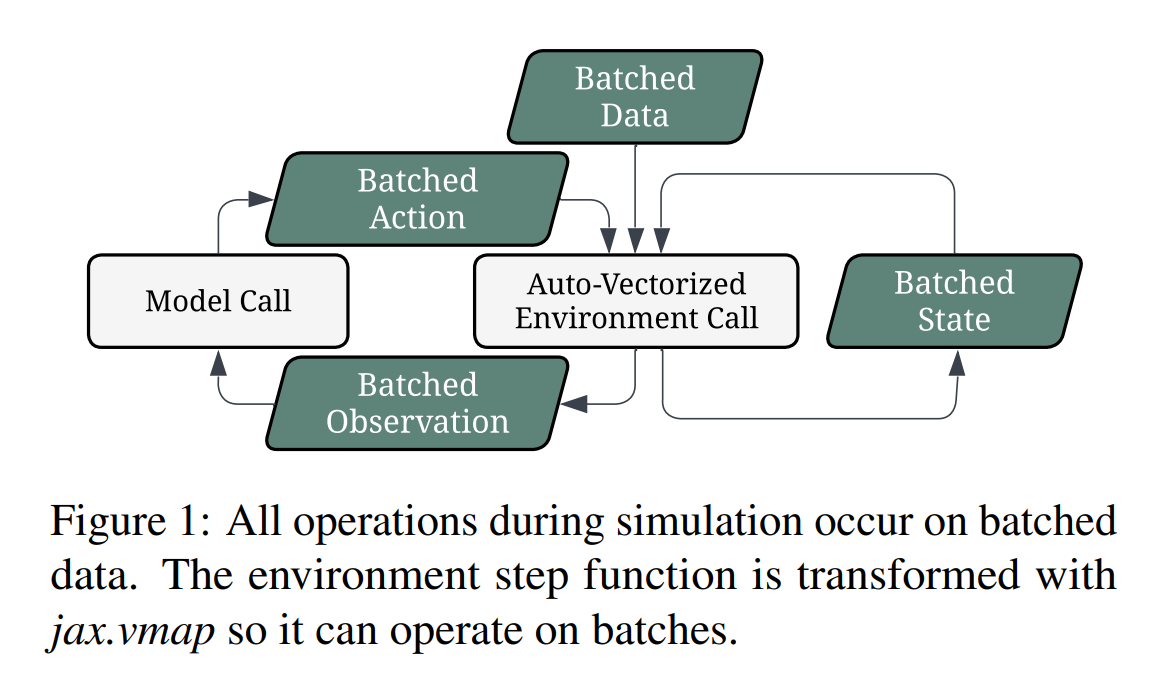
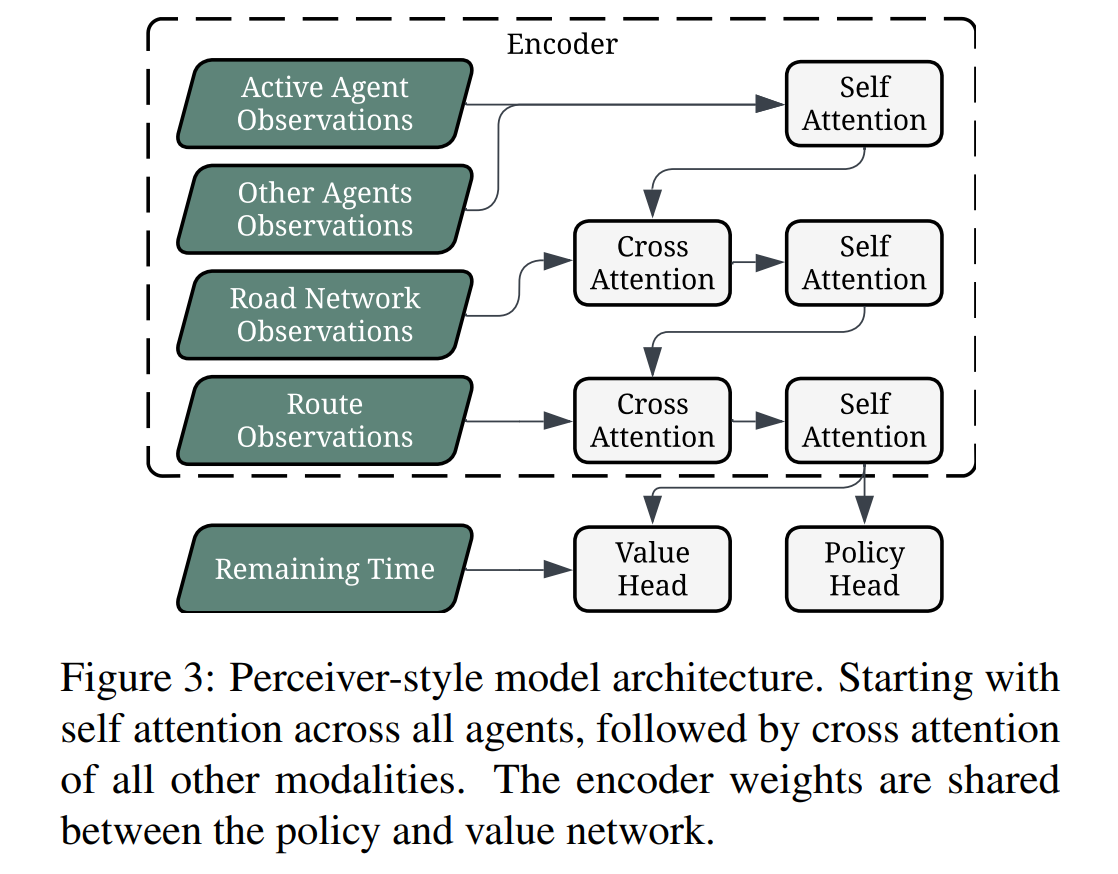
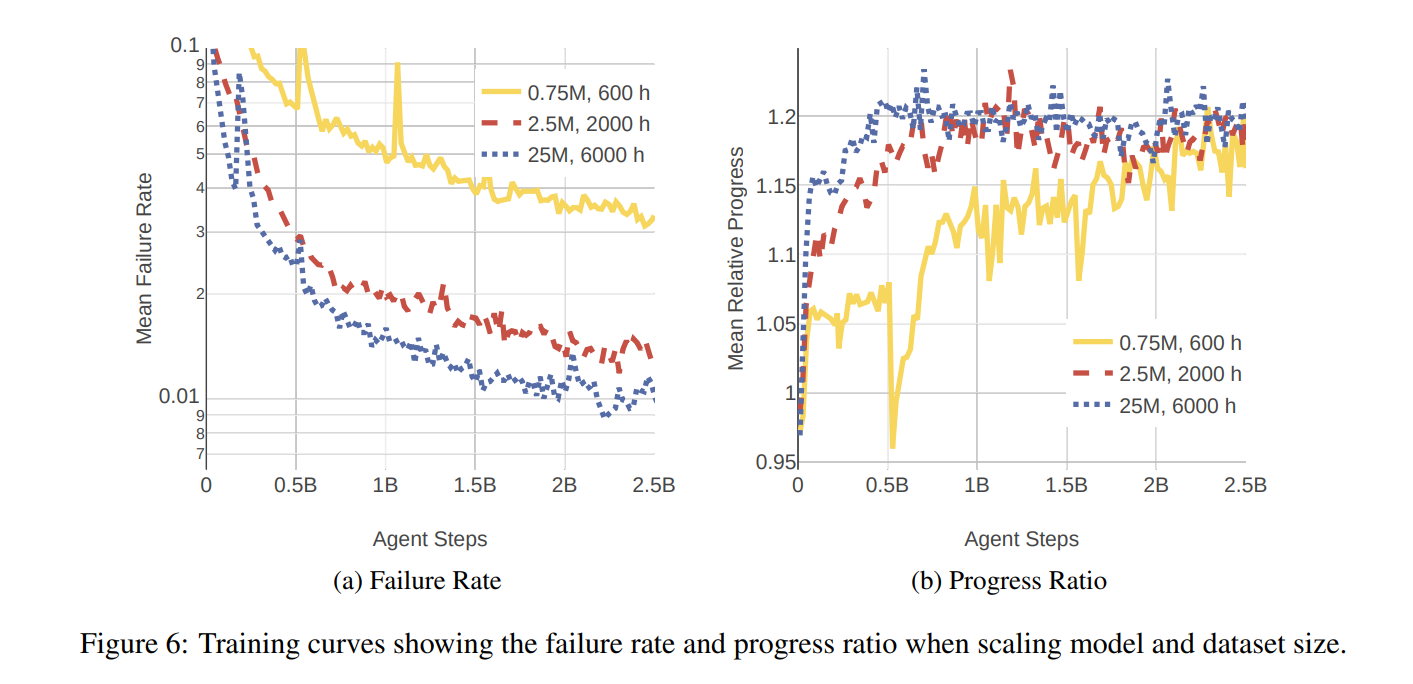
事实证明,在视频游戏等复杂领域,强化学习的表现甚至超越了最优秀的人类。 然而,在自动驾驶所需的规模上运行强化学习实验是极其困难的。 构建大规模强化学习系统并将其分布在许多 GPU 上是一项挑战。 从安全性和可扩展性的角度来看,在现实世界车辆的训练过程中收集经验是令人望而却步的。 因此,需要一个高效且真实的驾驶模拟器,该模拟器使用来自现实世界驾驶的大量数据。 我们将这些能力结合在一起,针对自动驾驶进行大规模的强化学习实验。 我们证明,我们的政策绩效随着规模的扩大而提高。 与最先进的自动驾驶机器学习生成的策略相比,我们表现最佳的策略将故障率降低了 64%,同时将驾驶进展率提高了 25%。