别进行初始化。 Math input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input error$Math input error$ 网络用于对深度图进行处理。
该阶段的训练损失为监督学习损失,使用对应的高程图观测输入到策略 Math input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input error$Math input error$ 中,最小化 Math input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input error$Math input error$ 输出的动作和 Math input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input error$Math input error$ 输出的动作。
深度图在实际训练中由 Intel RealSense 相机进行获取,分辨率为480*848,经过crop white pixel以及下采样,最终用于输入的维度是 58**87。
在包括第一阶段和第二阶段都使用domain randomlization,分别对高程图和深度图进行扰动。第二阶段训练得到的策略可以直接用于 real-robot。
实验 Baselines:
Blind Policy: 去除了高程图作为输入,第一阶段的策略仅使用其他状态进行训练。
Privileged Teacher: 在第一阶段使用高程图作为输入时不添加任何的扰动,相比而言原方法在第一阶段对输入添加了 lag, latency 和 limited view 等扰动。
**Noisy:**在高程图中使用了额外的Noisy model。
Coupling Vision and Proprioception for Navigation of Legged Robots. CVPR 2022
https://navigation-locomotion.github.io/navigation-locomotion.github.io/
本文结合视觉模型,提出了一个较为复杂的机器人导航和行走相结合的结构,包含三个部分:Planner, Safety advisor, Walking policy。在执行实际的 Goal-conditional 任务中,由这三个方面进行协调来获得好的策略。
Walking Policy 是最基础的模块,利用四足机器人的本体信息,在 simulation 中使用 RL 算法训练得到一个行走策略。在实际的 apply 中,由于四足获得的信息和仿真器中获得的完备信息不同,需要训练一个监督学习的模型,使用四足实际的状态序列和动作序列来预测 true extrinsics vector,从而使实际运动中的信息和仿真器信息相互匹配。
Safety advisor 包括两个部分,第一部分是一个 Collision Detector,使用监督学习的方法进行训练,在仿真器中通过机器人的本体信息来预测发生碰撞的概率。如果预测到大概率会发生碰撞,会修改 planner 中产是的 cost map 来使 planner 规划一条绕过当前障碍物的路径。第二部分是 Fall Predictor,输出的也是一个概率值,表示智能体是否会有倾倒的可能,在仿真器中使用监督学习的方法进行训练。在实际使用中,如果输出的倾倒概率较高,则会降低 command 中的期望速度;反之则会提升期望速度。通过改变期望的速度来使智能体避免倾倒。
Visual Planner 是一个基于视觉的模块,包含几个部分:
Mapping Module:根据 onboard camera 生成一个俯视的 2D occupancy map。在四足行走过程中,使用深度相机获得点云数据,并转换为世界坐标系,从而对四足所在位置进行估计,将估计投影成一个2D平面图。
Cost map 生成:使用 Fast marching method (FMM) 来计算当前位置到目标位置的集合距离;通过FMM来计算当前位置到最近的障碍物的距离。Cost计算需要同时考虑goal和障碍物:当前位置距离Goal的位置越近,cost 越高;如果当前位置距离障碍物的距离越近,则cost越低。形式化的,
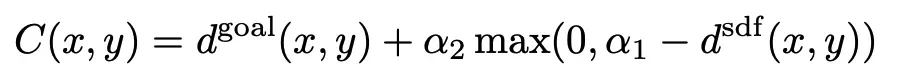
- 在生成 cost map 之后,基于 cost map 可以计算最优的 command,其中包括四足的前进方向和角度,command 跟随 cost map 的 negative gradient 方向来进行训练,目标是选择使 cost map 最小的命令。
如下图所示,通过 visual planner 提供的 cost map 信息,四足可以检测到障碍物并绕道。

Visual-Locomotion: Learning to Walk on Complex Terrains with Vision. CoRL 2021
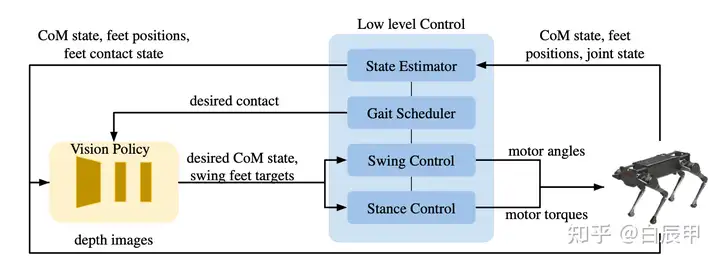
本文提出了一个层次化的结构,在上层使用视觉信息作为输入,学习一个High-level的策略;下层学习一个 low-level 的 motion controller。具体的
Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers. ICLR 2022
Learning Vision-Guided Quadrupedal Locomotion End-to-End with Cross-Modal Transformersrchalyang.github.io/LocoTransformer/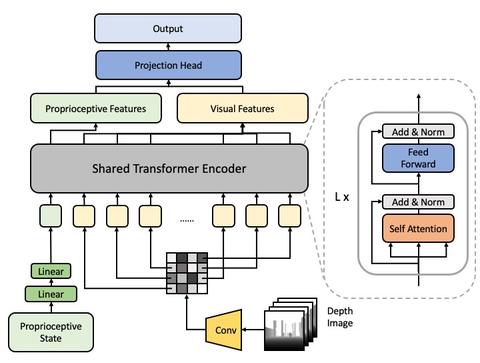
本文的 motivation 是之前多数的四足机器人工作仅依靠机器人本体状态(proprioceptive state,包括 pose, imu, joint rotations)等,而忽略了周围环境的信息,导致机器人在跨越障碍物中缺乏了许多环境信息。本文使用Transformer 网络来结合机器人的本体状态和视觉信息(深度相机),从而在进行决策中能够同时考虑本体状态和环境信息。模型结构如下图所示。具体的,Proprioceptive input 是一个 93d 的向量,视觉信息的输入是一个深度图(64*64)。本体状态和视觉信息分别用不同的编码器进行编码,随后使用 transformer 结构进行跨模态的 attention 操作,最后使用 projection head 将跨模态的信息进行融合。
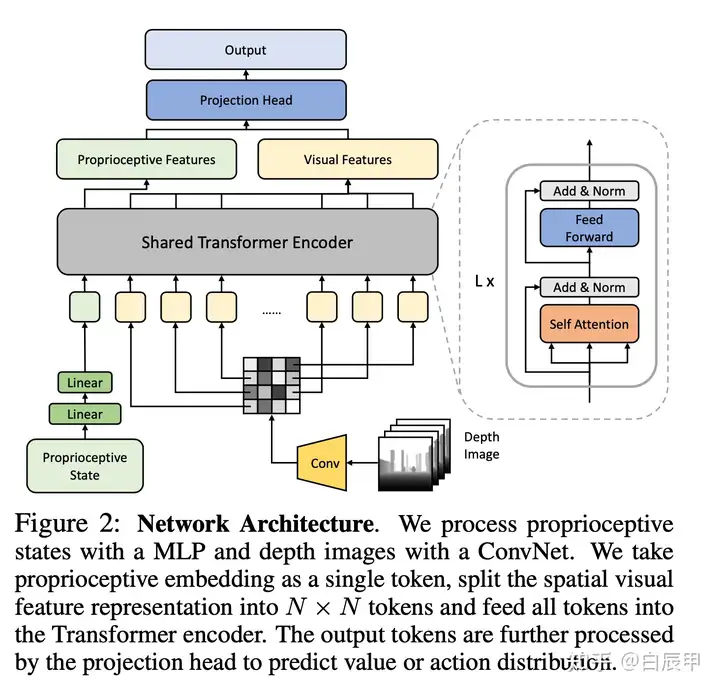
整个模型使用PPO算法进行训练,上述的网络结构中,本体信息的编码器和视觉编码器在值函数网络和策略网络之间进行公用,随后值函数网络和策略网络分别输出值函数估计和动作。结果表明,本文提出的模型相对于 state-only 和 depth-only,或者简单的 state-depth concat 的方法都有较为明显的性能提升。
Goalkeeper: Creating a Dynamic Quadrupedal Robotic Goalkeeper with Reinforcement Learning. arxiv 2210.04435
https://www.youtube.com/watch?v=iX6OgG67-ZQ&feature=youtu.be&ab_channel=HybridRoboticswww.youtube.com/watch?v=iX6OgG67-ZQ&feature=youtu.be&ab_channel=HybridRobotics
本文利用视觉信息结合技能学习展示了一个守门员的 demo。在学习中建模为一个层次化策略,分为上下两层。其中下层学习固定的skill策略,包含三个:
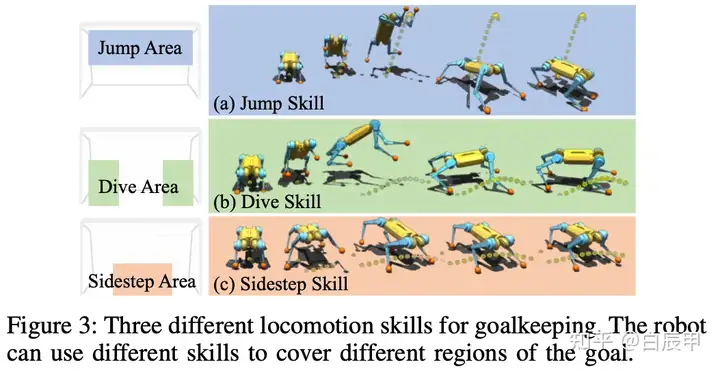
side-step 侧步技能。当球在地面上滚动或以较低姿态向球门飞去时,机器人会在侧向快速移动以拦截球。根据步幅的大小,机器人可能需要将一只前腿向上摆动,而其他腿可以保持在站立阶段。但对于较大的步幅,站立腿也可能需要离开地面,从而产生一个小的侧向跳跃。然而,侧步技能可能无法覆盖距离机器人较远的区域,例如球门的下角或上部区域。
Dive 跳跃技能。产生四足机器人的跳跃行为,使得机器人能够覆盖更大的球门区域。使用跳跃技能,机器人应该首先将身体向上倾斜到后腿上,然后朝着球的行进方向转向侧面,伸展其两个摆动腿以到达球,最后以双脚着地。这种技能使机器人能够快速阻挡球门的下角。
Jump 跳跃技能,要求机器人俯仰身体并尽可能快地向上摆动前腿。当机器人向球门上部移动时,它还需要将摆动腿伸得更高以拦截球。为了进行这种动态跳跃,机器人需要用后腿离开地面,以便伸展前腿到达更高的区域。截获球后,机器人需要在空中重新配置成更稳定的着陆姿势。
三种技能的可视化如下图所示。
Low-level:在技能学习中,使用 Bézier 曲线来参数化每种技能预期的轨迹,对每种技能设置不同的贝塞尔曲线参数。随后单独训练每种技能,通过模仿贝塞尔曲线产生的轨迹来训练策略输出理想的 joint-level command。
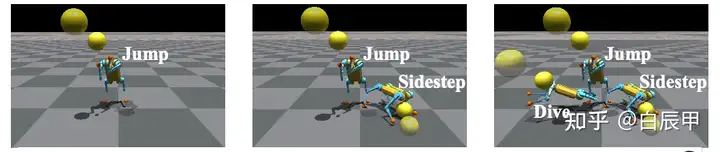
High-level:学习一个高层策略来调用这些技能,使用视觉传感器观测到的球体位置(使用YOLO算法)和机器人自身的本体信息作为输入,输出一个策略来选择某个技能进行执行。训练在模拟器中进行,如下图所示。
4. Sim-to-Real / Generalizations / Imitations
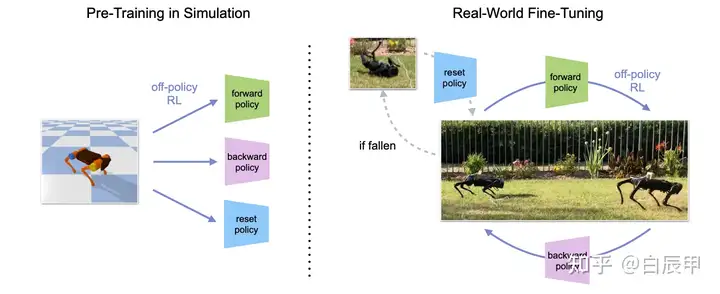
Legged Robots that Keep on Learning: Fine-Tuning Locomotion Policies in the Real World. ICRA 2022
Homesites.google.com/berkeley.edu/fine-tuning-locomotion
总结:本文使用的方法与 Learning to walk in 20 minutes 中使用的REDQ一致,该方法由于具有较高的UTD值,比较适用于在真实环境中进行学习。首先,在仿真环境下学习多个策略,每个策略代表一种固定行走方式(前向、后向)等。随后,在 sim-to-real 的过程中,在真实环境下对 REDQ 的策略进行微调,由于REDQ方法能够高效的利用数据,在进行微调后策略能够适应 sim 和 real 环境的不同。结构如图所示。
GenLoco: Generalized Locomotion Controllers for Quadrupedal Robots. CoRL 2022
https://github.com/HybridRobotics/GenLocogithub.com/HybridRobotics/GenLoco
https://www.youtube.com/watch?v=5QUs32MjNu4&feature=youtu.be&ab_channel=HybridRoboticswww.youtube.com/watch?v=5QUs32MjNu4&feature=youtu.be&ab_channel=HybridRobotics
该文章研究四足机器人策略在不同机型之间的泛化问题,其目的是训练单个策略,使其能够同时适用于多种不同的机型,具体包括Unitree’s A1, Go1, Aliengo, Laikago, MIT’s Mini Cheetah, CUHK’s Sirius, and Boston Dynamics’ Spot 等。文章的 motivation 包括:
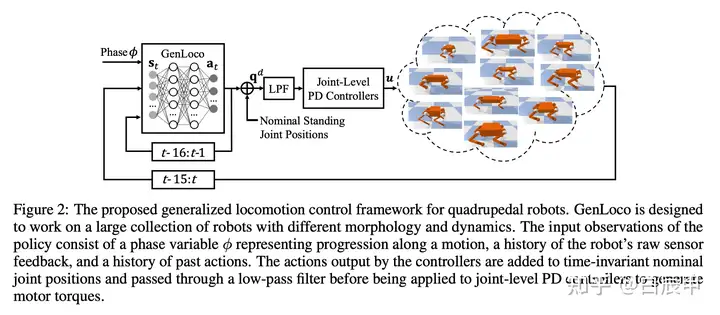
解决该问题的一个基本点是,不同机型的四足机器人都可以用一个通用的形态学框架(common morphological template)来描述,包括一个机器人平台(robot base)和四个腿部单元(每个单元包括3个自由度:hip, thigh, knee joints)。具体如下图所示。
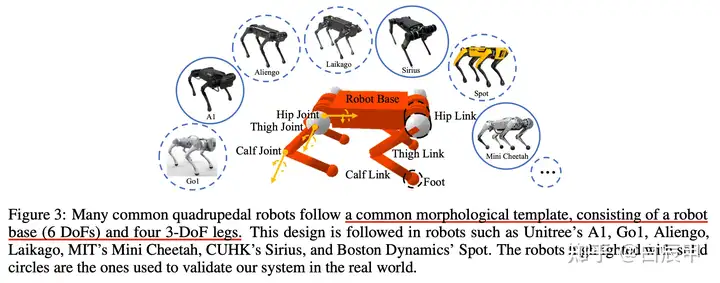
在该假设的基础上,可以使用 domain randomization 的方法生成随机的形态学描述。具体的,根据不同机型之间的差异,在每个不同的单元上制定不同的 randomization 的范围。本文以 Unitree A1 机器人为基准,根据其与其他机型的差异,对不同的部位的参数使用了如下的 randomization,使用随机之后的形态学进行强化学习策略训练(使用PPO,Pybullet仿真环境),得到的策略可以适用于在此范围内的多种四足机器人。
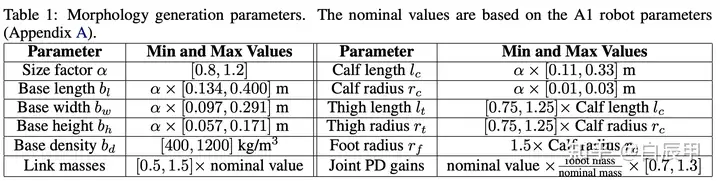
Domain randomization 范围
根据表所示,需要进行 domain randomization 的参数包括大小,各组件的长、宽、密度,连杆密度、PD控制器的参数等。所有的 randomization 都以 A1 机器人为基准。实验结果表明,策略能够在很宽的参数设定范围内都具有较好的效果,故而能够 zero-shot transfer 到不同形态学的四足机器人中。
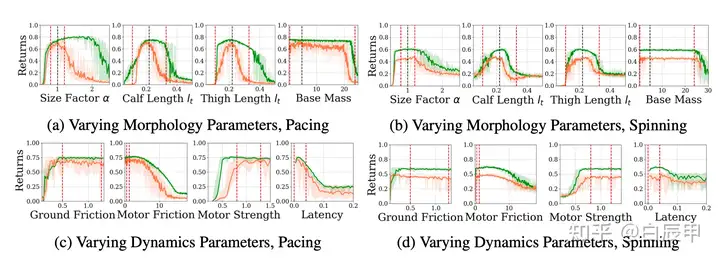
Experiments on a1 robot
Learning Semantics-Aware Locomotion Skills from Human Demonstration. CoRL 2022
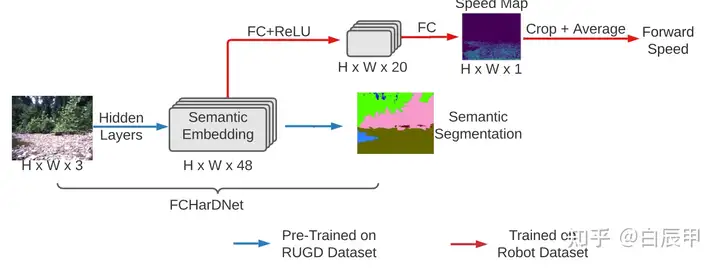
本文结合当前场景信息和专家的示范信息,实现了对四足运行速度(speed)和步态(gait)的精确调节。文章的动机是,当四足机器人的运动场景进行切换时(gass, mud, asphalt)等,四足需要根据当前场景对运行的速度和步态进行调整,以期望做到更加稳定的控制。具体的,合理的 speed 和 gait 通过人类的示教信息来给出,随后学习人类专家的动作进行模仿。
如下图所示,通过人类专家的信息来训练一个 high-level 的 skill policy,其中包含了 forward speed 和 gait parameter,分别用来控制速度和选取步态。随后,根据选择的指令信息,由MPC控制器转换为底层的指令。
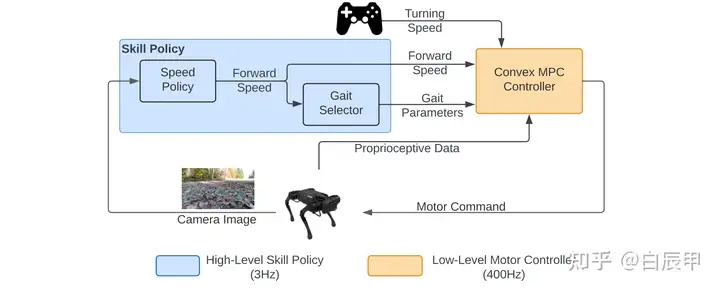
其中,由于在选取 speed 和步态 gait 中需要结合场景的语义信息,本文语义分割的模型 FCHarDNet 来获取语义场景的信息,在产生分割结果之前提取一个 semantic embedding 的语义标签信息,将该信息作为预测speed的特征,从而在预测speed时能够获得更好的语义信息。最终 speed 的预测使用 behavior cloning 的损失函数。
Learning a Unified Policy for Whole-Body Control of Manipulation and Locomotion. CoRL 2022
本文的目标是将四足机器人本身的运动和机械臂的操作作为一个整体来进行控制,控制器可以同时输出四足的运动策略和机械臂的操作策略。演示效果如下图所示。

具体的,在值函数的学习方面,分别输出两个部分的(arm 和 legged) 的 value function 和 advantage function,两套值函数分别使用不同的 reward function 进行训练,如下图。

在学习值函数的基础上,策略通过分别的策略梯度法来进行优化。下式表示了类似REINFORCE的策略梯度。
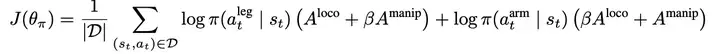
本文的另外一个创新之处在于改进了原本的 teacher-student 学习架构。原本的架构分为两个阶段,第一阶段通过模拟器的完备环境信息使用强化学习得到 teacher 的策略,第二阶段通过策略蒸馏的方法来得到 student 的信息。而本文提出可以将两个阶段合并成为一个过程,在teacher和student同时学习的过程中,将他们的 latent representation 进行监督和约束。具体的,student 输出的编码以 teacher 作为监督,而 teacher 输出的编码以 student 作为约束。为了训练的稳定性,在训练 student 时将 teacher 编码作为 fixed 向量,反之亦然。如下式所示, Math input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input errorMath input error$Math input error$ 从 0 逐步增加到 1,表明在训练开始时 teacher 的学习是不受 student 约束的。
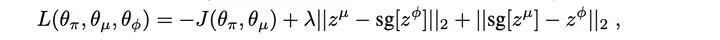
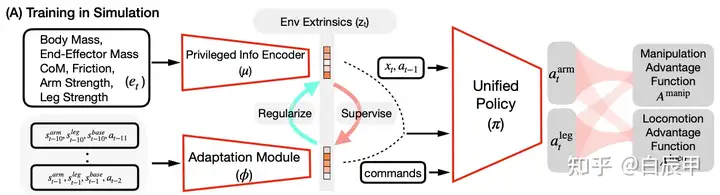
Overview of training and teacher-student architecture