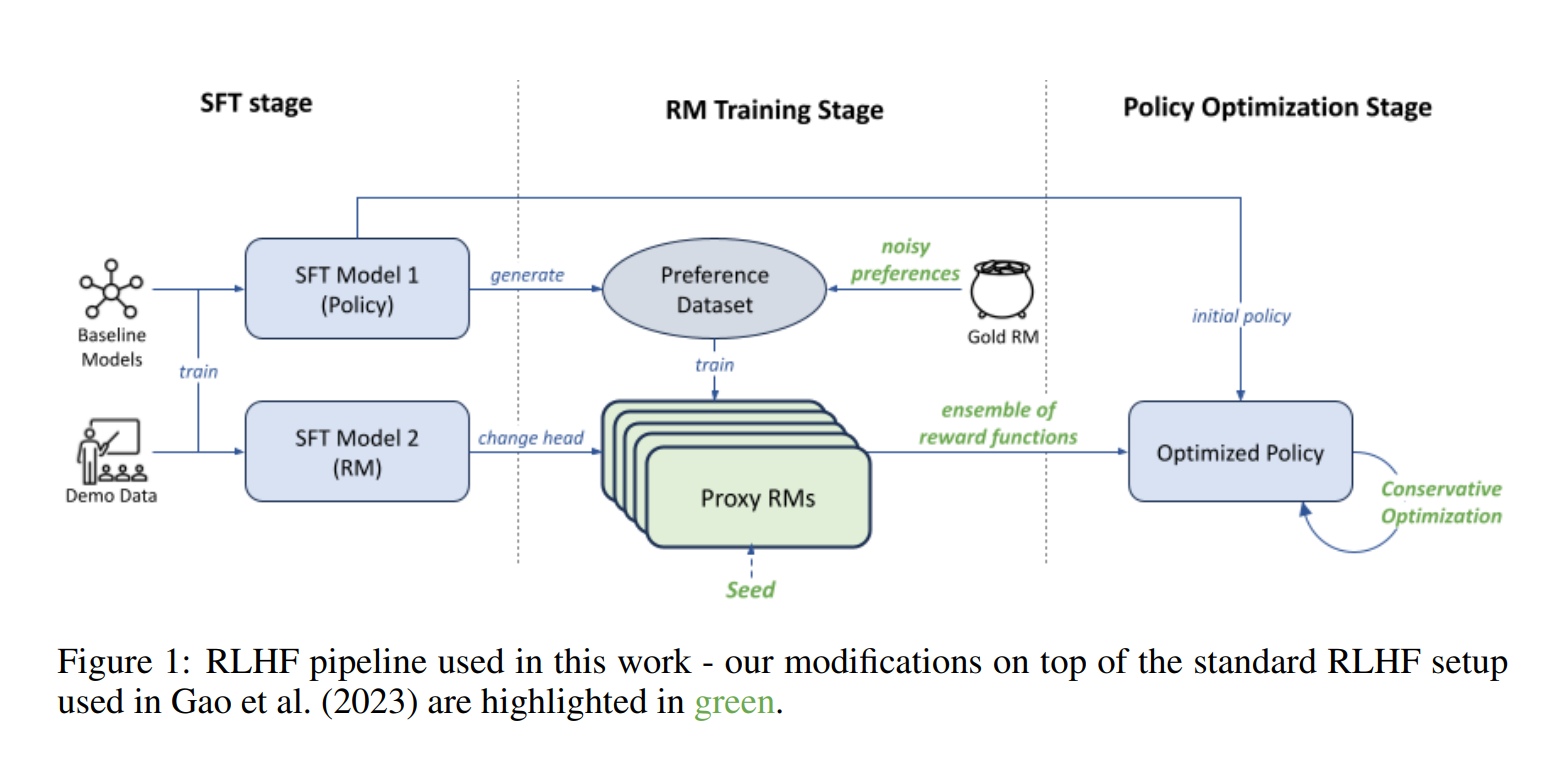
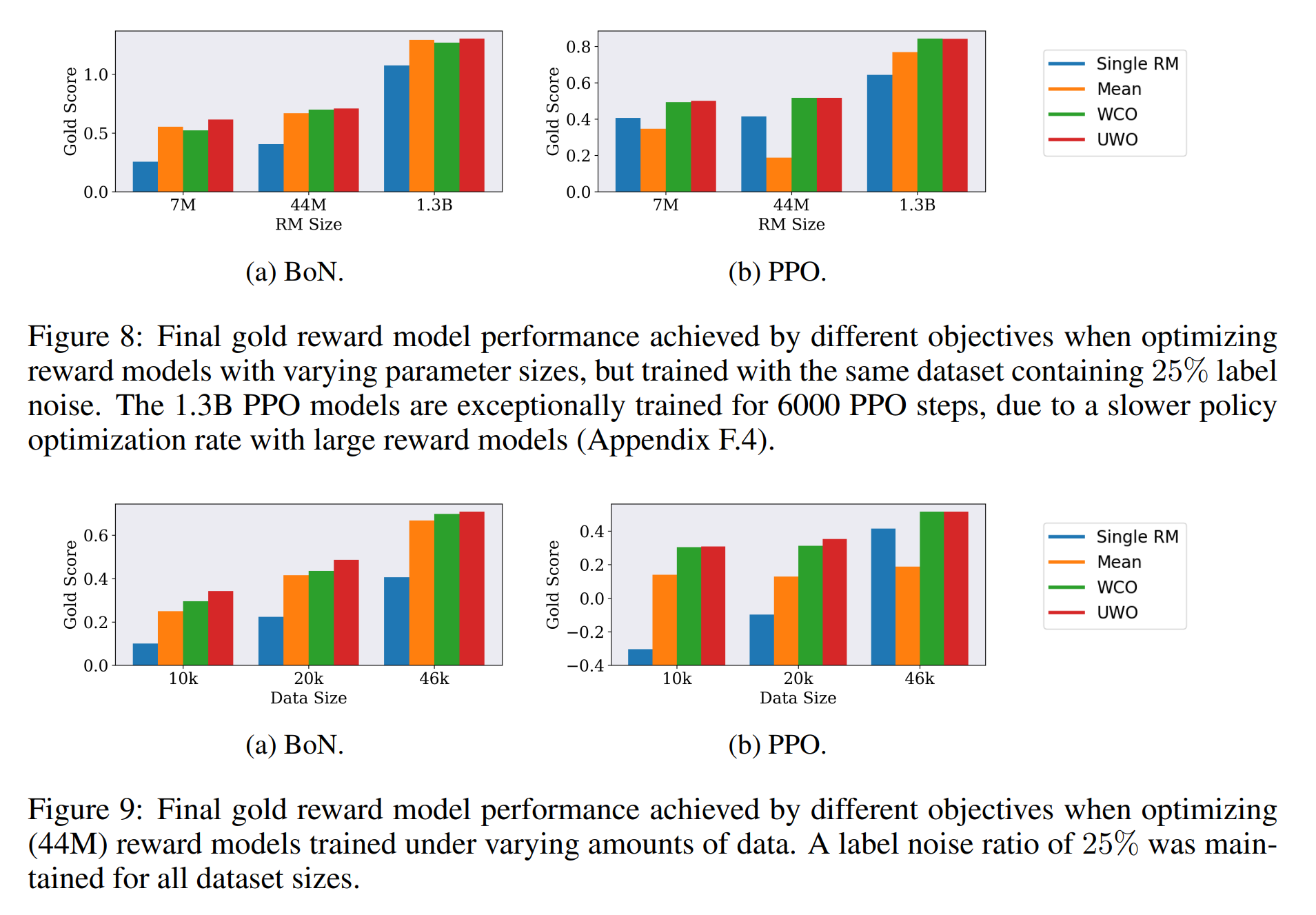
从人类反馈中强化学习(RLHF)是一种根据指令微调大型语言模型的标准方法。作为这个过程的一部分,学习的奖励模型被用来近似地模拟人类的偏好。然而,作为“真实”奖励的不完美表示,这些学习的奖励模型容易受到过度优化的影响。Gao等人(2023)在一个合成的人类反馈设置中研究了这一现象,其中一个明显更大的“黄金”奖励模型作为真正的奖励(而不是人类),并表明无论使用的代理奖励模型和训练数据的大小,过度优化仍然是一个持久的问题。使用类似的设置,我们进行了一项系统研究,以评估在使用两种优化方法时,使用基于集合的保守优化目标,特别是最坏情况优化(WCO)和不确定性加权优化(UWO)来缓解奖励模型过度优化的效果:(a)最佳抽样(BoN)(b)近端策略优化(PPO)。我们还扩展了Gao等人的设置。(2023)将25%的标签噪声包括在内,以更好地反映真实世界的条件。无论有没有标签噪声,我们都发现保守优化实际上消除了过度优化,并将BoN采样的性能提高了70%。对于PPO,基于集成的保守优化总是减少过度优化,并优于单一奖励模型优化。此外,将其与小的KL惩罚相结合,成功地防止了过度优化,而不需要任何性能成本。总之,我们的结果表明,基于集成的保守优化可以有效地对抗过度优化。
论文pdf:https://arxiv.org/pdf/2310.02743