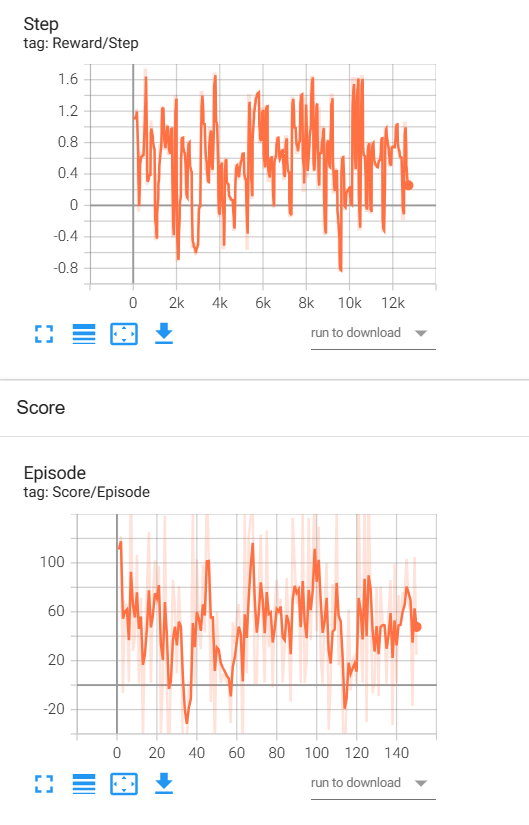
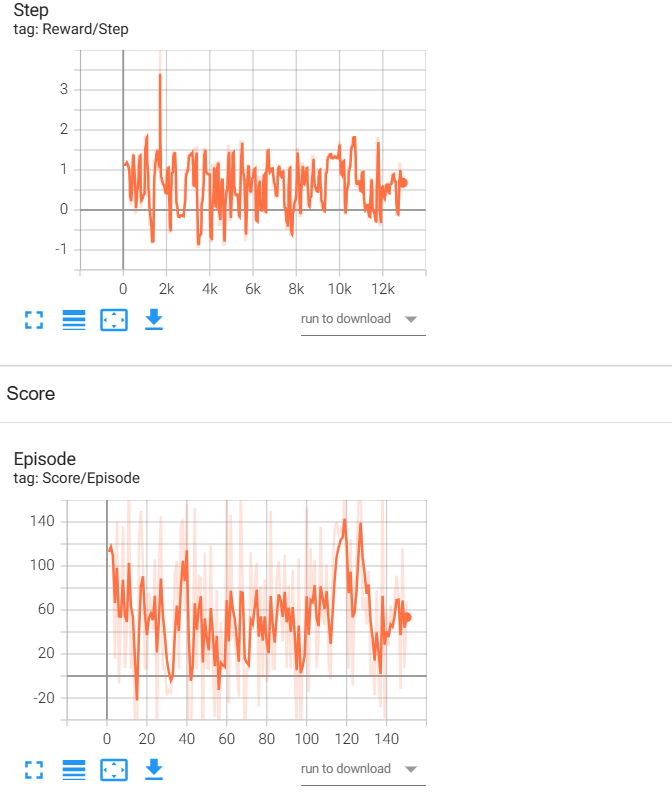
各位大哥 我用强化学习做一个关于电机的多目标优化。我有一个数据集,里面有6列数据,前四列是永磁电机的结构参数,比如长宽高啥的,后两列是转矩和转矩脉动。然后我用了一个深度神经网络去通过这些结构参数预测转矩和转矩脉动。然后保存模型,应用到强化学习中的step中。在强化学习环境里我自定义的动作空间是这些结构参数的范围,状态空间是转矩和转矩脉动的范围。然后在step中,动作先传入到这个DNN模型,然后预测出转矩和转矩脉动。然后在计算奖励。目的就是最大化转矩的同时使得转矩脉动减小。然后我用sac和dppg算法跑出的奖励是这样,用的是sb3跑的。调了好长时间一直不收敛。我不知道为啥。是哪里的逻辑出错了吗,请各位老师提点建议和意见。奖励函数我设计的是把转矩和转矩脉动通过范围归一化,然后拿转矩减去转矩脉动。分别给他们加权。但是效果好差。救救孩子吧,快崩溃了
这是相关代码。是不是因为我的转矩是七八百,转矩脉动是个位数,数量级差的太多了,才学不到东西啊 。各位大哥
[upl-image-preview url=http://www.deeprlhub.com/assets/files/2024-04-20/1713620500-226366-1.png
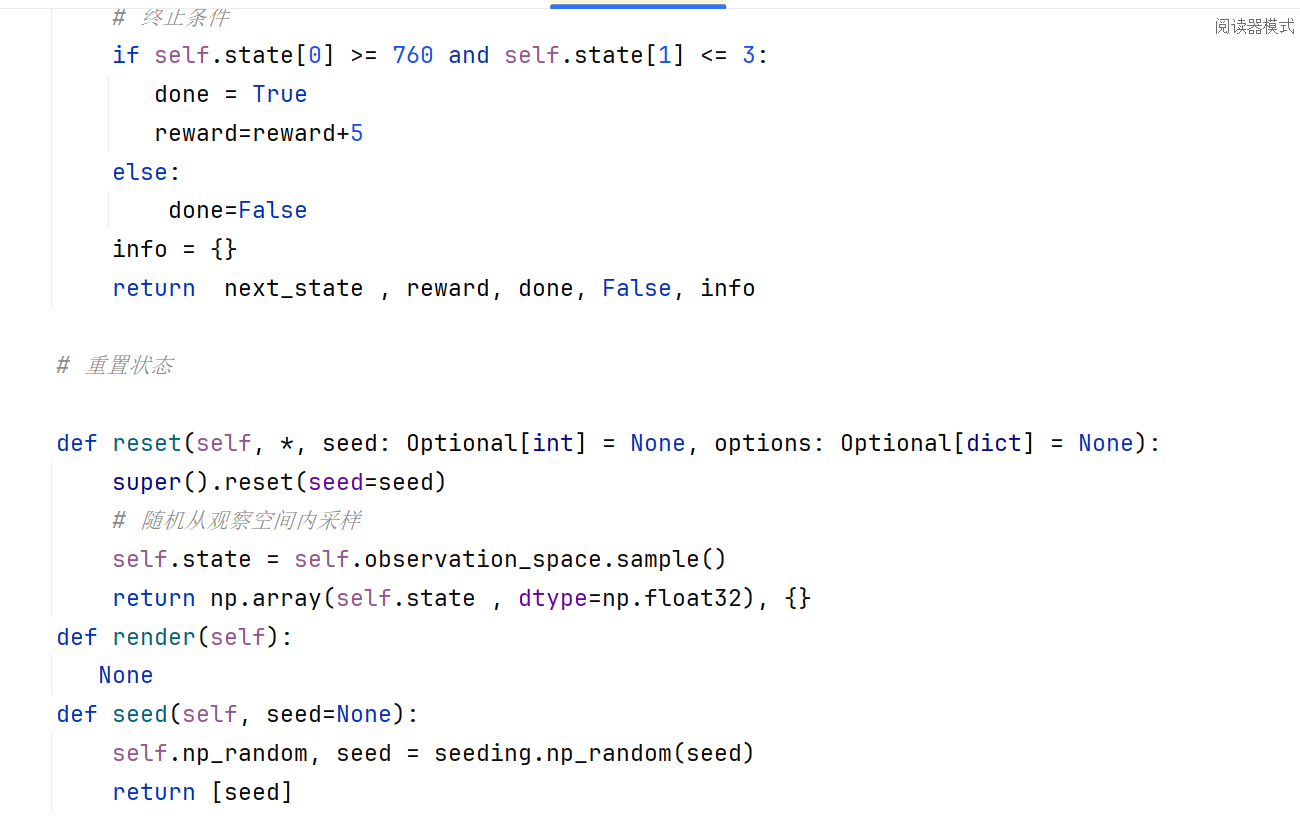
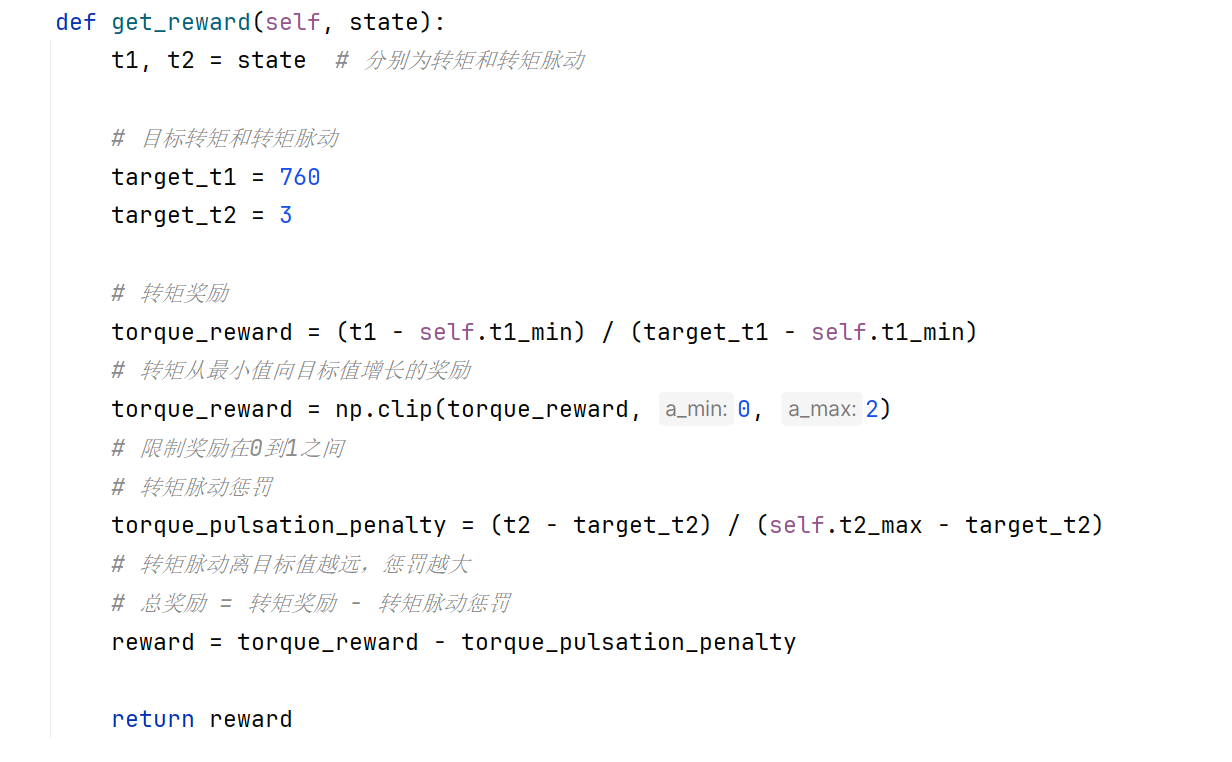
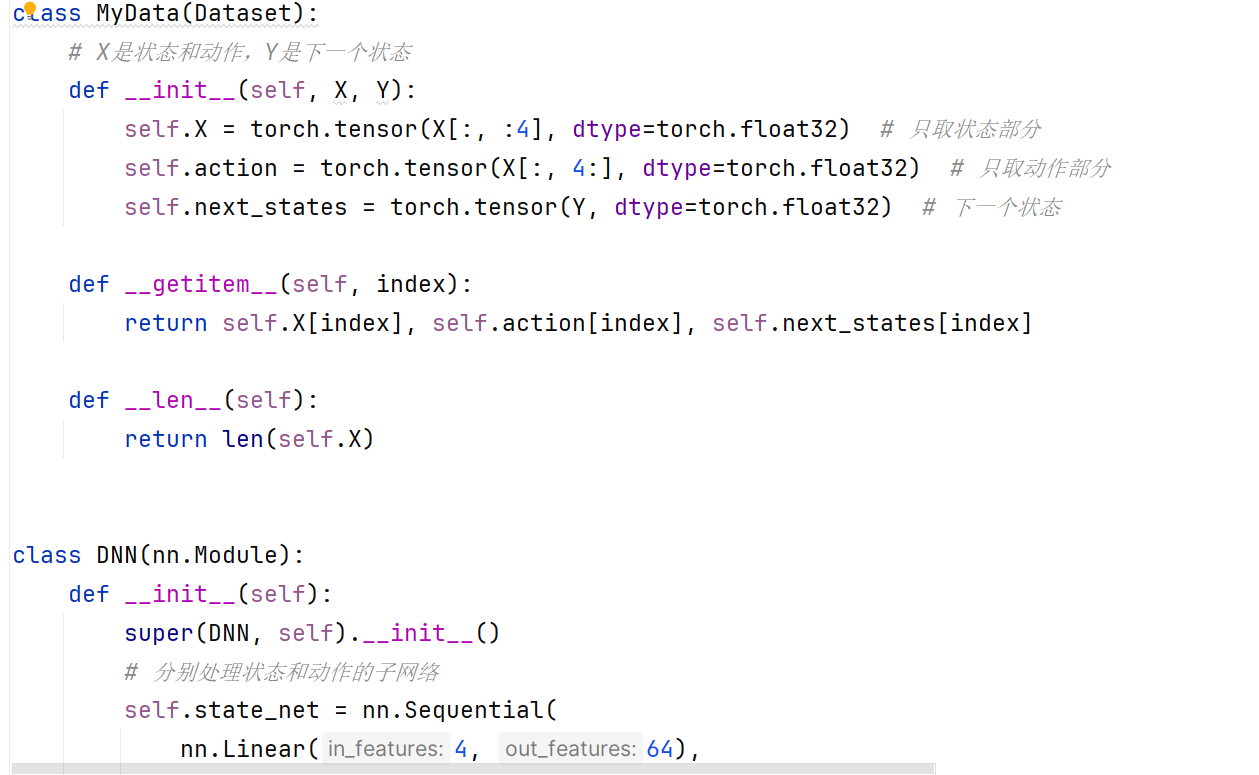
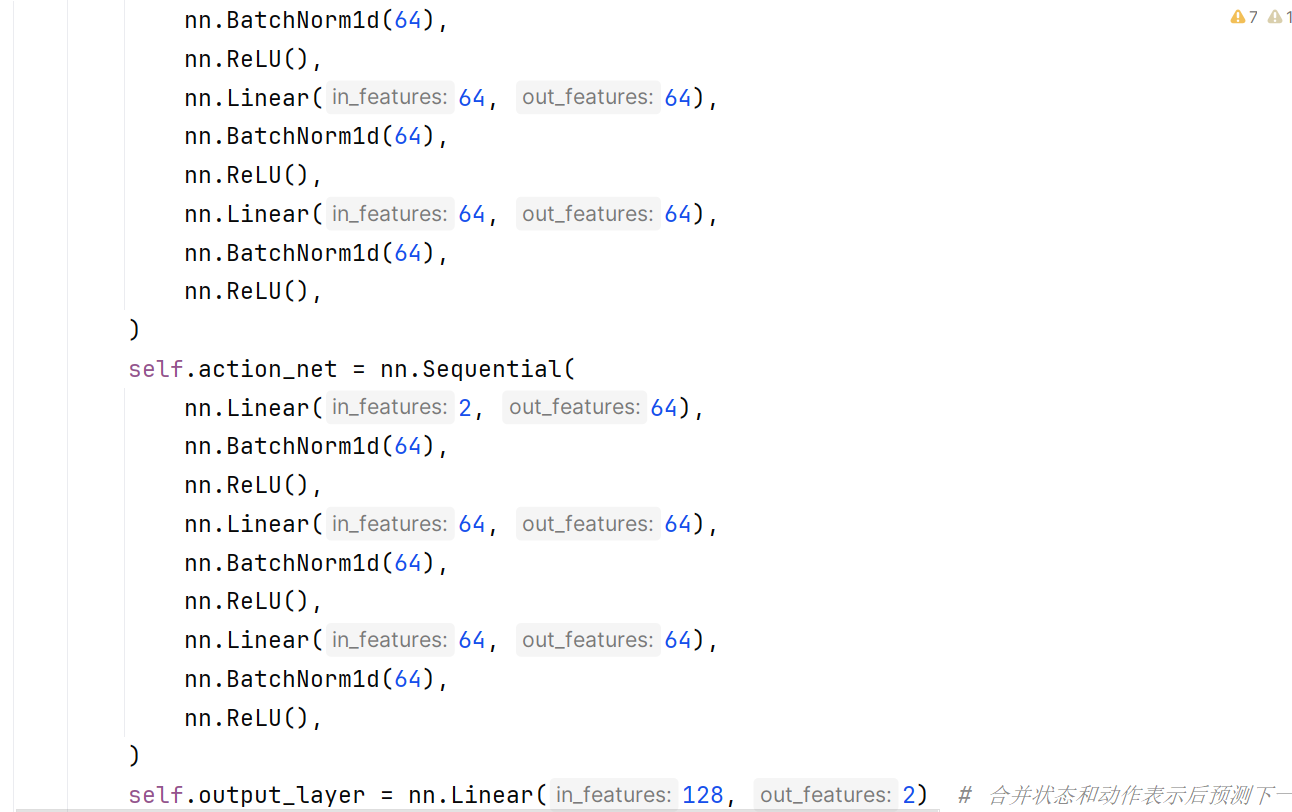

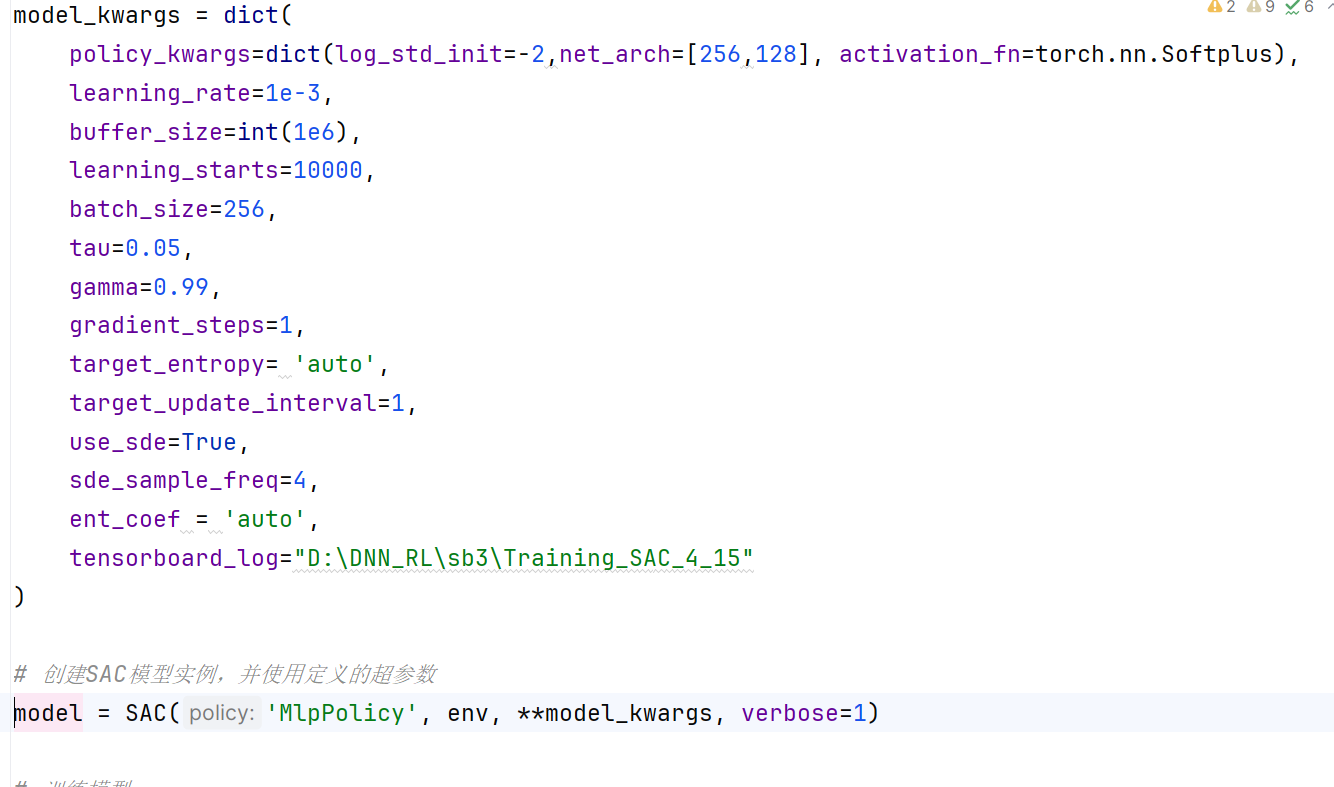
]