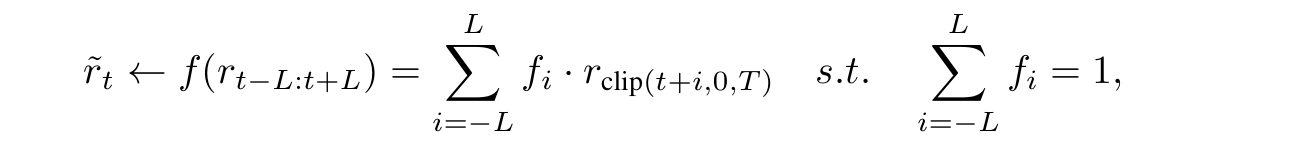基于模型的强化学习(MBRL)因其以样本高效的方式学习复杂行为的能力而受到广泛关注:通过生成具有预测奖励的假想轨迹来规划行动。尽管取得了成功,但我们发现,令人惊讶的是,奖励预测往往是MBRL的瓶颈,尤其是对于难以预测(甚至模糊)的稀疏奖励。受人类可以从粗略的奖励估计中学习的直觉的启发,我们提出了一种简单而有效的奖励平滑方法DreamSmooth,它学习预测时间平滑的奖励,而不是在给定时间步长的确切奖励。我们实证表明,DreamSmooth在样本效率和最终性能方面都能在长期稀疏奖励任务上实现最先进的性能,而不会在Deepmind Control Suite和Atari基准等常见基准上损失性能。
人类通常会根据对未来回报的粗略估计来计划行动,而不是在确切的时刻获得确切的回报(Fiorillo等人,2008;Klein Fl¨ugge等人,2011)。粗略的奖励估计基本上足以学习一项任务,预测实际奖励通常具有挑战性,因为它可能是模糊的、延迟的或不可观察的。例如,考虑图1(中间)所示的操纵任务,将桌子上的一个块推到一个箱子里,只有在块第一次接触箱子的时间步上才会给予大量奖励。使用与代理相同的图像观察结果,即使是人类也很难预测正确的奖励顺序。至关重要的是,这个问题存在于许多环境中,在这些环境中,没有奖励的国家几乎与有奖励的国家无法区分。
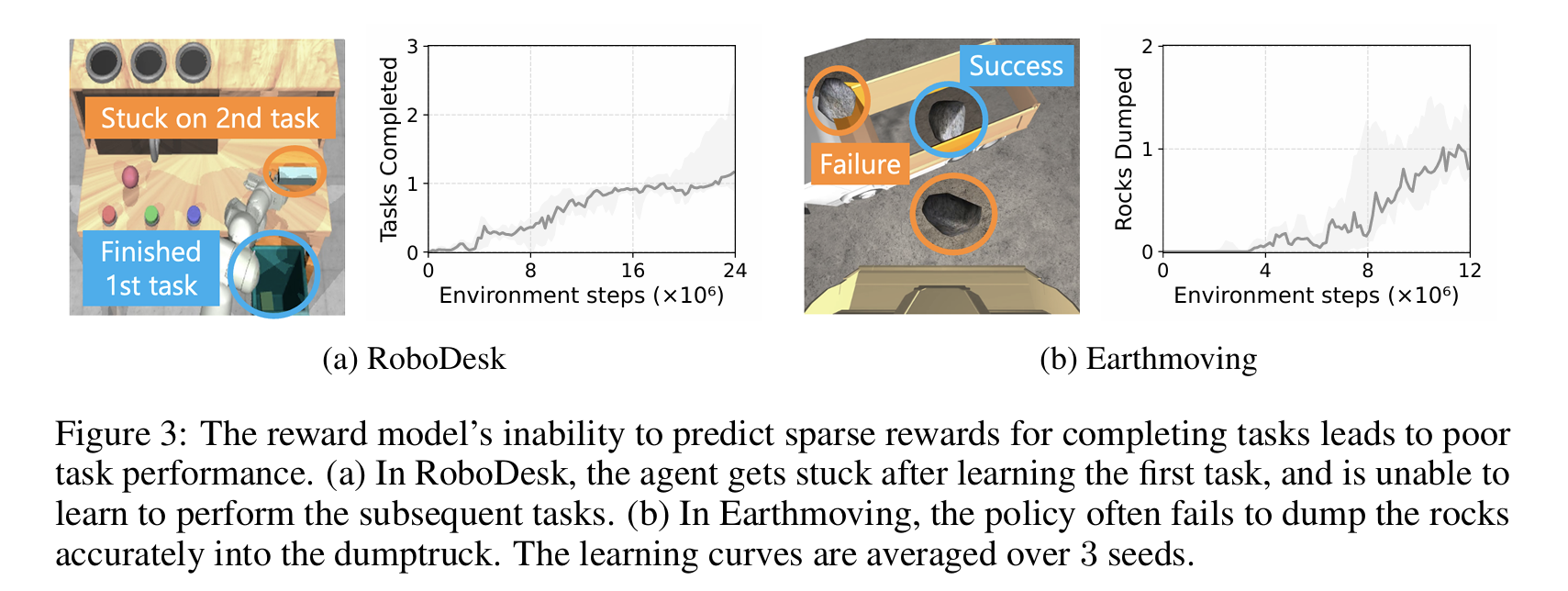
不准确的奖励模型对于基于模型的强化学习(MBRL)至关重要——过高的奖励估计会导致代理选择在现实中表现不佳的行为,过低的估计会导致代理人忽略高奖励。尽管MBRL中的奖励预测问题既困难又重要,但它在很大程度上被忽视了。我们发现,即使对于最先进的MBRL算法DreamerV3(Hafner等人,2023),奖励预测不仅具有挑战性,而且也是许多任务的性能瓶颈。例如,DreamerV3无法预测Crafter环境中大多数目标的任何奖励(Hafner,2022),在RoboDesk(Kannan等人,2021)和Shadow Hand(Plappert等人,2018)任务的变体上观察到类似的失败模式。
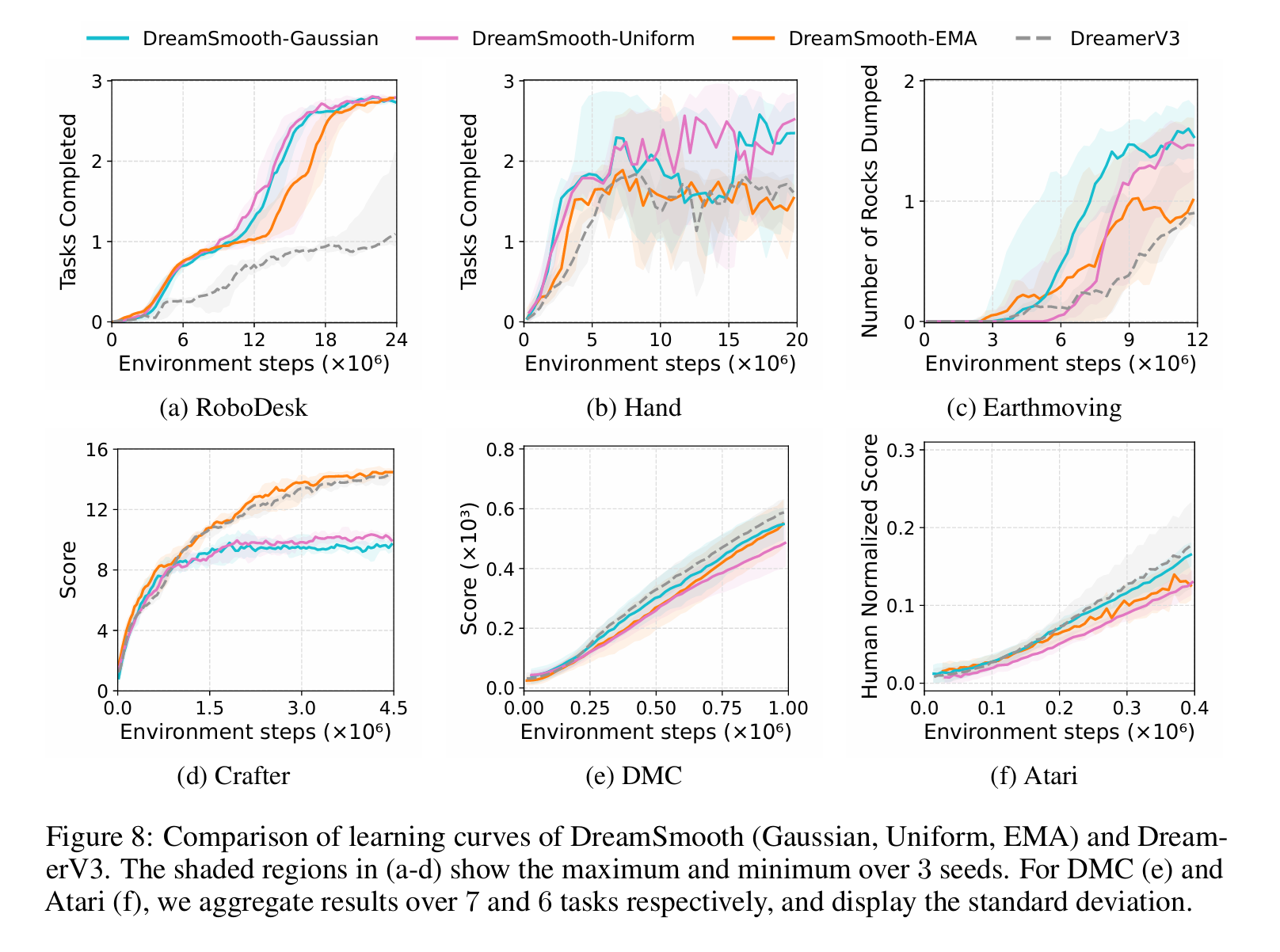
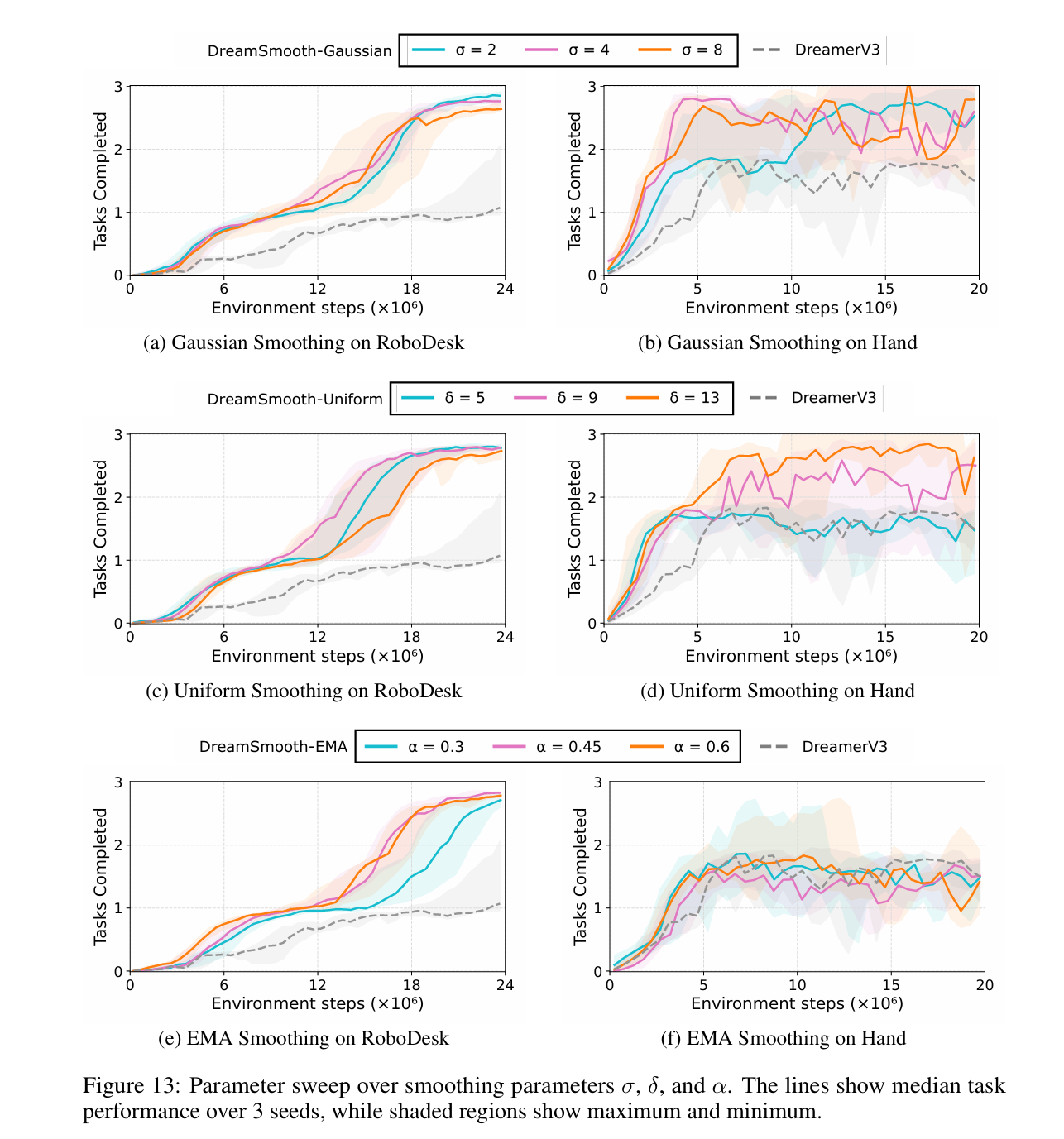
受人类直觉的启发,即只有粗略估计奖励就足够了,我们提出了一种简单而有效的解决方案DreamSmooth,它学习预测时间平滑的奖励,而不是每个时间步的确切奖励。这使得奖励预测变得更加容易——现在模型只需要对何时获得大额奖励进行估计,而不必准确预测奖励,这足以进行策略学习。我们的实验表明,虽然该技术非常简单,但它显著提高了不同MBRL算法在许多稀疏奖励环境中的性能。具体来说,我们发现对于DreamerV3(Hafner等人,2023)、TD-MPC(Hansen等人,2022)和MBPO(Janner等人,2019),我们的技术在具有以下特征的环境中特别有益:稀疏奖励、部分可观察性和随机奖励。最后,我们表明,即使在奖励预测不是一个重要问题的基准测试中,DreamSmooth也不会降低性能,这表明我们的技术可以普遍应用。
基于模型的强化学习(MBRL)利用环境的动态模型(即世界模型)和所需任务的奖励模型来规划一系列行动,以最大化总奖励。动态模型预测采取特定行动后环境的未来状态,奖励模型预测与状态-行动转换相对应的奖励。通过动态和奖励模型,代理可以在想象中而不是在物理环境中模拟大量的候选行为,使MBRL能够处理许多具有挑战性的任务(Silver等人,2016;2017;2018)。MBRL的最新进展不是依赖于给定的动力学和奖励模型,而是能够学习高维观测和复杂动力学的世界模型(Ha&Schmidhuber,2018;Schrittwieser等人,2020;Hafner等人,2019;2021;2023;Hansen等人,2022),以及时间扩展的世界模型。具体来说,DreamerV3(Hafner等人,2023)在各种问题领域都取得了最先进的性能,例如,像素和状态观测以及离散和连续动作。对于现实的想象,MBRL需要一个精确的世界模型。通过利用人类视频(Mendonca等人,2023)、采用更高性能的架构(Deng等人,2023年)以及通过表示学习,如基于原型(Deng等,2022年)和以对象为中心(Singh等,2021年)的状态表示、对比学习(Okada&Taniguchi,2021年”)和掩码自动编码(Seo等人,2022年;2023年),在学习更好的世界模型方面做出了重大努力。然而,与学习更好的世界模型的努力相比,学习准确的奖励模型在很大程度上被忽视了。Babaeizadeh等人(2020)研究了各种世界模型设计的影响,并表明在离线数据集上训练时,奖励预测与任务绩效密切相关,而仅限于密集的奖励环境。本文指出,准确的奖励预测对MBRL至关重要,特别是在稀疏奖励任务和部分可观测环境中,并提出了一种改进MBRL奖励预测的简单方法。
具体来说,DreamSmooth在收集每个新剧集时对奖励应用时间平滑。DreamSmooth可以与任何保留奖励总和的平滑函数f一起使用: