DELPHIC OFFLINE REINFORCEMENT LEARNING UNDER NONIDENTIFIABLE HIDDEN CONFOUNDING
离线强化学习(RL)的一个重要挑战是隐藏的混淆问题:未观察到的变量可能会影响智能体采取的行动和观察到的结果。隐藏的混淆会损害从数据中得出的任何因果结论的有效性,并成为有效离线RL的主要障碍。在本文中,我们解决了不可识别环境中的隐藏混淆问题。我们提出了一个由隐藏的混杂偏见引起的不确定性的定义,称为德尔菲不确定性,该定义使用与观测结果兼容的世界变化模型,并将其与众所周知的认知和任意不确定性区分开来。我们推导出了一种估计三种不确定性的实用方法,并构建了一个悲观的离线RL算法来解释它们。我们的方法不假设未观察到的混杂因素是可识别的,并试图减少混杂偏差的数量。我们通过广泛的实验和消融证明了我们的方法在败血症管理基准以及电子健康记录上的有效性。我们的研究结果表明,可以减轻不可识别的隐藏混淆偏见,以改善实践中的离线RL解决方案。
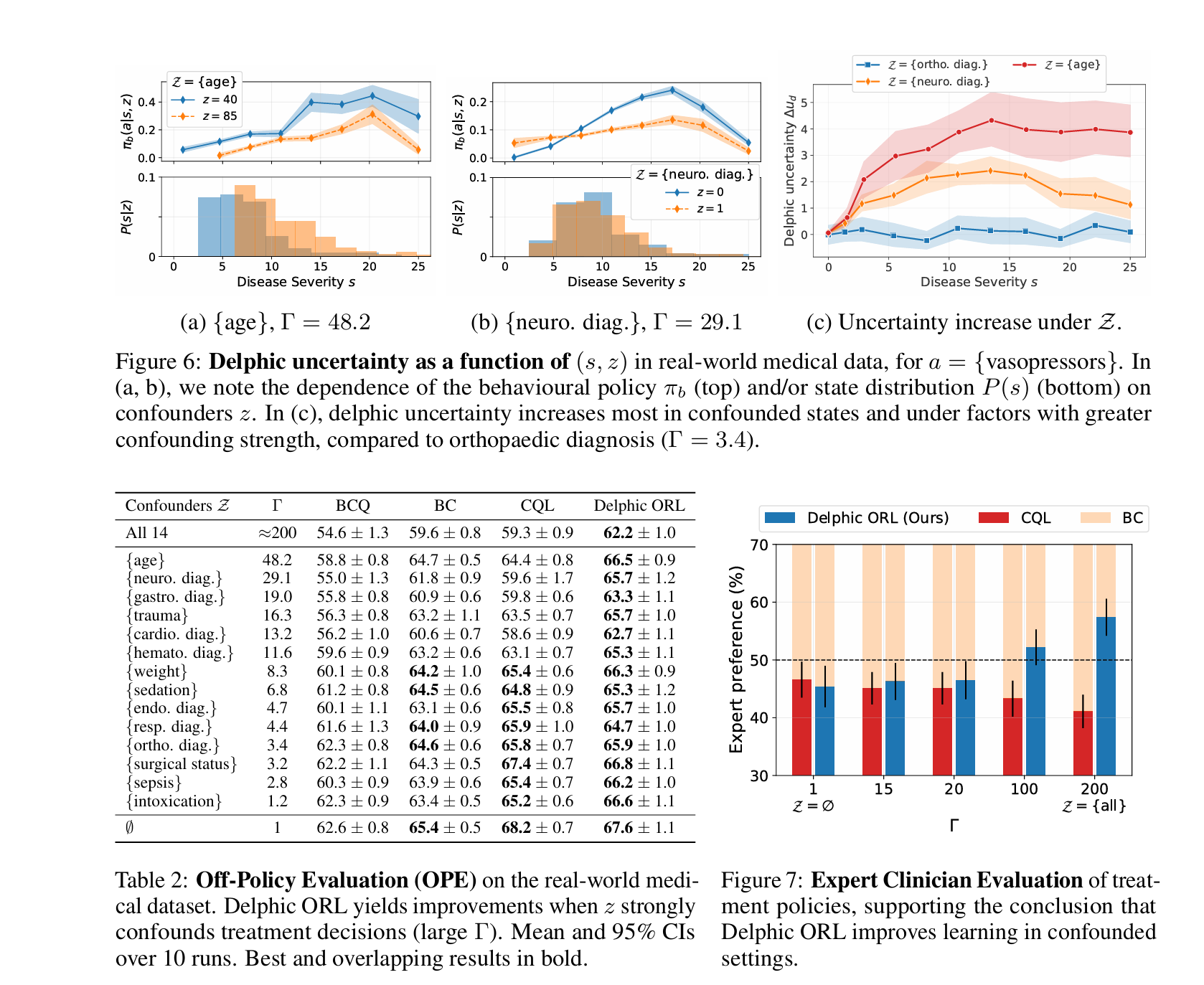
用于决策的大型观测数据集为在最小的环境交互下学习专家政策提供了可能性。这为探索不切实际、不道德甚至不可能的情况带来了希望,例如基于相关历史数据集优化营销、教育或临床决策(Gottesman等人,2018;Singla等人,2021;Thomas等人,2017)。因此,近年来出现了离线强化学习(RL)文献(Levine等人,2020),该文献提出调整RL方法以克服从初始、完全离线数据中学习引起的估计偏差。除了估计偏差外,混淆变量在离线数据中也很常见(Gottesman等人,2018)。隐藏混淆的问题,即结果和决策都取决于一个未观察到的因素,在许多并发的离线强化学习方法中被广泛忽视。然而,即使对于最简单的土匪问题,它也可能导致重大错误,在顺序设置中尤其严重(Chakraborty和Murphy,2014;Tennenholtz等人,2022;Zhang和Bareinboim,2019)。许多应用程序中都存在隐藏的混淆。例如,在自动驾驶中,观察策略可能会根据未观察到的因素(如道路状况(Haan等人,2019))表现,这也会影响环境动态和奖励。或者,在医疗背景下,代理医生可能已经考虑了未记录的患者状态信息,如社会经济因素或视觉外观(Gottesman等人,2018)。在这项工作中,我们专注于离线强化学习中不可识别的隐藏混淆。虽然之前的工作主要解决了可识别设置中的问题(Kumor等人,2021;Lu等人,2018a;Wang等人,2021,Zhang和Bareinboim,2020),但我们表明,即使在现实的不可识别设置下,政策学习也可以实现显著改善。我们提出了一种方法来估计由于混淆偏差引起的不确定性,并解释学习时的混淆程度。反过来,这又提高了离线学习算法的下游性能.
我们的主要贡献如下。(1) 据我们所知,我们是第一个解决深度离线RL中不可识别的混淆偏见的人。(2)我们通过从观测数据中引入一种新的不确定性量化方法来实现这一目标,我们称之为德尔菲不确定性。(3) 我们提出了一种离线RL算法,利用这种不确定性来获得混淆的规避策略,并且(4)我们在合成和现实世界的医疗数据上证明了它的性能。