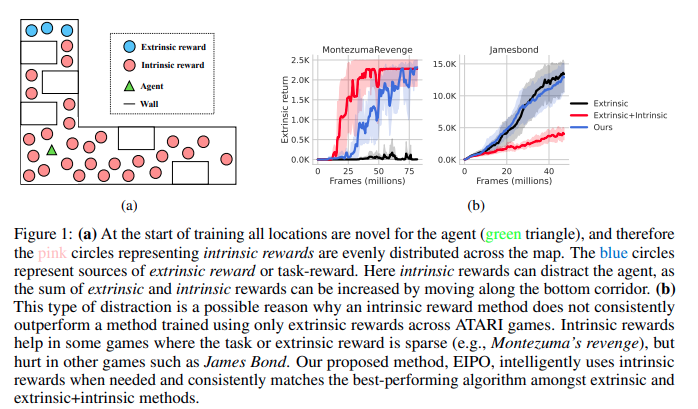
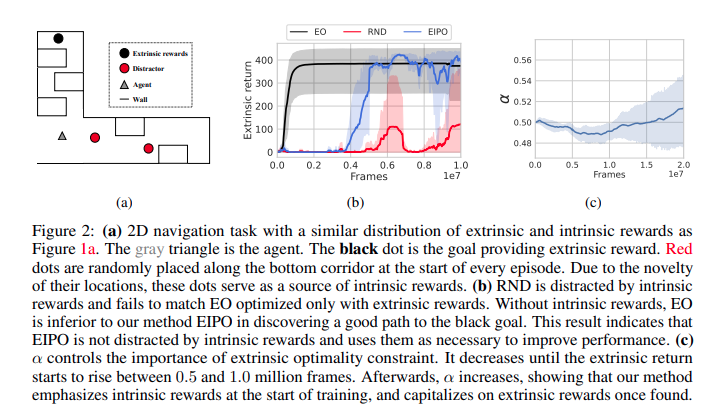
最先进的强化学习(RL)算法通常使用随机采样(例如,ε-greedy)进行探索,但这种方法在像Montezuma的复仇这样的艰难探索任务中失败了。为了应对探索的挑战,先前的工作通过探索奖金(也称为内在奖励或好奇心)激励代理人访问新的州。这种方法可以在艰难的探索任务中取得优异的结果,但与只使用任务奖励训练的代理相比,可能会存在内在的奖励偏见,表现不佳。这种性能下降发生在代理寻找内在奖励并进行不必要的探索时,即使有足够的任务奖励可用。这种任务间性能的不一致性阻碍了RL算法对内在奖励的广泛使用。我们提出了一种原则约束的政策优化程序,该程序自动调整内在奖励的重要性:当不需要探索时,它抑制内在奖励,当需要探索时增加内在奖励。这导致了卓越的探索,不需要手动调整来平衡内在奖励和任务奖励。六十一款ATARI游戏的一致性能提升验证了我们的说法。

强化学习(RL)[1]的目标是找到从状态到行动的映射(即策略),以最大限度地提高奖励。在每一次学习迭代中,代理都面临一个问题:是否实现了最大可能的奖励?在许多实际问题中,可实现的最大回报是未知的。即使在已知最大可实现回报的情况下,如果当前策略是次优的,那么代理也面临另一个问题:花时间改进当前策略会导致更高的回报(开发)吗?还是应该尝试不同的策略,希望发现潜在的更高回报(探索)?早熟开发类似于陷入局部最优,并阻止代理进行探索。另一方面,过多的探索可能会分散注意力,并阻止代理完善一个好的策略。因此,解决探索-开发困境[1]对于数据/时间有效的政策学习至关重要。在行动不影响状态的简单决策问题中(例如土匪或情境土匪[2]),已知用于平衡勘探和开采的可证明最优算法[3,2]。然而,在使用RL的一般设置中,这样的算法是未知的。在缺乏在理论和实践中都能很好地工作的方法的情况下,最先进的RL算法依赖于启发式探索策略,例如向动作添加噪声或次优动作的随机采样(例如,ε-贪婪)。然而,这种策略在稀疏奖励的情况下失败了,因为稀疏奖励阻碍了政策的改进。其中一项任务就是臭名昭著的ATARI游戏《蒙特祖玛的复仇》。