

南栖致力于推动强化学习在现实业务中的落地。在现实场景中,环境往往会不断变化,智能体无法适应变化后的环境,导致其决策失效。
为此,南栖仙策与南京大学团队提出了一种环境敏感的上下文策略学习(environment sensitive contextual policy learning, ESCP)算法,论文发表在AAAI’22会议上,该方法可以提升环境识别的速度、增加环境识别的稳定程度,能够在突变环境中取得更高的性能。
除此之外,该方法还为训练决策大模型提供了技术途径,能够训练出针对反馈控制任务的决策大模型(在文章的末尾进行了介绍并提供了下载地址)。
动荡现实和稳定理想的碰撞
近年来,强化学习在很多稳态的环境中已经达到了甚至超越了人类的水平。前沿的算法已经可以适应训练中未曾见过的环境或任务。然而,这种较强的自适应能力,通常要求环境是稳定且不改变的。例如下围棋的过程中,围棋的棋盘不会突然变大或变小、围棋的规则也不会变成五子棋,这一类环境被称为稳态 (stationary) 环境。以往的强化学习只需要适应一种稳定不变的环境,找到最优的策略,即可达到目标。
可惜,这一属性在现实世界往往并不能成立。现实世界,时刻处在动荡和不断变化之中,例如在走路的时候,脚下的路面突然从草地变成沙丘;又或者汽车在行驶中,因为道路积水结冰而突然改变了原有的运动方程。
当环境发生突变的时候,如果不能对环境快速适应,则很难避免灾难发生。

一辆车沿着弯曲的道路驶来,转弯拐角的水洼,大大地降低了道路的摩擦力。当司机没有注意到道路的变化,不能及时地响应,那么车辆极有可能失去控制,造成意外事故的发生。
环境的突变在许多场景都是棘手的问题,对环境变化的快速识别和自适应有着重要的意义。
从人类的应对方式获得经验
如果是经验丰富的驾驶员,在经过水洼时,通过对当前速度、行驶方向和油门、方向盘的控制状况,能够意识到当前正在经过一段不同路面,从而迅速调整驾驶策略,最大限度地规避风险,最终安全地通过这片区域。
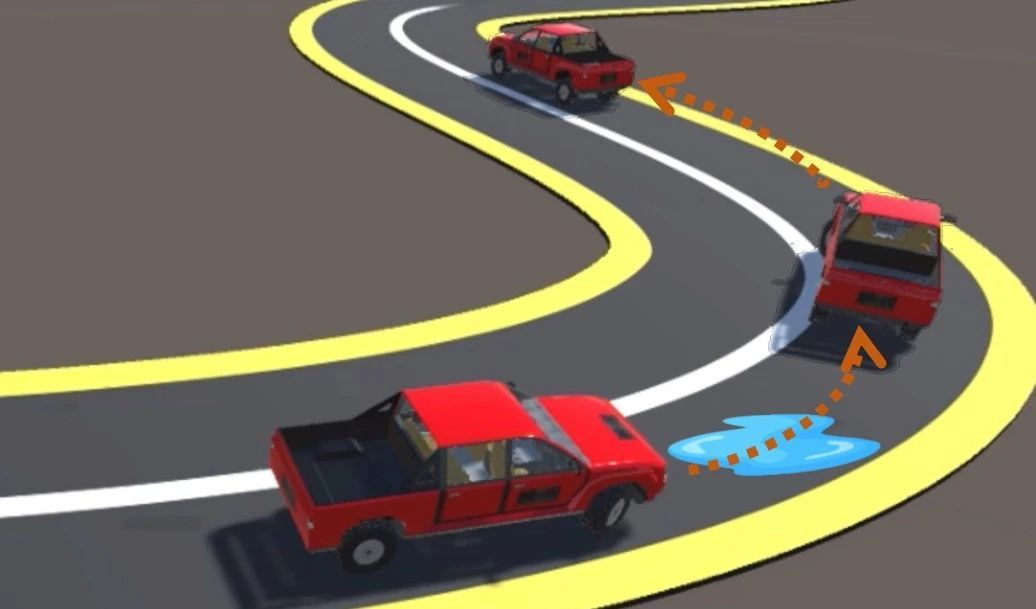
如果是AI,又该如何处理环境的突变?对人类驾驶员的应对方式进行总结,我们发现了两个关键点:其一是能够在运行过程中自动感知到环境的变化,其二是在感知到变化后能够自动调整自己的决策策略。
为了能够跟人类专家一样妥善处理环境突变,我们首先需要收集观测信息,并依此对环境的特征进行实时推测,实现对环境的快速辨识,然后根据所识别的特征来及时调整控制策略。基于上下文的元强化学习(context-based meta-RL)方法恰好能够同时满足这两个关键点。这种方法由两部分构成,一是用于提取环境相关信息的上下文编码器,二是用于进行自适应决策的上下文策略。前者提取环境特征,后者基于环境特征与当前状态输出对应的动作,当前者识别到环境的改变时,后者就能够相应地做出正确的动作。
快速识别变化是重中之重
然而,要识别环境的变化,以往的方法所需要的环境交互数据较多,这会造成环境特征提取的过程有较大时延。这样一来,策略无法及时对变化进行响应,汽车最终还是无法安全通过水洼区域。因此,我们就如何快速适应突变环境这个问题进行了研究。
我们认为,实现快速突变环境适应的关键,在于快速且准确的环境特征抽取。我们期望能够在尽可能短的时间内(尽可能少的环境交互步数)对环境特征进行准确识别。
在这一研究动机的驱使下,我们提出了一种新的方法:环境敏感的上下文策略学习(environment sensitive contextual policy learning, ESCP)使得智能体能够快速识别并适应环境的突变。
ESCP沿用context-based meta-RL的框架。其在context-based meta-RL的基础上,额外引入了三部分关键组件:首先是用方差最小化损失让环境上下文编码器对环境进行快速且鲁棒的特征提取(我们也称之为环境编码);其次是基于相关矩阵行列式最大化损失来避免编码器生成无意义的环境特征并且让不同环境之间的特征更为可分;最后是使用历史截断的循环神经网络模型让上下文编码器能够更关注于最近几步和环境的交互数据。
有了这几个模块,ESCP的上下文编码器能够从最近的与环境交互的数据中快速提取到环境的特征,而后的上下文策略也能够相应地快速对环境突变进行响应,调整自身的策略。
具体框架如下图所示:
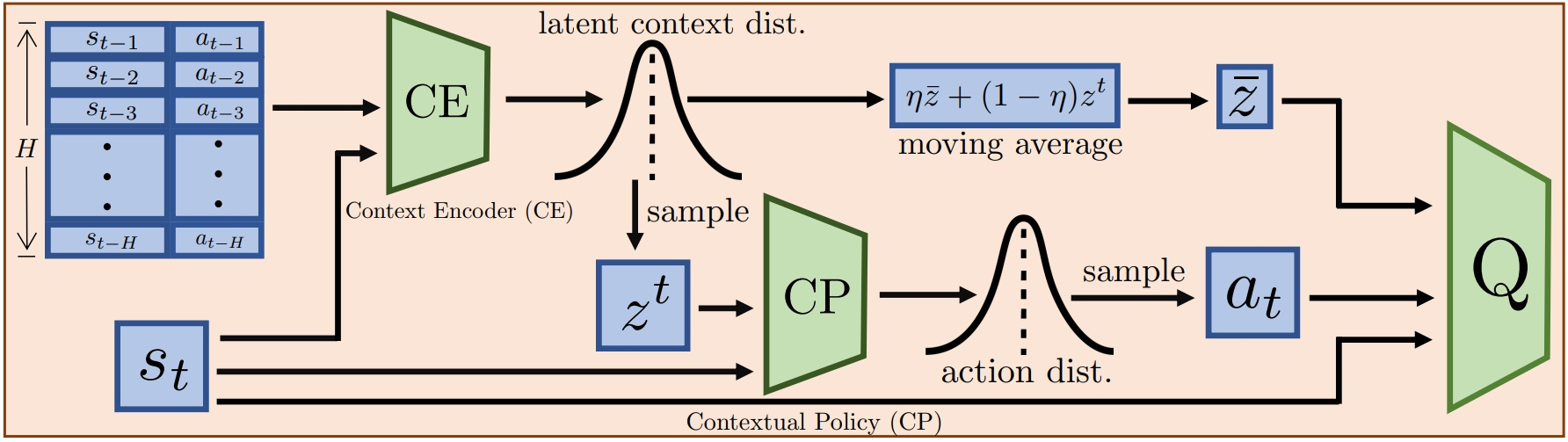
首先,一个隐上下文分布会被一个上下文编码器推断出来;然后,一个上下文策略会根据隐上下文和当前状态进行决策。其中,动作值函数通过状态动作对以及一个滑动平均的隐上下文去推断Q值。
回到前文的例子,在经过水洼时,这个策略可以如熟练的人类驾驶员一般,迅速地感知环境的变化,及时调整策略,做好准备以迎接变化后的环境。
在论文中,我们用一系列的突变环境检验了ESCP方法:包括一个网格世界和五个运动控制任务。最终结果证明,无论是在与训练环境相同分布或是不同分布的测试环境下,相比最先进的meta-RL算法,ESCP都能更好地提取环境的特征,并能够更快速地适应环境的改变。
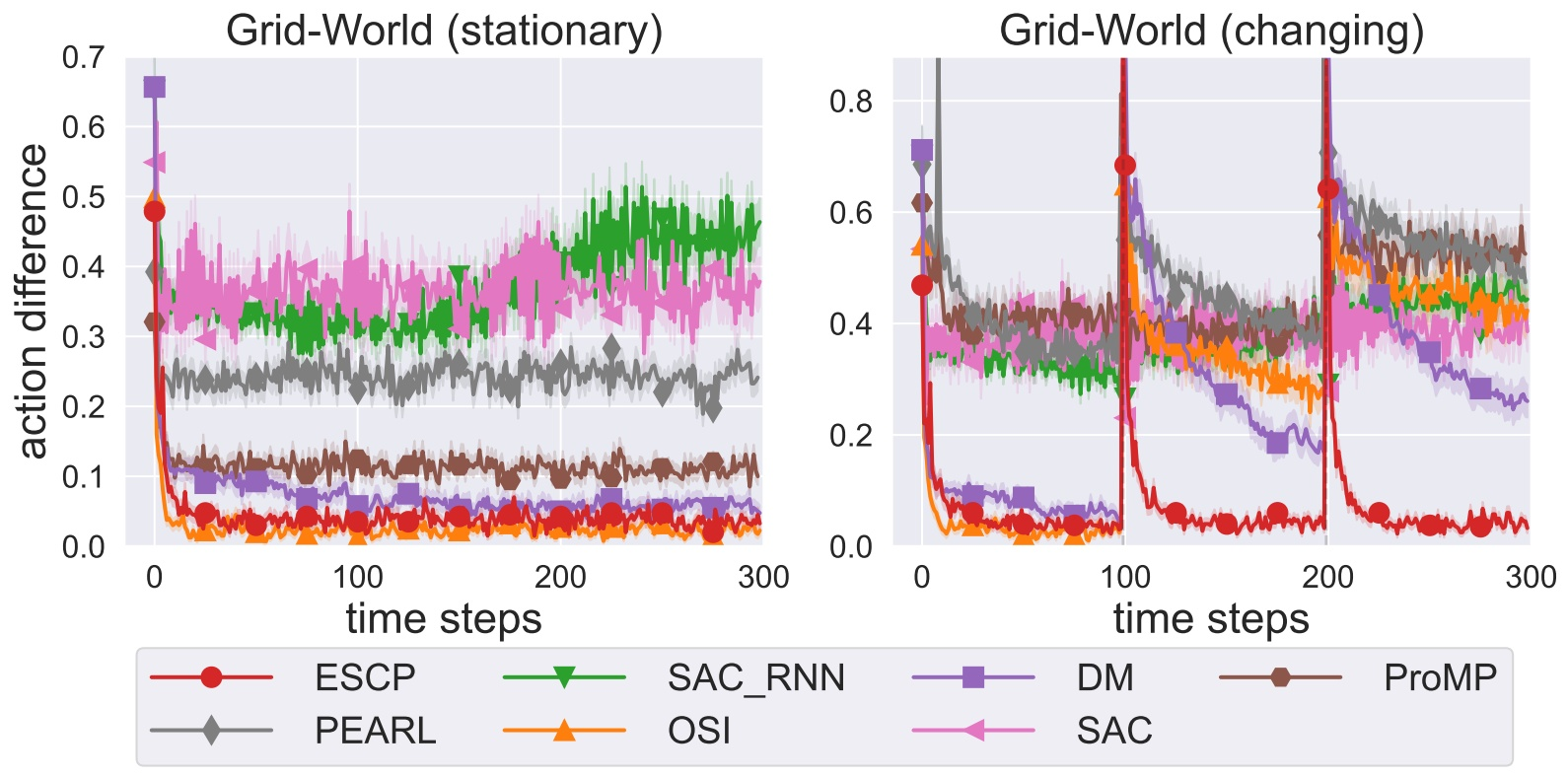
不同方法学到的策略与环境最优策略所执行的动作之间的差异曲线图:左图为在稳定环境下的差异;右图为在突变环境下的差异。
我们在网格世界环境中对比了一系列算法,将由训练得到的策略与环境最优策略之间每1步的动作的差异的结果展示于如图。对比两张图,可以看出在左侧稳定环境中,很多方法与ESCP都能够在较短时间内收敛到最优策略。但是在右侧突变环境中,环境每100步会发生一次突变,当突变发生后,ESCP仅在10步之内收敛到距离最优策略0.1的范围内,而其余所有方法都无法在100步之内收敛到此范围。从这个结果可以看出,ESCP能够以更快的速度再次收敛到最优策略。在这个任务中,ESCP对突变环境的适应速度比基线算法快10倍以上。
技术应用和延展
面对不断变化的环境,往往需要快速做出最恰当的决策反应。ESCP能够敏锐地识别并不断适应新的环境,进而解决大规模的现实世界问题。我们期望通过ESCP,以一种更聪明、更精简的方法,真正地帮助大家应对生产生活中的难题。我们已经将这项技术应用在了☞流程工业中的复杂场景控制、☞汽车行驶中的车身控制等真实案例中。
同时,ESCP也为决策大模型开启了新的方向。
针对工业场景中广泛存在的反馈控制系统,我们用ESCP在7万多个控制案例上训练了环境识别器GFSEncoder,该模型部署即可用,输出其识别到的环境特征,可直接用于对环境变化的预警、系统标定、PID自动参数推荐。
此外,我们还训练了控制大模型GFSController,可以直接用于反馈控制系统的自适应控制。
详情移步☞发布会:预训练模型。该模型亦可在REVIVE官网revive.cn中获取。
南栖仙策愿不断挑战更复杂的任务,扩展AI解决问题的边界。
Adapt to Environment Sudden Changes by Learning a Context Sensitive Policy,阅读我们在AAAI’22会议上发表的论文,了解有关ESCP的更多信息。