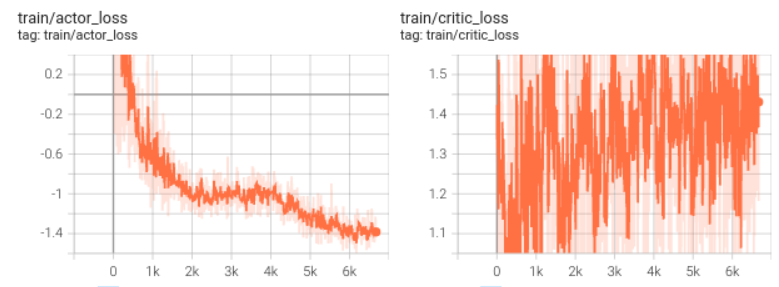
actor_loss = -self.critic(state0,a),actor网络最大化critic的评分作为loss,但是actor网络没有按照样本的动作收敛是什么问题啊,动作为(x,y,x,a),空间坐标+旋转动作,取值范围为[-1,1],如果加上动作误差,即actor_loss = -self.critic(state0,a)+F.mse_loss(actions,a),actor网络收敛了,但是critic网络误差一直上升,无法收敛
不知道具体是什么应用场景,建议关注 reward 而不是 loss,从DDPG 包含自举的过程,因此不需要关注loss的收敛性,Critic loss 避免高估爆炸即可
关注一下第二个原因
sepilqi 这个回复秀了,点赞
不知道是不是输出连续动作的方式有问题?