仅通过观察智能体在环境中的行为方式,很难了解其为何如此行为以及其内部如何工作。这就是为什么建立衡量代理以某种方式执行的原因至关重要的原因。
这是具有挑战性的,特别是当代理的行为方式与我们希望的方式不同时,……就像往常一样。每个人工智能从业者都知道,无论我们做什么,大多数时候它都不会简单地开箱即用(否则他们不会付给我们那么多钱)。
在这篇博文中,您将了解如何跟踪以检查/调试代理学习轨迹。我假设您已经熟悉强化学习 (RL) 代理环境设置(参见图 1),并且您至少听说过一些最常见的 RL算法和环境。
不过,如果您刚刚开始 RL 之旅,请不要担心。我尽量不过多依赖读者的先验知识,并且在无法省略某些细节的地方,我引用了有用的材料。
 图 1:强化学习框架(Sutton 和 Barto,2018)。
图 1:强化学习框架(Sutton 和 Barto,2018)。
我将首先讨论有用的指标,让我们了解代理的培训和决策过程。
然后我们将重点关注这些指标的聚合统计数据,例如平均值,这将帮助我们分析代理在整个训练过程中播放的许多剧集。这些将有助于从根源上解决代理的任何问题。
在每一步中,我都会根据自己在 RL 研究方面的经验提出建议。让我们直接开始吧!
我用来检查 RL 代理训练的指标
有多种类型的指标可供遵循,每种指标都为您提供有关模型性能的不同信息。这样研究人员就可以获得有关……的信息。
......代理做得怎么样
在这里,我们将仔细研究诊断代理整体性能的三个指标。
 资料来源:侠盗猎车手:圣安地列斯评论 xstevez
资料来源:侠盗猎车手:圣安地列斯评论 xstevez
剧集回归
这是我们最关心的。整个代理培训都是为了获得尽可能高的预期回报(见图 2)。如果这个指标在整个训练过程中不断上升,这是一个好兆头。


图 2:强化学习问题。找到最大化目标 J 的策略 π。目标 J 是环境动态 P 下的预期回报 E[R]。τ 是代理(或其策略 π)所发挥的轨迹。
然而,当我们知道预期回报是什么,或者什么是好的分数时,它对我们来说会更有用。
这就是为什么你应该始终寻找基线,其他结果在你工作的环境中,以将你的结果与它们进行比较。
随机代理基线通常是一个好的开始,它允许您重新校准,感受环境中真正的“零”分数 - 您只需通过插入控制器即可获得的最小回报(见图 3)。

 图 3. SimPLe论文中的表 3列出了 Atari 环境中的结果与许多基线以及随机代理和人类评分的比较。
图 3. SimPLe论文中的表 3列出了 Atari 环境中的结果与许多基线以及随机代理和人类评分的比较。
剧集长度
这是一个与剧集回报结合分析的有用指标。它告诉我们我们的代理在终止之前是否能够生存一段时间。在 MuJoCo 环境中,不同的生物学习行走(参见图 4),它会告诉您,例如,您的代理在翻转并重置到剧集开始之前是否做了一些动作。
图 4. 人形坠落 🙁 来源:2D 和 3D 双足运动强化学习技术调查
解决率
另一个用于分析剧集回报的指标。如果您的环境有一个要解决的概念,那么检查它可以解决多少个情节会很有用。例如,在推箱子中(见图 5),将盒子推向目标会获得部分奖励。话虽这么说,只有当所有盒子都在目标上时,房间才能解决。

图 5. Sokoban 是一个运输谜题,玩家必须将房间中的所有盒子推到存储目标上。
因此,智能体有可能获得积极的情节回报,但仍然没有完成需要解决的任务。
另一个例子是 Google Research Football(见图 6)及其学院。朝着对手的目标迈进会有一些部分奖励,但只有当特工的球队进球时,学院情节(例如,以较小的小组进行反击情况)才被视为“已解决”。
 图 6. Google Research Football,“学院传球和射门”环境****
图 6. Google Research Football,“学院传球和射门”环境****
…训练进度
有多种方式来表示“时间”的概念以及衡量强化学习进展的指标。以下是前 4 个精选。
总环境步骤
这个简单的指标告诉您代理已经收集了多少经验(在环境步骤或时间步骤方面)。这通常比挂墙时间更能提供训练进度(步骤)的信息,挂墙时间很大程度上取决于您的机器模拟环境和在神经网络上进行计算的速度(参见图 6)。

 图 7. MuJoCo Ant 环境中的 DDPG 训练。两次运行都花费了 24 小时,但是在不同的机器上。一个完成了约 500 万步,另一个完成了约 950 万步。对于后者来说,这时间已经足够收敛了。对于前者则不然,而且得分更差。
图 7. MuJoCo Ant 环境中的 DDPG 训练。两次运行都花费了 24 小时,但是在不同的机器上。一个完成了约 500 万步,另一个完成了约 950 万步。对于后者来说,这时间已经足够收敛了。对于前者则不然,而且得分更差。
此外,我们报告最终的智能体得分以及训练它所需的环境步骤(通常称为样本)。样本越少,得分越高,代理的样本效率越高。
训练步骤
我们使用随机梯度下降 (SGD) 算法训练神经网络(请参阅深度学习书籍)。
训练步骤指标告诉我们对网络进行了多少批量更新。当从离策略重播缓冲区进行训练时,我们可以将其与总环境步骤进行匹配,以便更好地了解平均而言,将环境中的每个样本显示给网络以从中学习的次数:

批量大小 * 训练步骤 / 总环境步骤 = 批量大小 / 部署长度
其中rollout length是我们在训练步骤之间的数据收集阶段(当数据收集和训练按顺序运行时)平均收集的新时间步数。
上述比率(有时称为训练强度)不应低于 1,因为这意味着某些样本甚至不会向网络显示一次!事实上,它应该远高于 1,例如 256(如DDPG的 RLlib 实现中设置的,查找“训练强度”)。
挂墙时间
这只是告诉我们实验运行了多少时间。
当我们将来计划需要多少时间来完成每个实验时,它会很有用:
2-3小时?
整晚??
或者几天???
一整周?!?!?!
是的,有些实验甚至可能需要在您的电脑上花费整整一周的时间才能完全收敛或训练到您使用的方法可以实现的最大集返回值。
值得庆幸的是,在开发阶段,较短的实验(几个小时,最多 24 小时)在大多数情况下足以简单地判断代理是否正常工作或测试一些改进想法。
请注意,您总是希望以这样的方式计划您的工作,即当您处理其他事情(例如编码、阅读、写作、思考等)时,一些实验在后台运行。
这就是为什么一些仅用于运行实验的专用工作站可能有用的原因。
每秒步数
代理每秒执行多少个环境步骤。通过该值的平均值,您可以计算运行一定数量的环境步骤所需的时间。
…代理在想什么/在做什么
最后,让我们看看智能体的大脑内部。在我的研究中(取决于项目),我使用价值函数和策略熵来了解正在发生的事情。
状态/动作值函数
Q-learning 和 actor-critic 方法利用价值函数(VF)。
查看它们预测的值以检测某些异常情况并了解代理如何评估其在环境中的胜算非常有用。
在最简单的情况下,我记录每个情节时间步长的网络状态值估计,然后对整个情节进行平均(下一节将详细介绍)。通过更多的训练,该指标应该开始与记录的情节返回相匹配(参见图 7),或者更常见的是,当它用于训练 VF 时,会匹配折扣情节返回。如果没有,那就是一个坏兆头。
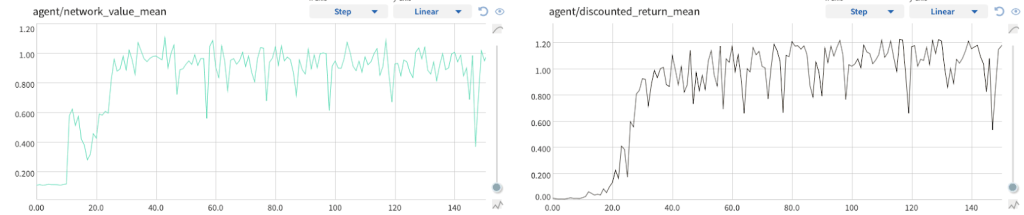 图 8. Google Research Football 环境中的实验。随着时间的推移,随着智能体的训练,智能体的价值函数与情节返回平均值相匹配。
图 8. Google Research Football 环境中的实验。随着时间的推移,随着智能体的训练,智能体的价值函数与情节返回平均值相匹配。
此外,在 VF 值图表上,我们可以看到是否需要进行一些额外的数据处理。
例如,在 Cart Pole 环境中,代理在每个时间步都会获得 1 的奖励,直到跌倒并死亡。剧集的回归很快就达到了数十甚至数百的数量级。 VF 网络的初始化方式是在训练开始时输出零左右的小值,因此很难捕获此范围的值(参见图 8)。
这就是为什么在训练之前需要进行一些额外的返回归一化。最简单的方法是简单地除以可能的最大回报,但不知何故,我们可能不知道什么是最大回报,或者不存在这样的回报(参见MuZero论文中的 Q 值归一化,附录 B – 备份)。
 图 9. Cart Pole 环境中的实验。价值函数目标没有标准化,很难赶上它。
图 9. Cart Pole 环境中的实验。价值函数目标没有标准化,很难赶上它。
我将在下一节中讨论一个示例,这个特定的度量联合与极端聚合帮助我检测代码中的错误。
政策熵
因为一些强化学习方法使用随机策略,所以我们可以计算它们的熵:它们的随机程度。即使使用确定性策略,我们也经常使用 epsilon-greedy 探索性策略,我们仍然可以计算熵。

策略熵 H 的方程,其中 a 是动作,p(a) 是动作概率。
最大熵值等于ln(N),其中N是动作的数量,这意味着策略均匀随机地选择动作。最小熵值等于 0,这意味着始终只有一个动作是可能的(概率为 100%)。
如果您观察到代理策略的熵迅速下降,那么这是一个坏兆头。这意味着你的代理很快就会停止探索。如果您使用随机策略,您应该考虑一些熵正则化方法(例如Soft Actor-Critic)。如果您将确定性策略与 epsilon-greedy 探索性策略一起使用,则可能您对 epsilon 衰减使用了过于激进的计划。
......培训进行得如何
最后但并非最不重要的一点是,我们有一些更标准的深度学习指标。
KL散度
像Vanilla Pol i cy Gradient (VPG)这样的 on-policy 方法会根据从当前策略中采样的批量经验进行训练(它们不使用任何带有经验的重放缓冲区来进行训练)。
这意味着我们所做的事情对我们学到的东西有很大的影响。如果您将学习率设置得太高,那么近似梯度更新可能会在某些看似有希望的方向上采取太大的步骤,这可能会将代理推入状态空间的最差区域。
因此,代理的表现将比更新前更差(参见图 9)!这就是为什么我们需要监控新旧政策之间的 KL 差异。它可以帮助我们设置学习率等。


图 10. Cart Pole 环境中的 VPG 训练。在 y 轴上,我们有一个剧集长度(它等于此环境中的剧集返回)。橙色线是得分的滑动窗口平均值。左图,学习率太大,训练不稳定。在右图中,学习率被适当地微调(我手动找到的)。
KL 散度是两个分布之间距离的度量。在我们的例子中,这些是动作分布(策略)。我们不希望我们的政策在更新前后有太大差异。有像PP O这样的方法对 KL 散度施加了约束,并且根本不允许太大的更新!
网络权重/梯度/激活直方图
记录每层的激活、梯度和权重直方图可以帮助您监控人工神经网络训练动态。您应该寻找以下迹象:
Dying ReLU:
如果 ReLU 神经元在前向传递中被钳位为零,那么它在后向传递中将不会获得梯度信号。甚至可能发生这样的情况:由于训练过程中不幸的初始化或太大的更新,某些神经元不会对任何输入感到兴奋(返回非零输出)。
“有时,您可以通过经过训练的网络转发整个训练集(即 RL 中的重播缓冲区),并发现很大一部分(例如 40%)的神经元始终为零。” ~[是的,你应该了解](https://medium.com/@karpathy/yes-you-should-understand-backprop-e2f06eab496b)Andrej Karpathy 的反向传播
梯度消失或爆炸:
非常大的梯度更新值可能表示梯度爆炸。渐变裁剪可能会有所帮助。
另一方面,非常低的梯度更新值可能表明梯度消失。使用ReLU 激活和Glorot 统一初始化器(又名 Xavier 统一初始化器)应该会有所帮助。
消失或爆炸激活:
激活的良好标准偏差约为 0.5 到 2.0。明显超出此范围可能表示激活消失或爆炸,这反过来可能会导致梯度问题。尝试层/批量归一化以控制激活分布。
一般来说,层权重(和激活)的分布接近正态分布(值在零附近,没有太多异常值)是健康训练的标志。
上述提示应该可以帮助您通过培训保持网络健康。
政策/价值/质量/……水头损失
尽管我们确实优化了一些损失函数来训练代理,但您应该知道这不是典型意义上的损失函数。具体来说,它与监督学习中使用的损失函数不同。
我们优化图 2 中的目标。为此,您可以在策略梯度方法中导出该目标的梯度(称为策略梯度)。然而,由于 TensorFlow 和其他深度学习框架是围绕自动梯度构建的,因此您可以将损失函数定义为您的损失函数,在自动梯度运行后,它会产生等于策略梯度的梯度。
请注意,数据分布取决于策略并随训练而变化。这意味着损失函数不必单调递减才能进行训练。当代理发现状态空间的某些新区域时,它有时会增加(参见图 10)。
 图 11. MuJoCo 人形环境中的 SAC 训练。当剧集回报开始上升(我们的智能体学习成功)时,Q 函数损失也会上升!一段时间后它又开始下降。
图 11. MuJoCo 人形环境中的 SAC 训练。当剧集回报开始上升(我们的智能体学习成功)时,Q 函数损失也会上升!一段时间后它又开始下降。
而且,它并不能衡量代理的绩效!特工的真实表现是一集回归。记录损失作为健全性检查很有用。但是,不要根据训练进度来做出判断。
汇总统计数据
当然,对于某些指标(例如状态/操作值),不可能为每个实验的每个环境时间步长记录它们。通常,您会计算每一集或几集的统计数据。
对于其他指标,我们处理随机性(例如,当环境和/或策略随机时,事件返回)。因此,我们必须使用采样来估计预期的度量值(样本=事件返回情况下的一个代理事件)。
无论哪种情况,汇总统计数据都是解决方案!
平均值和标准差
当您处理随机环境(例如 PacMan 中的幽灵随机行动)和/或您的策略随机绘制操作(例如 VPG 中的随机策略)时,您应该:
播放多集(10-20 集就可以了),
他们的平均指标,
记录该平均值和标准差。
与仅播放一集相比,平均值可以更好地估计真实的预期回报,并且标准差可以提示您播放多集时指标的变化程度。
方差太高,您应该将更多样本纳入平均值(播放更多剧集)或使用指数移动平均线等平滑技术之一。
最小值/最大值
在寻找错误时检查极端情况确实很有用。我将通过例子来讨论它。
在与我的代理一起进行的 Google Research Football 实验中,我使用当前时间步长的随机推出来计算动作质量,我注意到这些动作质量有一些奇怪的最小值。
平均统计数据是有道理的,但具有极小值的东西就不好。它们低于合理的最小值(低于负一,见图 11)。

 图 12. 平均质量均高于零。最低质量通常低于负一,这低于应有的质量。
图 12. 平均质量均高于零。最低质量通常低于负一,这低于应有的质量。
经过一番挖掘,结果发现我使用np.empty创建一个动作质量数组。
np.empty是执行np.zeros的一种奇特方法,它分配内存但尚未初始化 NumPy 数组。
因此,有时某些操作会更新分数(这会覆盖数组中的初始值),这些分数来自尚未删除的已分配内存位置!
我将np.empty更改为np.zeros并解决了问题。
中位数
我们用于平均随机事件的相同想法可以应用于整个训练!
众所周知,用于深度学习的算法称为随机梯度下降。它是随机的,因为我们随机抽取训练样本并将它们打包成批次。这意味着多次运行一项训练会产生不同的结果。
您应该始终使用不同的种子(伪随机数生成器初始化)多次运行训练,并报告这些运行的中位数,以确保分数不是偶然那么高或那么低。
 图 13. MuJoCo Ant 环境中的 SAC 训练。所有运行都具有相同的超参数,只是种子不同。三轮比赛,三个结果。
图 13. MuJoCo Ant 环境中的 SAC 训练。所有运行都具有相同的超参数,只是种子不同。三轮比赛,三个结果。
深度强化学习尚未发挥作用,因此即使您的实施是正确的,您的代理也可能无法训练任何内容。它可能只是偶然失败,例如由于不幸的初始化(参见图 12)。
结论
现在您知道应该记录什么以及为什么要记录以全面了解代理培训过程。此外,您知道在这些日志中查找什么,甚至知道如何处理常见问题。
在结束之前,请再次看一下图 12。我们看到训练曲线虽然不同,但遵循相似的路径,甚至三分之二收敛到相似的结果。有什么想法吗?