FinRL库包含微调的标准DRL算法,如 DQN, DDPG, Multi-Agent DDPG, PPO, SAC, A2C 和TD3。还允许用户通过调整这些DRL算法来设计自己的DRL算法。
在此解决方案中,我们使用TensorBoard Integration进行超参数调整和模型拾取。
total_timesteps(int):要训练的样本总数。
为了比较这些算法,我们将total_timesteps设置为100k。 如果将total_timesteps设置得太大,则将面临过度拟合的风险。
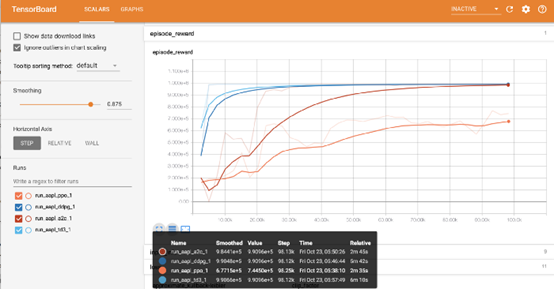
通过观察Episode_reward图表,我们可以看到随着步数的增加,这些算法最终将收敛到最优策略。 TD3收敛非常快。
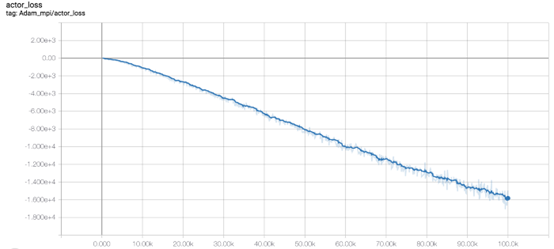
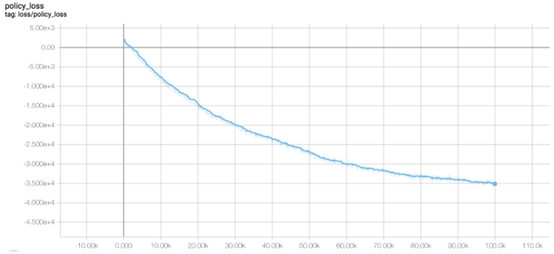
因此,这里我们选择TD3模型。
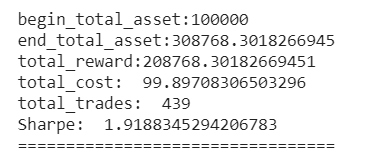
在交易设置时,假设我们在2019/01/01拥有$ 100,000的初始资本。 我们使用TD3模型来交易AAPL。
结果如图:
欢迎有兴趣的朋友查阅我们的项目:
源代码:https://github.com/AI4Finance-LLC/FinRL-Library
教程:https://towardsdatascience.com/finrl-for-quantitative-finance-tutorial-for-single-stock-trading-37d6d7c30aac