现实世界中的多智能体任务通常涉及角色出现时的动态团队组成,这也应该是多智能体强化学习(MARL)中高效合作的关键。从角色和代理行为模式之间的相关性中获得灵感,我们提出了一种新的注意力引导的集中角色表示学习框架,用于MARL(ACORM),以促进代理之间的行为异质性、知识转移和熟练协调。首先,我们引入互信息最大化来形式化角色表征学习,推导出对比学习目标,并简洁地近似负对的分布。其次,我们利用注意力机制促使全局状态关注价值分解中的学习角色表示,隐含地指导智能体在熟练的角色空间中协调,以产生更具表现力的信用分配。对《星际争霸II》微观管理和谷歌足球研究任务的挑战性实验证明了我们方法的最先进性能及其相对于现有方法的优势。我们的代码可在https://github.com/NJU-RL/ACORM.
合作多智能体强化学习(MARL)旨在协调一个智能体系统以优化全球回报(Vinyals等人,2019),并在自动驾驶汽车(Zhou等人,2020)、智能电网(Chen等人,2021a)、机器人技术(Yu等人,2023)和社会科学(Leibo等人,2017)等各个领域展现出巨大的前景。培训协调此类系统的可靠控制策略仍然是一项重大挑战。集中训练与分散执行(CTDE)(Foerster等人,2016)融合了独立Q学习(Foerste等人,2017)和联合行动学习(Sukhbaatar等人,2016年)的优点,成为一种引人注目的范式,利用集中训练机会来训练完全分散的政策(Wang等人,2023)。随后,提出了许多流行的算法,包括VDN(Sunehag等人,2018)、QMIX(Rashid等人,2020)、MAAC(Iqbal&Sha,2019)和MAPPO(Yu等人,2022)。
共享策略参数对于将这些算法扩展到具有加速合作学习的大规模代理至关重要(Fu等人,2022)。然而,人们普遍观察到,代理人倾向于获得同质的行为,这可能会阻碍多样化的探索和复杂的协调(Christianos等人,2021)。一些方法(Li等人,2021;Jiang&Lu,2021;Liu等人,2023)试图通过区分每个主体来促进个性化行为,但它们往往忽视了通过隐含任务分配实现有效团队组成的前景。现实世界中的多智能体任务通常涉及角色出现时的动态团队组成(Shao等人,2022;Hu等人,2022)。1早期的工作将角色概念引入多智能体系统(Dastani等人,2003;Sims等人,2008;Lhaksmana等人,2018),而它们通常需要先验领域知识来预先定义角色职责。最近,ROMA(Wang等人,2020)学习了仅以当前观测为条件的新兴角色,RODE(王等人,2021)将每个角色与联合行动空间的固定子集相关联。COPA(Liu等人,2021)允许在执行过程中将团队组成的全局视图分发给每个代理,从而实现动态角色分配。一些作品将任务分解为一组技能(Liu等人,2022)或子任务(Yang等人,2022;Iqbal等人,2023),并采用分层结构进行控制。总体而言,现有的基于角色的方法仍然存在几个不足之处,例如对角色出现的复杂行为表征不足,忽视了不断发展的团队动态,或放松了CTDE约束。
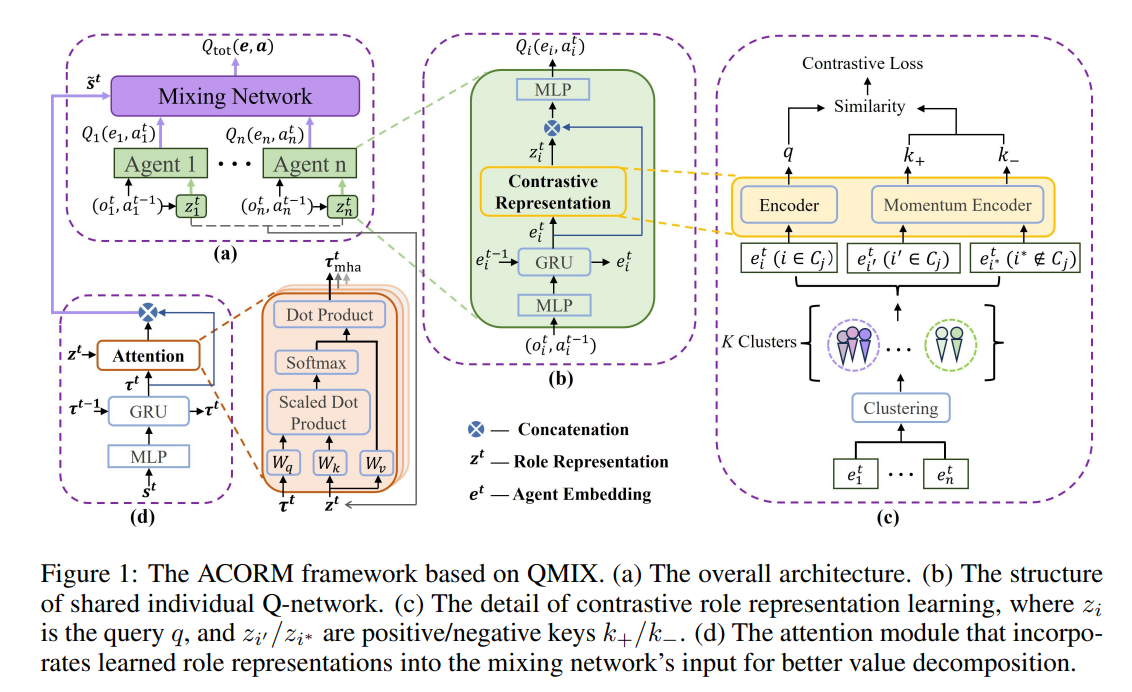
为了更好地利用动态角色分配,我们提出了一种新的注意力引导的集中角色表征学习框架(ACORM)。我们的主要见解是学习一种紧凑的角色表示,可以捕捉代理的复杂行为模式,并使用该角色表示来促进代理之间的行为异质性、知识转移和熟练协调。首先,我们将学习目标形式化为角色与其表示之间的互信息最大化,以最大限度地减少给定代理行为的角色不确定性,同时最小化保留与角色无关的信息。我们引入了一种对比学习方法来优化信息NCE损失,这是一个互信息下限。为了简明地近似负对的分布,我们通过将代理的轨迹编码到潜在空间中来提取代理行为,并根据其潜在嵌入将所有代理周期性地划分为几个簇,其中来自不同簇的点配对为负。其次,在集中训练期间,我们采用了一种注意力机制来促使全局状态关注价值分解中的学习角色表征。注意机制隐含地引导代理人在熟练的角色空间中进行协调,从而随着角色的出现产生更具表现力的信用分配。2.
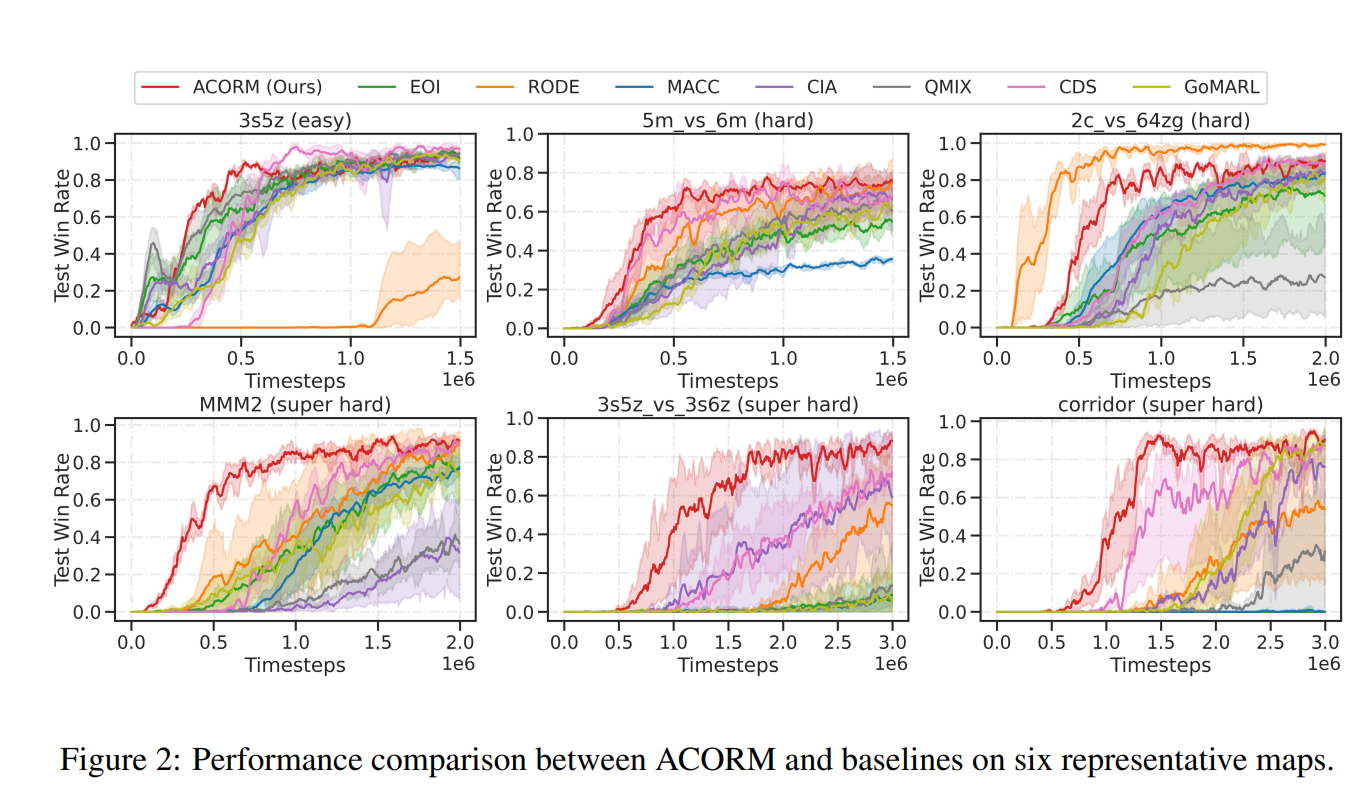
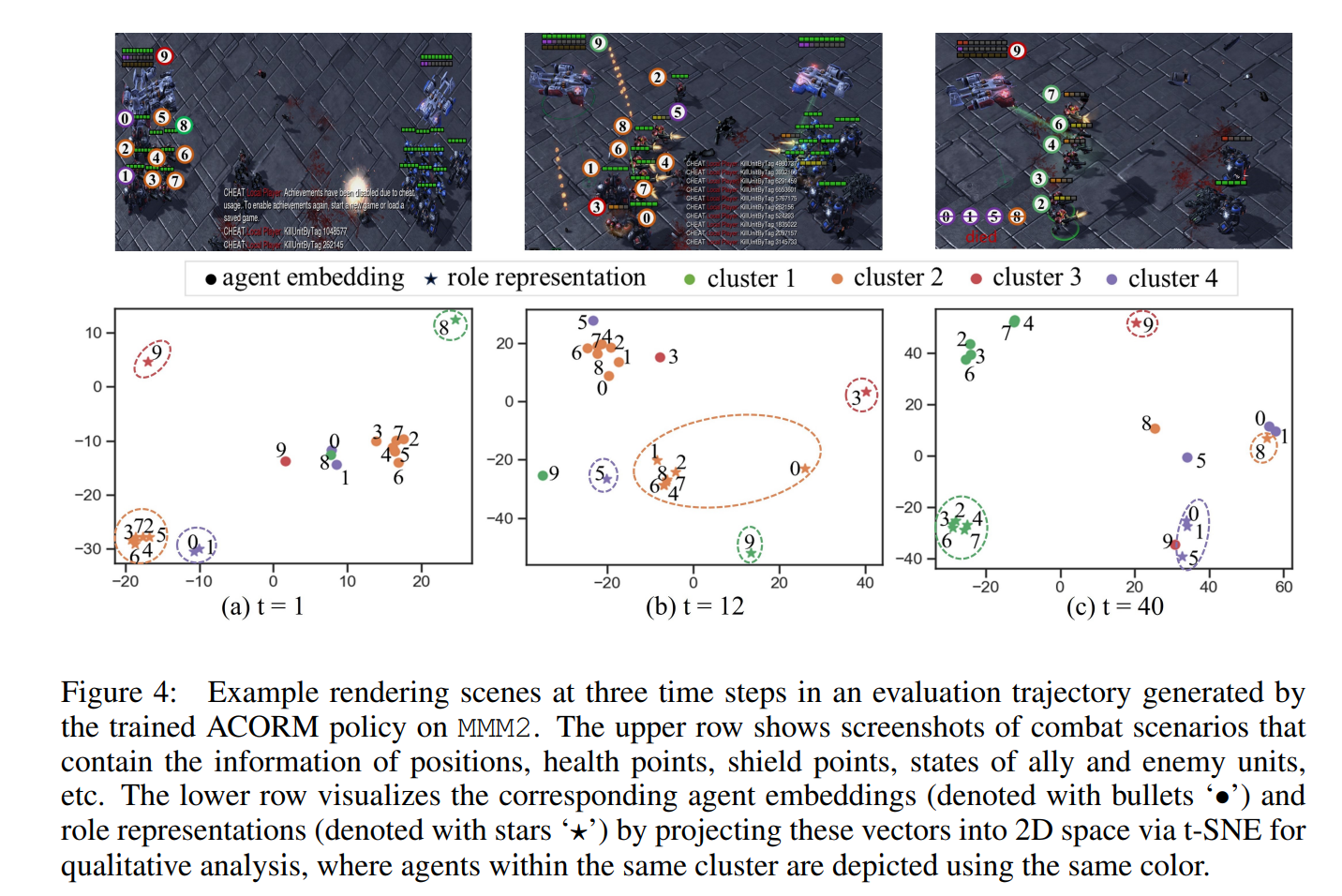
ACORM与CTDE方法完全兼容,我们在两种流行的MARL算法QMIX(Rashid等人,2020)和MAPPO(Yu等人,2022)的基础上实现了ACORM,这两种算法以具有挑战性的星际争霸多智能体挑战(SMAC)(Samvelyan等人,2019)和谷歌研究足球(GRF)(Kurach等人,2020年)环境为基准。实验证明,ACORM在大多数场景下都达到了最先进的性能。学习角色表征、异质行为模式和注意力价值分解的可视化进一步揭示了我们的优势。消融研究证实,即使代理人具有相同的先天特征,ACORM也分别通过对比角色表征学习和注意力引导的学分分配来促进更高的协调能力。
总之,我们的贡献有三方面:
•我们提出了一种基于对比学习的通用角色表征学习框架,有效地解决了代理同质化问题,促进了高效的知识转移。
•我们利用角色表征,通过注意力机制实现更具表现力的学分分配,促进复杂角色空间中的战略协调。
•我们在流行的QMIX和MAPPO的基础上构建了我们的方法,并在SMAC和GRF上进行了广泛的实验,以展示我们最先进的性能和优势。