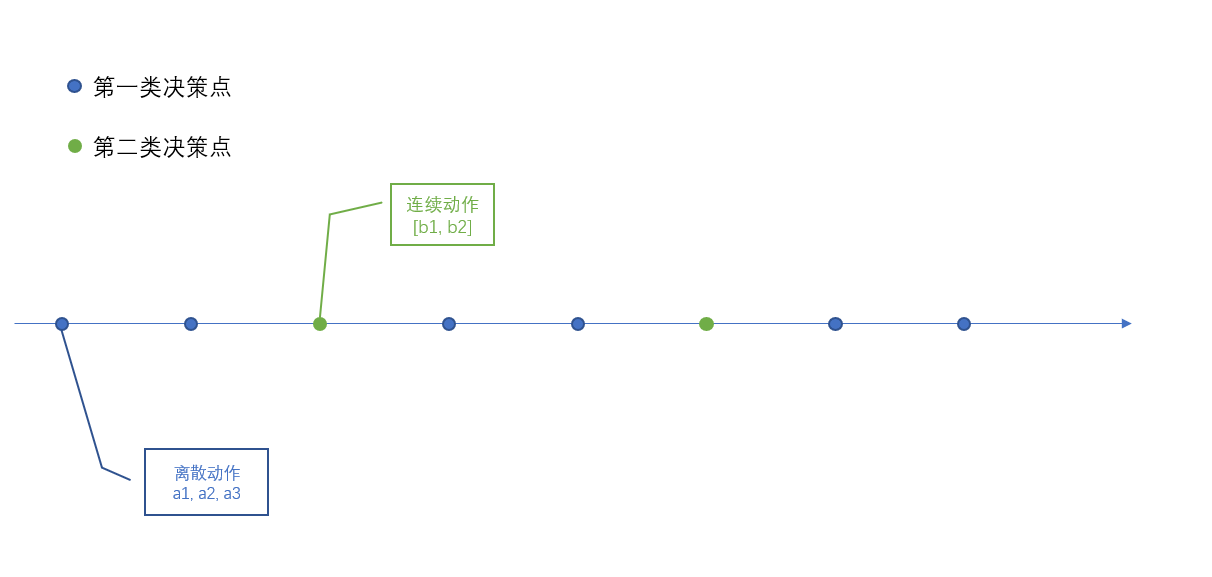
LlhlhRL 02023年6月16日发布 #1 2023年6月16日星期五 10点59分 同时存在两类决策点和两类动作,在第一类决策点要从离散状态中选择,每隔一段时间会出现第二类决策点,要从连续动作中做出选择,这种情况应该怎么处理两类动作,怎么设计强化学习算法呢
LLobsterRL 12023年6月18日发布 #2 2023年6月18日星期日 10点25分 可以尝试PDQN,PDPG算法,还有其他的一些用于混合动作空间的算法。 ref:Parametrized Deep Q-Network Learning Reinforcement Learning with Discrete-Continuous Hybrid Action Space