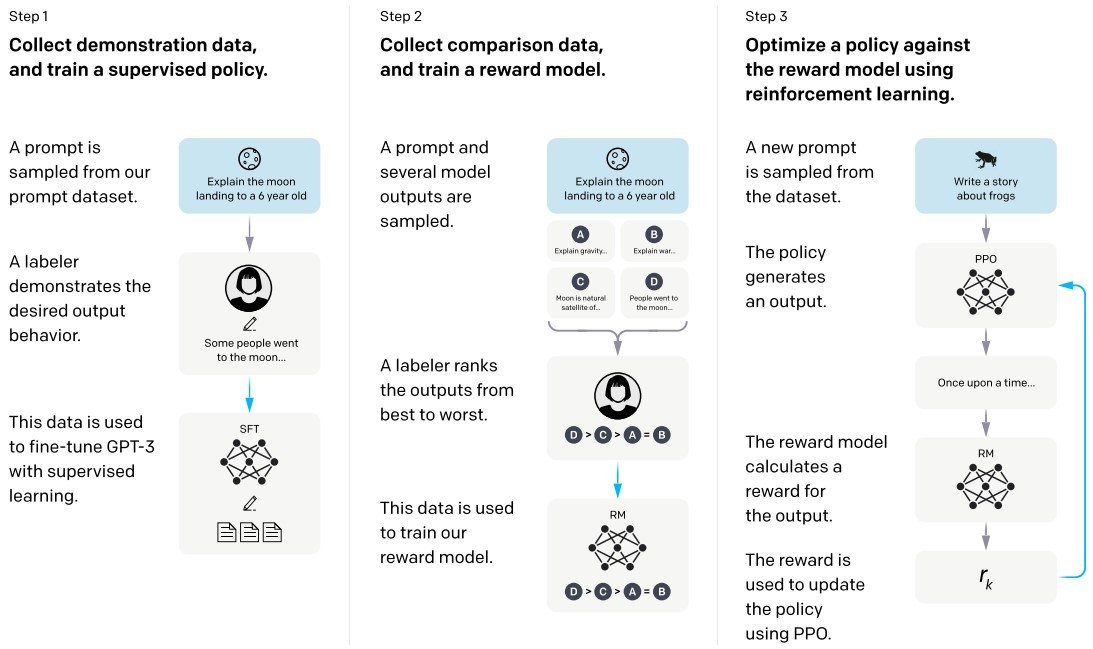
本篇将介绍InstructGPT的RM过程,也就是reward model的训练,废话不多说,直接上干货。
RM(Reward Model)模型
这里引入RM模型的作用是对生成的文本进行打分排序,让模型生成的结果更加符合人类的日常理解习惯,更加符合人们想要的答案。RM模型主要分为两个部分:训练数据获取和模型训练部分。流程如下图所示
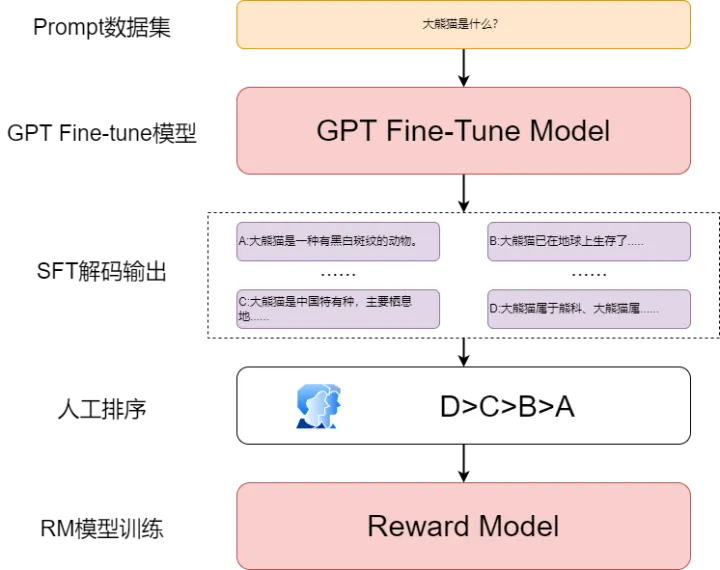
RM 模型训练流程
整个模型流程没啥可说的,在原论文中使用GPT的架构做了一个reward model,这里需要注意的是要将模型的输出映射成维度为1的打分向量,也就是增加一个linear结构。RM模型的主要点还是在于人工参与的训练数据构建部分,将训练好的SFT模型输入Prompt进行生成任务,每个Prompt生成4~9个文本,然后人为的对这些文本进行排序,将每个Prompt生成的文本构建为排序序列的形式进行训练,得到打分模型,以此模型用来评估SFT模型生成的文本是否符合人类的思维习惯。
RM模型代码实操
这里尝试两种方法,这里将这两种方法命名为direct score和rank score:
Direct score:一个是直接对输出的文本进行打分,通过与自定义的label score计算loss,以此来更新模型参数;
Rank score:二是使用排序的方法,对每个Prompt输出的n个句子进行排序作为输入,通过计算排序在前面的句子与排序在后面的句子的差值累加作为最终loss。
Direct score方法
这个方法就是利用Bert模型对标注数据进行编码,用linear层映射到1维,然后利用Sigmoid函数输出每个句子的得分,与人工标记的得分进行loss计算,以此来更新模型参数。流程如下所示
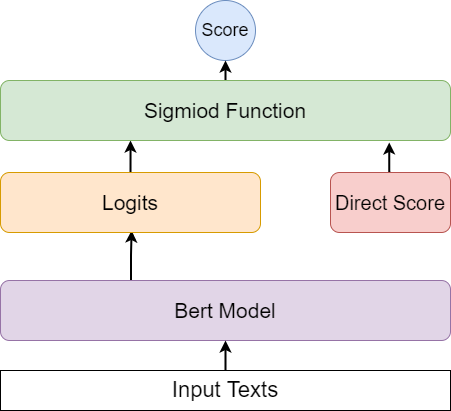
Direct Score计算流程
数据准备及处理
这里使用的数据为上一篇SFT最后所生成的数据,数据准备如下所示:
def data_prepare(pretrain_path):
data_lst = [
"我们去成都旅游,必须要去的地方是大熊猫繁殖基地。大熊猫是今世界上保存最完好的哺乳动物之一,也是世界自然保护联盟濒危物种红色名录的保护对象之一。在这里,你可以看到全世界最大的熊猫栖息地成都。成都是中国国家林业局直属的国家重点风景名胜区,是国家森林公园、国家湿地公园和国家地质公园的重要组成部分,是全国重点文物保护单位、全国生态文明建设示范区、中国红色旅游名城、国际生态旅游目的地和国际旅游岛建设先进区。地址:四川省成都市绵阳市成华区成都高新技术产业开发区成华大道1号乘车路线:成都绵阳都江堰雅",
"我们去成都旅游,必须要去的地方是大熊猫繁殖基地。大熊猫是我国唯一的国家二级保护动物,是世界上保存最完整的动物种群之一,也是我国第一个国家级自然保护区。我们是四川省的首批国家重点保护野生动物和珍稀动物基金会的成员,被誉为中国动物保护的摇篮和世界生物多样性保护基地,被中国科学院、中华人民共和国国家林业局授予全国生态文明建设示范区称号,被国务院批准为国家森林城市、国际生态旅游目的地。熊猫基地位于成都市双流区东南部,是国家aaaa级旅游景区,国家地理标志保护单位。熊猫栖息地为亚热带或热带的高山",
"我们去成都旅游,必须要去的地方是大熊猫繁殖基地。大熊猫是我国唯一的国家级自然保护区,也是世界上保存最完好的熊猫种群之一。它们栖息在亚热带或热带的高海拔草原上,生活环境十分优越,是中国四大自然奇观之一,被誉为世界自然遗产和中国国家森林公园。熊猫栖息地主要分布在中国大陆的西藏、青海、甘肃、宁夏、新疆、内蒙古、山西、辽宁、吉林、黑龙江、江苏、河南、安徽、湖北、湖南、江西、广东、海南、四川、云南、贵州、陕西等地。中国熊猫研究中心主任、中国科学院院士、国家自然科学基金委员会委员、中华全国工商业联合会副主席",
"我们去成都旅游,必须要去的地方是大熊猫繁殖基地。大熊猫是我国唯一的国家级自然保护区,也是世界上保存最完整、规模最大的野生动物种类繁多的地区之一,是中国国家重点保护的珍稀濒危动物及其栖息地和世界自然遗产的重要组成部分,被誉为中国最美丽的城市和世界生物多样性保护基地,被国际旅游组织评为全球生态旅游目的地。成都熊猫国家公园位于四川省甘孜藏族自治州,是国家aaaa级旅游景区,被《世界遗产名录》列为全国重点文物保护单位。目前,我国已建成国家森林公园、国家湿地公园和国家地质公园,国家林业局、国务院扶贫",
"我们去成都旅游,必须要去的地方是大熊猫繁殖基地。大熊猫是现存最大、保存最完整的动物,属于国家二级保护动物。熊猫种类繁多,分布广泛,主要分布在四川、云南、陕西、甘肃、宁夏、内蒙古、新疆、青海、吉林、辽宁、黑龙江、山西、江苏、江西、河南、湖北、湖南、广东、广西、海南、重庆、贵州、西藏、四川等省区市。它们的栖息地主要为亚热带或热带的(低地)湿润低地林、亚高山草原、高山湖泊、高原湿润山区和高原沼泽地等,常栖息在高海拔地区。在中国大陆,熊猫分布于四川省甘孜藏族自治州和青海省西宁市等地。雄性熊猫体长约1.5米"]
# 自定义打分标签,每个句子一个分值。也可以定义多维度的打分方法,只是模型的线性层需要改为你所定义的维度数
direct_score = [[0.75], [0.5], [0.35], [0.4], [0.8]]
tokenizer = BertTokenizer.from_pretrained(pretrain_path)
train_data = tokenizer.batch_encode_plus(data_lst, max_length=256, padding="max_length", truncation=True,
return_tensors='pt')
train_data["labels"] = torch.tensor(direct_score)
return train_data, tokenizer
RM模型搭建
完整内容请阅读原文