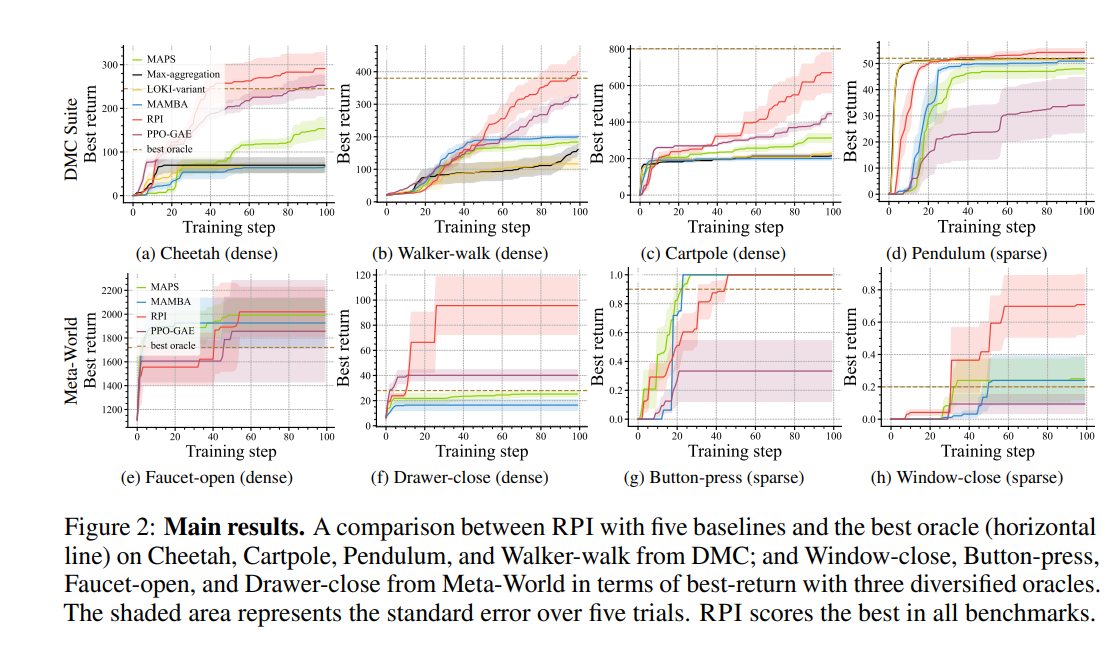
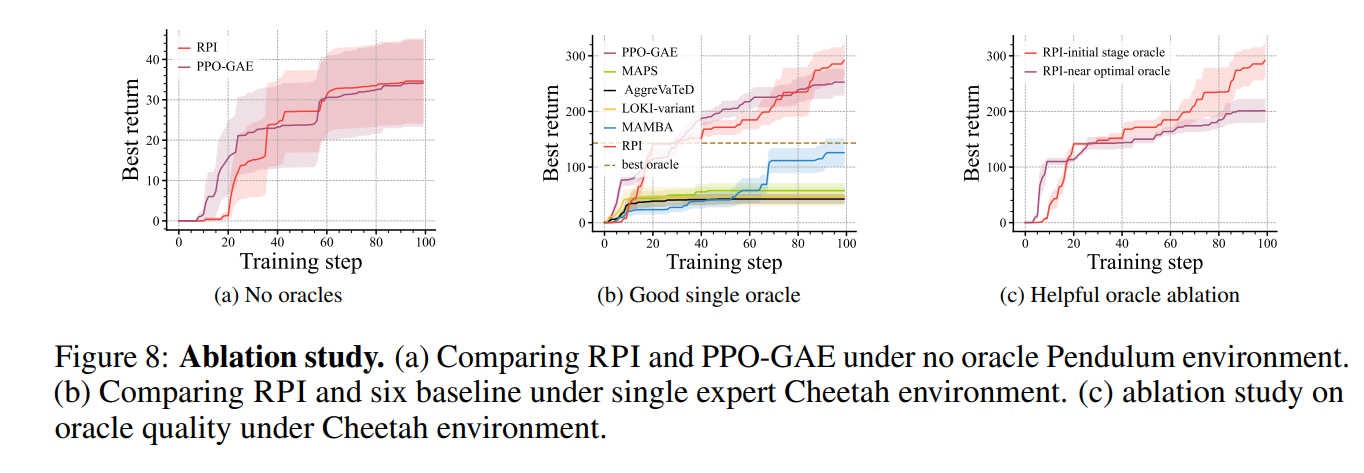
虽然强化学习(RL)表现出了良好的性能,但它的样本复杂性仍然是一个巨大的障碍,限制了它在各个领域的广泛应用。模仿学习(IL)利用神谕来提高样本效率,但它往往受到部署的神谕质量的限制。为了满足现实场景中对鲁棒策略改进的需求,我们引入了一种新的算法,鲁棒策略改进(RPI),该算法基于对IL和RL性能的在线估计,在IL和RL之间主动交织。RPI利用了IL的优势,使用oracle查询来促进探索——这在稀疏奖励RL中尤其具有挑战性——特别是在学习的早期阶段。随着学习的展开,RPI逐渐过渡到RL,有效地将学习到的策略视为改进的预言机。该算法能够从一组不同的黑盒预言中学习并改进。RPI的组成部分是鲁棒主动策略选择(RAPS)和鲁棒策略梯度(RPG),当学习者在特定状态下的表现超过神谕时,这两个因素都会决定是从神谕中进行状态模仿还是从自己的价值函数中学习。实证评估和理论分析证实,与现有的最先进方法相比,RPI表现出色,在各个领域都表现出色。请访问我们的网站1。
强化学习(RL)已经显示出显著的进步,超过了人类在不同领域的能力,如Go(Silver et al.,2017)、视频游戏(Berner et al.;2019;Mnih et al.,2013)和Poker(赵et al.,2022)。尽管取得了这些成就,但强化学习的应用在很大程度上受到其极高的样本复杂性的限制,特别是在机器人技术(Singh等人,2022)和医疗保健(Han等人,2023)等领域,在这些领域,广泛的在线互动试错往往不切实际。
模仿学习(IL)(Osa等人,2018)通过允许代理用oracle策略提供的演示替换部分或全部环境交互来提高样本效率。IL的疗效在很大程度上依赖于接近最优的神谕,如行为克隆(Pomerleau,1988;Zhang等人,2018)或反向强化学习(Abbeel和Ng,2004;Finn等人,2016;Ho和Ermon,2016;Ziebart等人,2008)。交互式IL技术,如DAgger(Ross等人,2011)和AggreVate(D)(Ross和Bagnell,2014;Sun等人,2017),同样假设我们训练的策略(即学习者策略)可以从接近最优的预言机中获得演示。当我们有机会获得奖励时,学习者有潜力改进并超越预言家。THOR(Sun等人,2018)通过利用接近最优的oracle进行成本整形,优化了k步相对于oracle值函数的优势(称为“cost-to-go oracle”),展示了这种能力。
然而,在现实环境中,获得最佳或接近最佳的神谕通常是不可行的。通常,
学习者可以访问可能无法提供最佳轨迹或
不同状态下的定量性能度量,需要大量的环境交互来识别状态最优。最近的方法,包括LOKI(Cheng等人,2018)和TGRL(Shenfeld等人,2023),旨在通过结合IL和RL来解决这个问题。它们专注于单个预言机设置,而MAMBA(Cheng等,2020)和MAPS(Liu等,2023)则从多个预言机中学习。这些方法取得了一些成功,但通常在假设至少有一个预言机在任何给定状态下提供最佳操作的情况下运行,这在实践中并不总是成立。在没有预言家为特定州提供有益建议的情况下,基于直接奖励反馈进行学习更有效。我们的工作旨在通过在统一的框架中自适应地混合IL和RL来弥合这一差距。在本文中,我们提出了max+,这是一种学习框架,旨在通过交织RL和IL,利用多个次优的黑盒预言,在未知的马尔可夫决策过程(MDP)中实现鲁棒学习。在此框架内,我们引入了鲁棒策略改进(RPI),这是一种新的策略梯度算法,旨在促进从一组黑盒预言中学习。RPI包括两个创新组成部分:1。稳健主动策略选择(RAPS),有效改进黑盒预言的值函数估计器,以及2。稳健策略梯度(RPG),基于新设计的优势函数在参与者-评论家框架内执行策略梯度更新。我们的算法在从这些次优预言机中学习和通过在学习者超过预言机性能的状态下积极探索自我改进之间取得了平衡。我们对我们提出的方法进行了理论分析,证明它确保了性能下限不低于竞争基线(Cheng等人,2020)。通过对DeepMind Control Suite(Tassa等人,2018)和Meta World(Yu等人,2020)的八项不同任务进行广泛的实证评估,我们实证证明了RPI优于当代方法,并消除了其核心组成部分。
相关工作
在线选择次优专家。CAMS(Liu等人,2022b;a)从多个次优黑盒专家那里学习,以基于给定的上下文进行模型选择,但仅适用于无状态在线学习环境。同时,SAC-X(Riedmiller等人,2018)学习意图策略(神谕),每个神谕优化自己的辅助奖励函数,然后推理执行这些神谕中的哪一个作为任务策略的课程学习形式。LfGP(Ablett等人,2023)将对抗性IL与SAC-X相结合,以改善勘探。定义辅助奖励需要将任务分解为更小的子任务,这可能不是微不足道的。此外,他们在一个事件中多次查询意图策略。与依赖于选择专家策略来执行子任务的CAMS和SAC-X不同,我们的方法训练了一个独立的学习者策略。它从次优专家那里获得专业知识,每集只使用一个oracle查询,从而有可能通过全球探索超越这些oracle。与多位专家共同改进政策。最近的研究试图从次优的黑匣子预言中学习,同时利用在学习者策略下观察到的奖励。主动离线策略选择(A-OPS)(Konyushova等人,2021)利用策略相似性来增强价值预测。然而,A-OPS缺乏学习者政策,无法从这些线下政策中获得专业知识。ILEED(Beliaev等人,2022)根据每个州的专业知识对神谕进行区分,但仅限于纯离线IL设置。InfoGAIL(Li等人,2017)将学习政策的条件设定在激励不同神谕展示的潜在因素上。OIL(Li等人,2018)试图在特定情况下识别并遵循最佳预言。SFQL(Barreto等人,2017)提出了具有后继特征的广义策略改进。MAMBA(Cheng等人,2020)利用具有几何加权泛化的优势函数,实现了比SFQL更大的政策改进,同时在理论支持下解决了上述两个重要问题。MAPS(Liu等人,2023)通过提出积极的政策选择和状态探索,提高了MAMBA的样本效率和性能。然而,即使预言集的质量很差,这些算法仍然会诉诸于使用劣质预言的模仿学习。相比之下,我们的算法进行自我改进,仅在预言机优于学习者的状态下采用模仿学习。