最近在复现一篇关于DDPG的无人机安全通信的论文,奖励函数是一定时间内符合通信条件的用户个数
但是本人从未有强化学习的基础,用的elegantRL里的DDPG,想问一下以下问题
1:critic网络的输入,critic网络输入无人机的二维坐标[0-500]和旋转角度[0-360]与运行距离[0-10],是否需要把这三个输入调整为统一数量级?我把二维坐标除了100,把旋转角度和运行距离统一为[-1到1],不知道对不对
2:神经网络的神经元个数多大合适,论文中为两层分别是564,432
3:我在环境中把运行距离*旋转角度的X和Y方向的运行距离进行四舍五入会不会有影响
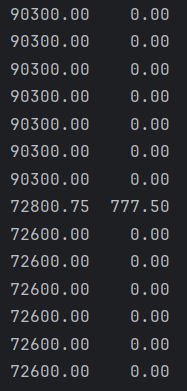
4:训练过程中actor网络的loss一直在增加,不知道怎么回事
5:有时候训练会突然奖励归零,是不是buffer里收到了新的状态
6:评估时候,reward的std大部分时候为0,是不是不正常
图1 actor网络的loss一直在增加
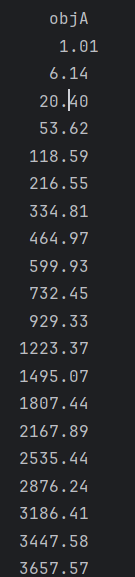
图2 reward的std大部分时候为0,然后突然变化,不知道是什么原因