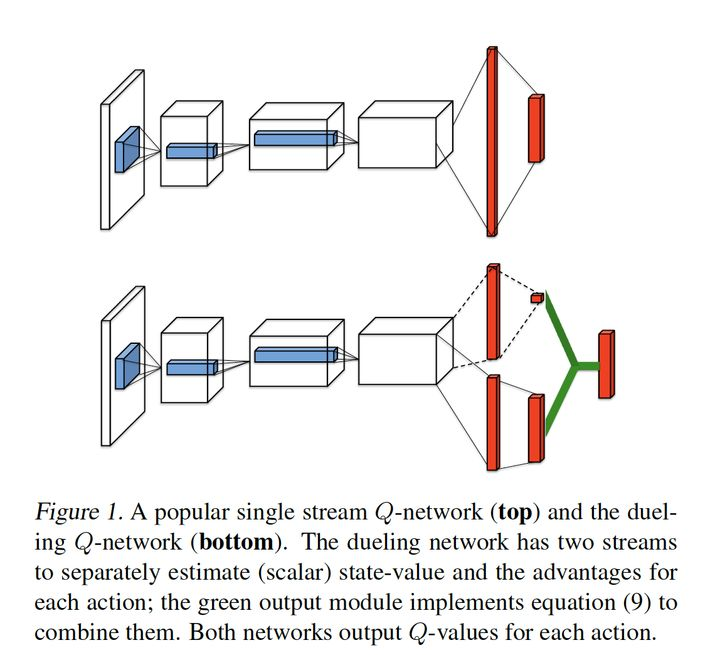
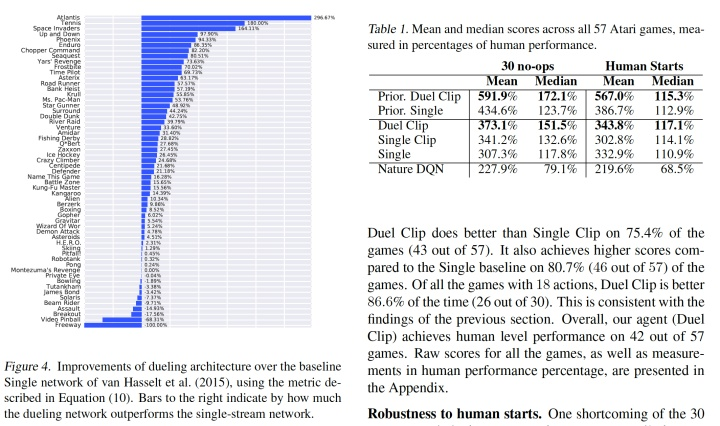
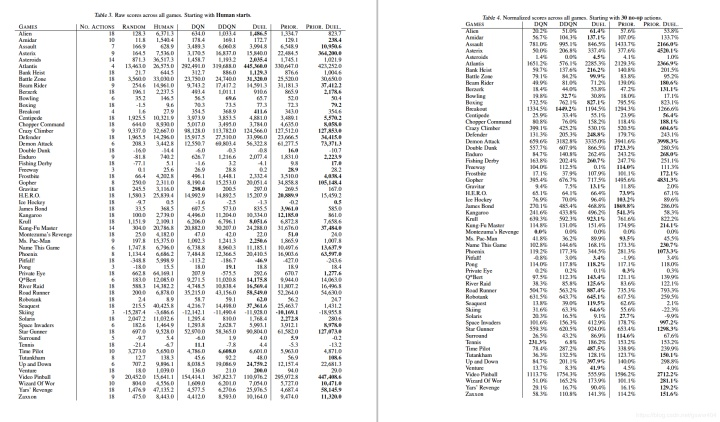
代码复现
本部分采用莫凡代码,在Pendulum-v0环境中进行试验。
"""
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import DuelingDQN
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
env = gym.make('Pendulum-v0')
env = env.unwrapped
env.seed(1)
MEMORY_SIZE = 3000
ACTION_SPACE = 25
np.random.seed(1)
tf.set_random_seed(1)
class DuelingDQN:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.001,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
dueling=True,
sess=None,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.dueling = dueling # decide to use dueling DQN or not
self.learn_step_counter = 0
self.memory = np.zeros((self.memory_size, n_features*2+2))
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
if sess is None:
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
else:
self.sess = sess
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.cost_his = []
def _build_net(self):
def build_layers(s, c_names, n_l1, w_initializer, b_initializer):
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
if self.dueling:
# Dueling DQN
with tf.variable_scope('Value'):
w2 = tf.get_variable('w2', [n_l1, 1], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, 1], initializer=b_initializer, collections=c_names)
self.V = tf.matmul(l1, w2) + b2
with tf.variable_scope('Advantage'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.A = tf.matmul(l1, w2) + b2
with tf.variable_scope('Q'):
out = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) # Q = V(s) + A(s,a)
else:
with tf.variable_scope('Q'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
out = tf.matmul(l1, w2) + b2
return out
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer)
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer)
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon: # choosing action
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next = self.sess.run(self.q_next, feed_dict={self.s_: batch_memory[:, -self.n_features:]}) # next observation
q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
sess = tf.Session()
with tf.variable_scope('natural'):
natural_DQN = DuelingDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, sess=sess, dueling=False)
with tf.variable_scope('dueling'):
dueling_DQN = DuelingDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, sess=sess, dueling=True, output_graph=True)
sess.run(tf.global_variables_initializer())
def train(RL):
acc_r = [0]
total_steps = 0
observation = env.reset()
while True:
# if total_steps-MEMORY_SIZE > 9000: env.render()
action = RL.choose_action(observation)
f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # [-2 ~ 2] float actions
observation_, reward, done, info = env.step(np.array([f_action]))
reward /= 10 # normalize to a range of (-1, 0)
acc_r.append(reward + acc_r[-1]) # accumulated reward
RL.store_transition(observation, action, reward, observation_)
if total_steps > MEMORY_SIZE:
RL.learn()
if total_steps-MEMORY_SIZE > 15000:
break
observation = observation_
total_steps += 1
return RL.cost_his, acc_r
c_natural, r_natural = train(natural_DQN)
c_dueling, r_dueling = train(dueling_DQN)
plt.figure(1)
plt.plot(np.array(c_natural), c='r', label='natural')
plt.plot(np.array(c_dueling), c='b', label='dueling')
plt.legend(loc='best')
plt.ylabel('cost')
plt.xlabel('training steps')
plt.grid()
plt.figure(2)
plt.plot(np.array(r_natural), c='r', label='natural')
plt.plot(np.array(r_dueling), c='b', label='dueling')
plt.legend(loc='best')
plt.ylabel('accumulated reward')
plt.xlabel('training steps')
plt.grid()
plt.show()
参考内容:
https://arxiv.org/pdf/1511.06581.pdf
https://github.com/MorvanZhou