

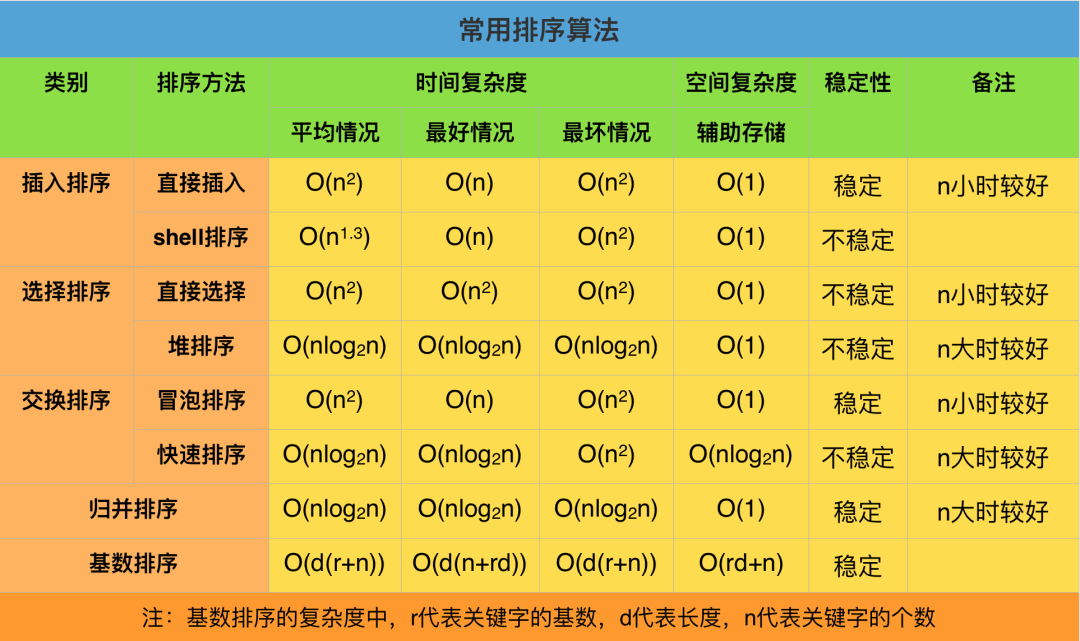
【前言】数字社会正在推动对计算和能源使用的需求不断增加。 在过去的五年里,我们依靠硬件的改进来跟上步伐。 但随着微芯片接近其物理极限,改进在其上运行的代码以使计算更加强大和可持续发展至关重要。 这对于组成每天运行数万亿次的代码的算法来说尤为重要。排序是一种按特定顺序组织多个项目的方法,示例包括按字母顺序排列三个字母,将五个数字从大到小排列,或对包含数百万条记录的数据库进行排序。这种方法在历史上不断发展。最早的例子之一可以追溯到二世纪和三世纪,当时学者们在亚历山大大图书馆的书架上用手将数千本书按字母顺序排列。工业革命之后,发明了有助于分类的机器——制表机将信息存储在打孔卡上,这些打孔卡用于收集美国 1890 年的人口普查结果。
随着 1950 年代商用计算机的兴起,我们看到了最早用于排序的计算机科学算法的发展。今天,世界各地的代码库中使用了许多不同的排序技术和算法来在线组织大量数据,说起排序,很多人大概第一时间想起的是下图
今天要介绍的是,Google DeepMind 推出了 AlphaDev,一种利用强化学习来发现改进的计算机科学算法的人工智能系统,其自主构建的算法,超越了科学家和工程师几十年来打磨出来的算法,将一种每天在世界各地使用数万亿次的 C++ 算法的运行速度提高了70%。
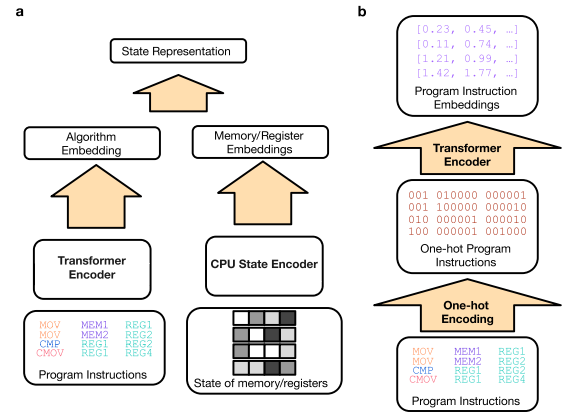
AlphaDev 表示网络架构。(a) AlphaDev 表示网络包含一个 Transformer Encoder 网络,该网络接收迄今为止生成的组装算法作为输入。它还包含一个 CPU 状态编码器网络,该网络接收内存和寄存器的当前状态作为输入。确切的架构和超参数可以在补充信息附录 A 中找到。(b) 在将指令输入到 Transformer 编码器网络之前,每个程序指令的操作码和操作数都被转换为单热编码并连接起来。然后将生成的编码馈入 Transformer Encoder 网络。
AlphaDev 发现了一种更快的排序算法,一种对数据进行排序的方法。数十亿人每天都在不知不觉中使用这些算法。它们支撑着一切,从在线搜索结果和社交帖子的排名到数据在计算机和手机上的处理方式。使用 AI 生成更好的算法将改变我们对计算机进行编程的方式,并影响我们日益数字化的社会的各个方面。
排序原理与研发思路
当代算法需要计算机科学家和程序员数十年的研究才能开发出来。它们的效率如此之高,以至于进一步改进是一项重大挑战,类似于试图找到一种新的节电方法或更有效的数学方法。这些算法也是计算机科学的基石,在大学的计算机科学入门课程中讲授。
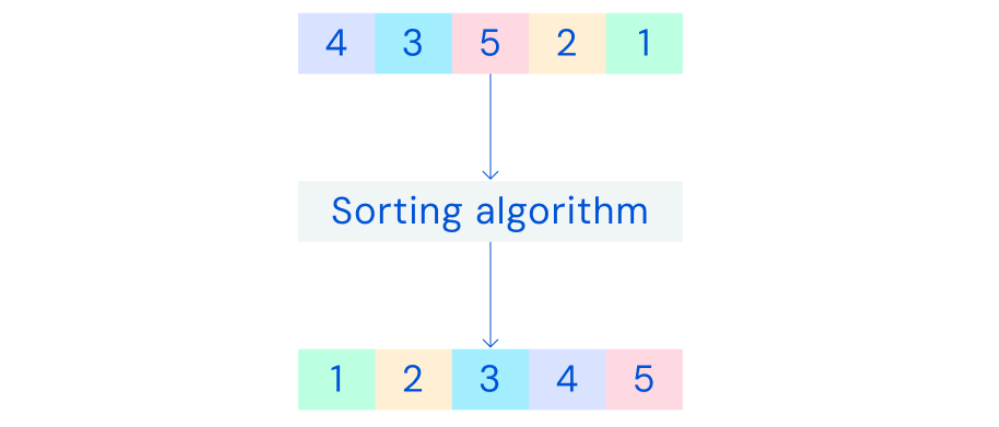
说明排序算法的作用。将一系列未排序的数字输入算法,并输出排序后的数字。
AlphaDev 通过从头开始而不是改进现有算法来发现更快的算法,并开始寻找大多数人不关注的地方:计算机的汇编指令。汇编指令用于为计算机创建二进制代码以执行操作。虽然开发人员使用 C++ 等被称为高级语言的编码语言编写代码,但必须将其翻译成“低级”汇编指令才能让计算机理解。而这些改进可能很难在较高层次的编码语言中发现。在此级别上,计算机存储和操作更加灵活,这意味着有更多潜在的改进可能对速度和能源使用产生更大的影响。
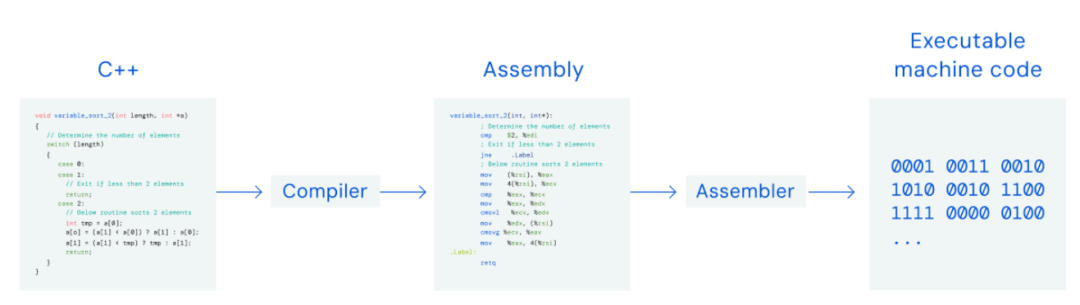
代码通常是用高级编程语言(例如 C++)编写的。然后使用编译器将其翻译成低级 CPU 指令,称为汇编指令。然后汇编程序将汇编指令转换为计算机可以运行的可执行机器代码。

这个汇编游戏非常困难,因为 AlphaDev必须有效地搜索大量可能的指令组合,以找到一种比当前最佳算法更快的排序算法。可能的指令组合的数量与宇宙中的粒子数量或国际象棋和围棋中可能的行动组合数量相似,一次错误的行动就可能会导致整个算法无效。
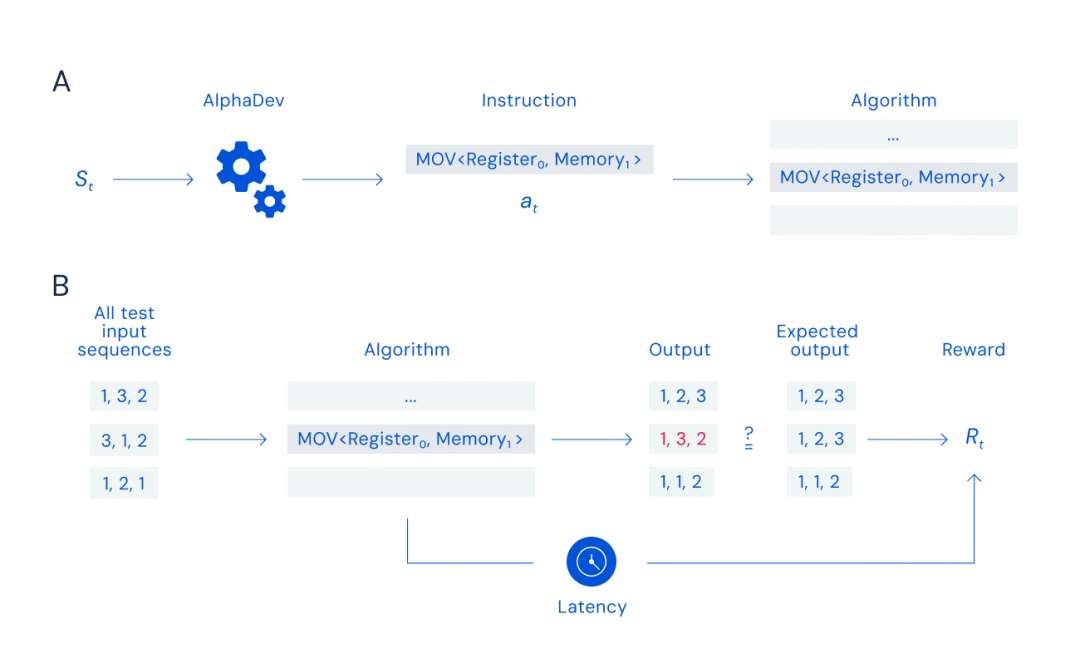
在构建算法时,AlphaDev 逐步添加一条指令,并通过将算法的输出与期望结果进行比较来验证其正确性。对于排序算法来说,这意味着无序的数字输入,正确排序的数字输出。Google DeepMind 根据 AlphaDev 正确排序数字的能力以及完成排序的速度和效率来奖励它。AlphaDev 通过发现一个正确且更快的程序来赢得游戏。
最终,AlphaDev 构建了一个新算法,对于 5 个数据的列表,它比最好的算法快 70%,对于超过 25 万个项目的列表,它比最好的算法快 1.7%。
AlphaDev 不仅找到了更快的算法,而且还发现了新颖的方法。它的排序算法包含新的指令序列,每次应用它们时都会保存一条指令。这可能会产生巨大的影响,因为这些算法每天被使用数万亿次。
我们称这些为“AlphaDev 交换和复制移动”。这种新颖的方法让人想起 AlphaGo 的“第 37 步”——一种违反直觉的下法让旁观者震惊,并导致了一位传奇围棋选手的失败。通过交换和复制移动,AlphaDev 跳过了一个步骤,以一种看似错误但实际上是捷径的方式连接项目。这显示了 AlphaDev 发现原始解决方案的能力,并挑战了我们思考如何改进计算机科学算法的方式。


深度强化学习如何应用
作者使用深度强化学习的方法将程序合成问题视为由单个玩家玩的游戏:程序合成器,作者称之为 AlphaDev。在游戏的每一步,合成器都必须选择一个与添加到程序中的指令相对应的动作。每走一步,系统都会通过在处理器上运行指令做出响应,然后检查结果是否正确。如果是,算法会根据程序的表现分配奖励。这种方法的强大之处在于,系统可以根据奖励信号学习生成高效程序,而无需来自训练示例的任何指导。也许令人惊讶的是,它导致了对像排序项目列表这样简单和基本的任务的方法的真正创新(如图)。
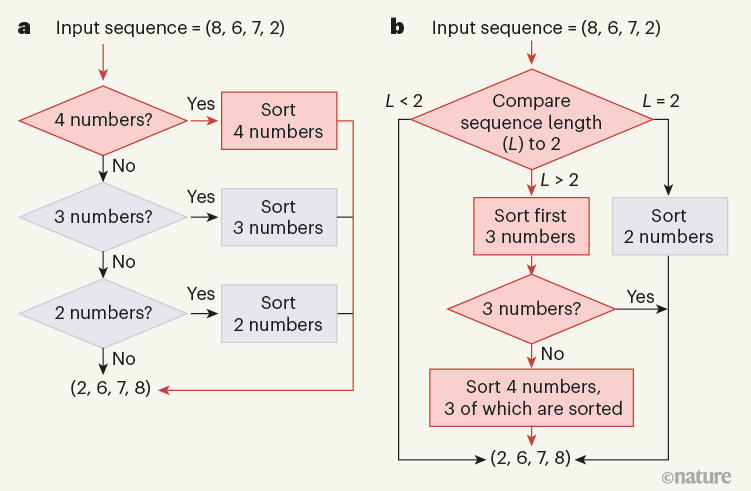
图 1 | 人工智能生成的排序方法。Mankowitz 等人 1 使用深度强化学习来提高 C++ 编程语言对列表中的项目进行排序的效率。作者的算法使用基于奖励的系统,不需要任何针对特定问题的训练。在一组实验中,该算法侧重于生成对短数字序列进行排序的例程,然后将其用作构建块来对较长序列进行排序。a,这是一种对最多包含四个数字的序列进行排序的方法,涉及三个单独的例程,用于对两个、三个或四个数字进行排序。红色突出显示对示例序列 (8, 6, 7, 2) 进行排序所采用的路径。b,Mankowitz 及其同事的算法生成了一个不同的过程——通过首先对前三个元素进行排序来递增地对长度为 4 的序列进行排序。这种排序方法现在是全球使用的标准 C++ 库的一部分。(改编自参考文献 1 的图 4。)
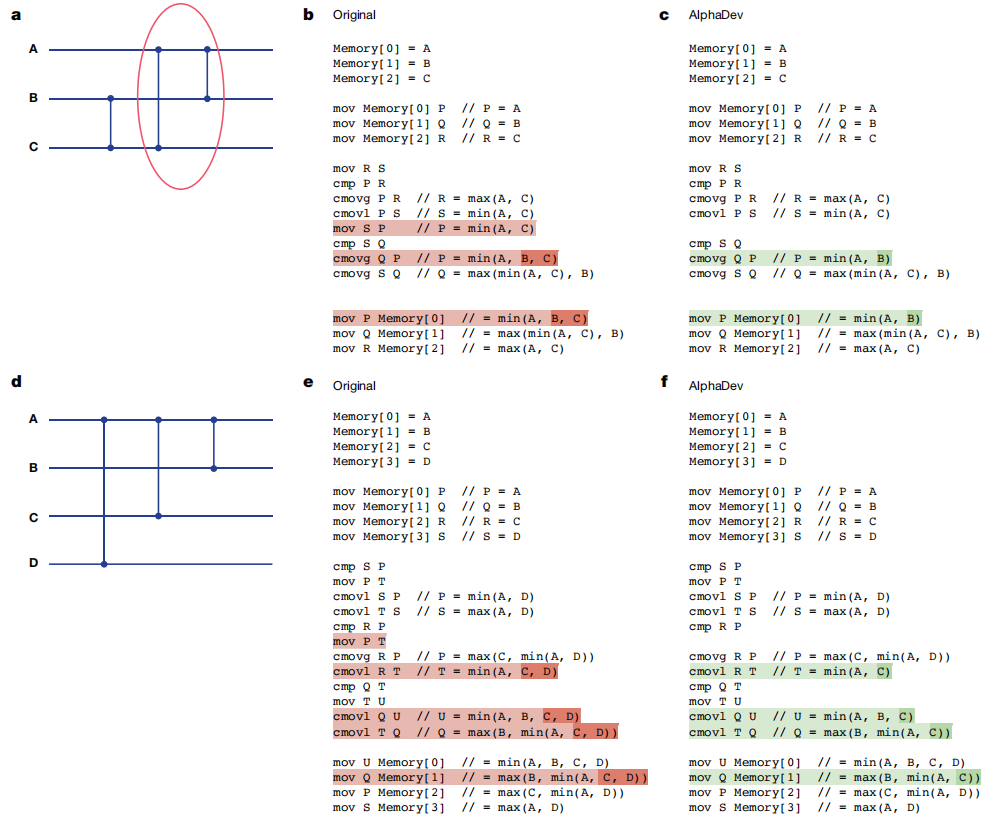
AlphaDev 发现的排序网络和算法改进。a,三个输入的最佳经典排序网络。带圆圈的比较器已由 AlphaDev 改进。有关更多详细信息,请参阅 AlphaDev 交换移动。b,c,应用 AlphaDev 交换移动之前 (b) 和应用 AlphaDev 交换移动之后 (c) 的汇编伪代码,导致删除了一条指令。d,AlphaDev 改进的最佳经典排序网络比较器配置。有关详细信息,请参阅 AlphaDev 复制移动。e,f,应用 AlphaDev 复制移动之前 (e) 和应用 AlphaDev 复制移动之后 (f) 的汇编伪代码,导致删除了一条指令。
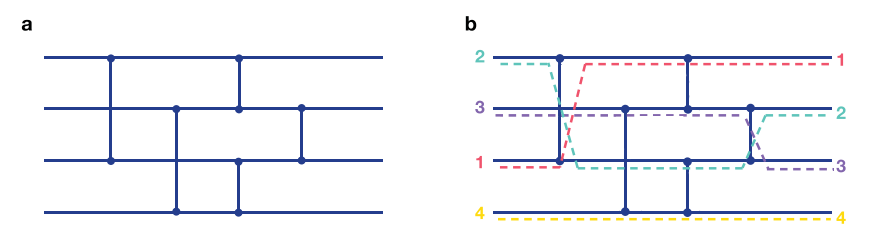
排序网络示例 .(a) 水平线称为线,垂直线称为比较器。(b) 一个最初未排序的值序列被输入到左侧的排序网络中。在不同的阶段,两条线遇到一个比较器。如果比较器顶部的值小于比较器底部的值,则数字切换线。最佳排序网络将比较器放置在特定位置,以便使用最少数量的比较器对任何未排序值序列进行排序。
排序网络。排序网络非常高效,因为它们的结构可以在现代 CPU 架构上并行化。因此,与流行且高效的基本案例算法(如插入排序)相比,它们往往会实现更快的运行时性能,尤其是在小排序上。分类网络由两种类型的项目组成,称为比较器(垂直线)和电线(水平线)(扩展数据图 2a)。每根电线从左到右携带一个值。当两条线在比较器处相交时,将比较两条线上的值。如果底部导线的值小于顶部导线的值,则值将在导线之间交换,如扩展数据图 2b 所示。排序网络的编程实现包括以特定顺序对输入序列中的特定元素对执行这些交换。
动作剪枝规则。我们通过删除一些程序不变性来修剪动作空间(例如,寄存器分配的顺序)和非法指令(例如,比较两个内存位置)。这有助于减少动作空间的大小并提高收敛速度。对于我们的实验中,我们使用了以下规则:
训练资源方面。 在处理单元 (TPU) v.3 上训练 AlphaDev,每个 TPU 核心的总批处理大小为 1,024。 我们使用多达 16 个 TPU 核心并训练 100 万次迭代。 在演员方面,游戏在独立的 TPU v.4 上进行,我们使用了多达 512 个演员。 实际上,在所有任务中,训练在最坏的情况下需要 2 天才能收敛。
AlphaDev-S。与其他可能的程序优化方法相比,了解 RL 的优点和局限性很重要。因此,实施了最先进的随机超级优化方法,并将其作为学习算法纳入 AlphaDev 以优化排序功能。将此改编版本称为 AlphaDev-S。我们的重新实现已针对排序域进行了专门优化。这包括实施算法以在我们的装配环境中运行,定义特定于排序的正确性和性能损失函数,以及运行大量超参数扫描以识别最佳变体。用于 AlphaDev-S 的成本函数是 c =⟩correctness⟩+ α ×⟩performance,其中正确性对应于计算仍未排序的不正确输入序列元素的数量,性能对应于算法长度奖励,α 是权衡这两个成本的权重 功能。我们无法直接针对延迟进行优化,因为这会大大减慢学习算法,使学习变得不可行。应该注意的是,此函数已经过调整以支持 AlphaDev 使用的同一组汇编指令,以及修剪同一组不正确或非法的操作。它还使用相同的程序正确性计算模块(图 2b)来计算正确性项。然后通过首先提出对存储在缓冲区中的程序的转换来执行 AlphaDev-S(缓冲区可能为空或使用已排序的程序初始化)。然后分别使用程序正确性模块和算法长度计算正确性和性能项。如果成本低于当前最优成本,则新方案大概率被接受,否则拒绝。我们现在将更详细地讨论正确性成本函数和变换权重。
正确性成本。对于正确性成本函数,我们实现了三种类型的成本函数。第一个定义为错误放置项目的百分比: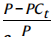 其中 P 是要放置的项目总数,PCt 是在时间步 t 正确放置的项目数。第二个变量是这个等式的平方根。最终成本函数取差值的平方根 −PCt,这就是产生最佳性能的原因。
其中 P 是要放置的项目总数,PCt 是在时间步 t 正确放置的项目数。第二个变量是这个等式的平方根。最终成本函数取差值的平方根 −PCt,这就是产生最佳性能的原因。
实验结果数据
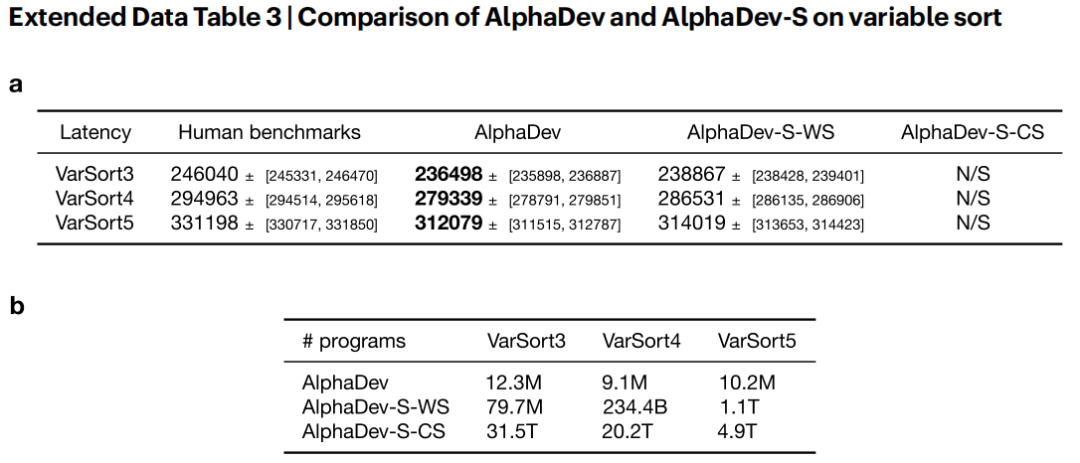
(a) 显示每种方法发现的程序的延迟结果。报告的延迟对应于在 100 台机器上测量的延迟的第 5 个百分位。±⟩[Lower, Upper] 分别报告置信区间的下限和上限。在此设置中,AlphaDev 直接针对真实的、测量的延迟进行优化。请注意,AlphaDev 优于每种方法,并且 AlphaDev-S-CS 无法在每种情况下找到解决方案。(b) 在可变排序设置中,与 AlphaDev 相比,AlphaDev-S 变体探索的程序数量级更多。
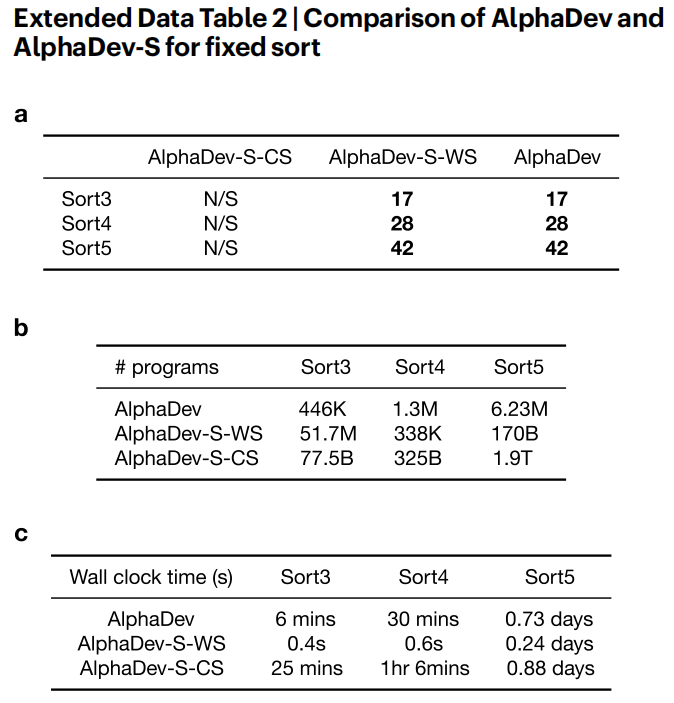
(a) 展示每种方法找到的最短程序。请注意,AlphaDev-S-CS 在从头开始训练时无法发现排序功能。AlphaDev-S-WS 使用接近最优的程序进行初始化,其性能能够与从头开始发现最优程序的 AlphaDev 的性能相媲美。(b) 表示为找到最佳解决方案,每种方法探索的程序数量。请注意,AlphaDev-S-CS 为每种排序算法探索了数量级更多的程序。对于排序 3 和排序 5,AlphaDev-S-WS 探索的程序比 AlphaDev 多几个数量级,以找到最佳解决方案。(c) 为每个排序长度生成最短程序的近似挂钟时间。对于无分支排序,AlphaDev-S-WS 比 AlphaDev 的计算效率更高。然而,正如扩展数据表 3 中所示,当引入分支时,AlphaDev 优于 AlphaDev-S-WS,后者往往会陷入局部最优解。
开放源代码
这次DeepMind直接开放源代码,下面是Github链接
https://github.com/deepmind/alphadev