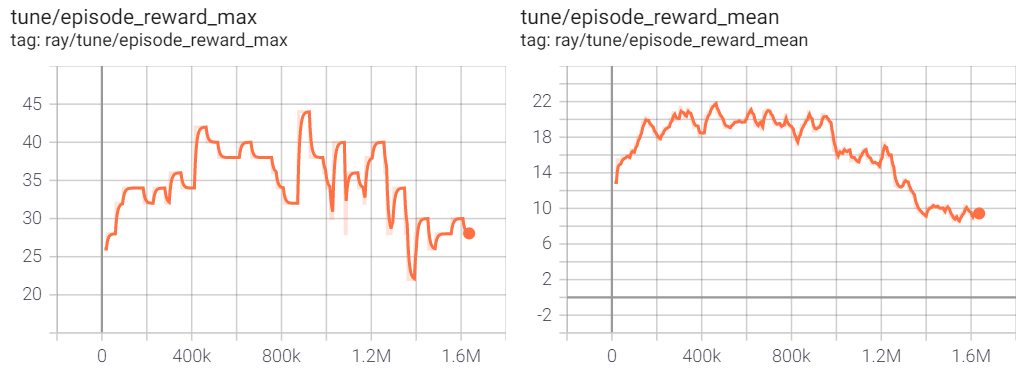
鼓励agent捡道具,地图上会随机生成道具,agent可以看到自己周围的道具,每次捡到道具会获得+2奖励,无其他奖励设置
input(100+,位置、道具相关属性) ->fcnet(512) -> fcnet(256) -> fcnet(128) -> output(8个方向)
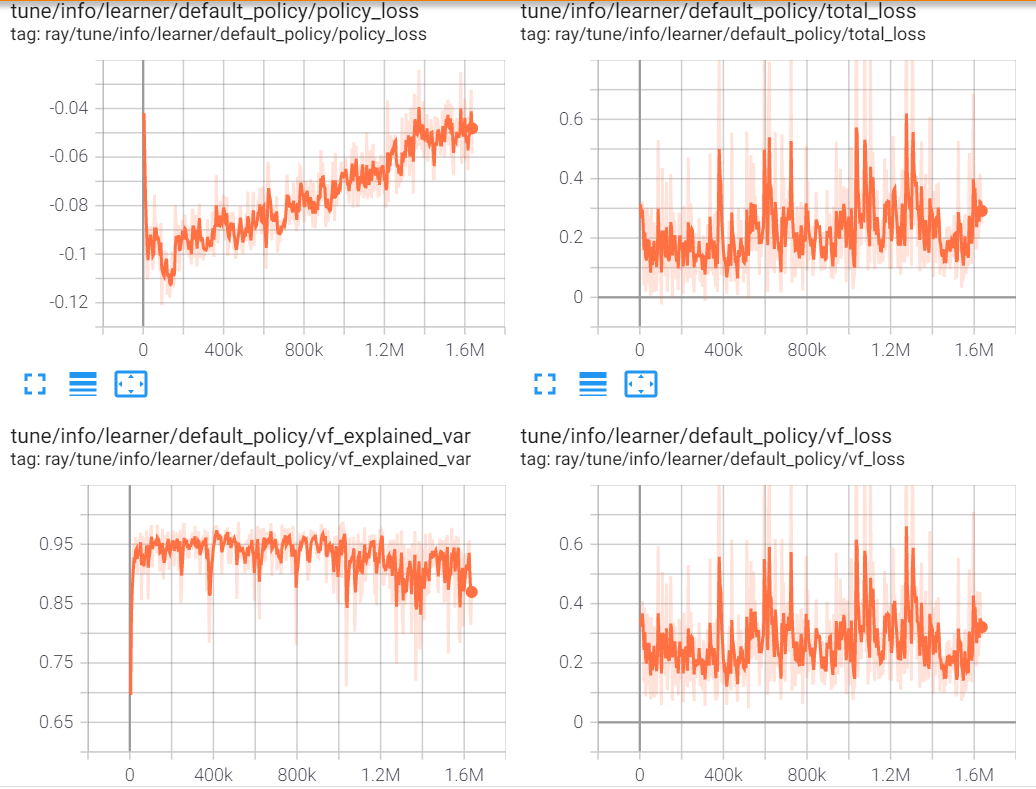
rllib默认的PPO算法
应该是奖励稀疏的问题,reward 信号很容易就消失在了茫茫的数据中,如果能给智能体连续性的奖励应该可以解决这个问题。还有就是尽可能减少输入维度,道具相关属性与捡道具有关系吗?
Ironman9527 感谢!确实如此。后来我们尝试地做了reward shaping以及把道具属性等无关输入去掉,同时减小网络参数,可以有效地训练出捡道具任务了。对了,当时的模型输入没有考虑做归一化,补上了归一化以后效果也有较大提升。