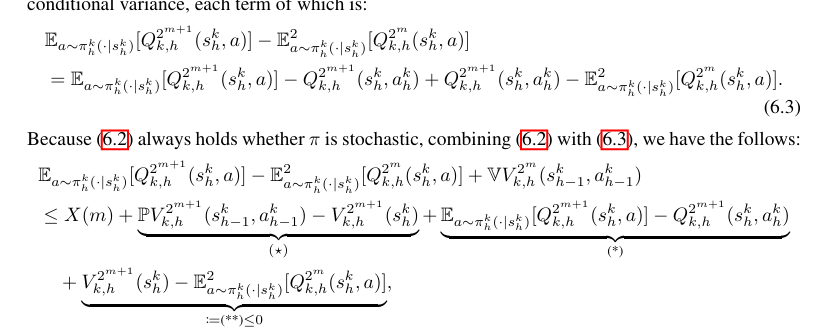HORIZON-FREE REINFORCEMENT LEARNING IN ADVERSARIAL LINEAR MIXTURE MDPS
最近的研究表明,强化学习(RL)的遗憾在规划视野H中可能是多对数的。然而,这样的结果是否适用于对抗性RL仍然是一个悬而未决的问题。在本文中,我们通过提出第一个无视野策略搜索算法来肯定地回答这个问题。为了应对由探索和对抗性选择的奖励引起的挑战,我们的算法采用了(1)方差不确定性感知加权最小二乘估计器作为转换核;以及(2)用于在线搜索随机策略的基于占用度量的技术。我们证明,我们的算法在全信息反馈1的情况下实现了O(d+log|S|)√K+d2的遗憾,其中d是已知特征映射的维数,线性参数化MDP的未知转换核,K是发作次数,|S|是状态空间的基数。我们还提供了硬度结果来证明我们的算法的近似最优性以及log|S|在后悔界的必然性。
情景马尔可夫决策过程(MDP)中的学习(Altman,1999;Dann&Brunstkill,2015;Neu&Pike Burke,2020)是强化学习(RL)中的一个关键问题(Szepesv´ari,2010;Sutton&Barto,2018),其中代理顺序地与具有固定视界长度H的环境进行交互。代理在状态st采取的每个动作都会产生一些奖励r(st,at),并将其带入下一个状态st+1。代理程序将在每个H时间步后在相同的环境中重新启动。尽管视界诅咒一直被认为是情景强化学习中的一个挑战(Jiang&Agarwal,2018),但最近的一系列工作已经开发出近最优算法,以实现表格MDP(Zhang等人,2021a)和具有线性函数近似的强化学习(Zhang等人,2021b;Kim等人,2022;Zhou&Gu,2022)的遗憾,而不依赖于H的多项式。这表明,情景强化学习的遗憾可以摆脱对H的线性依赖。然而,这些无视界算法仅适用于奖励函数固定或随机的MDP学习,但在许多现实世界场景中,我们已经应对了对抗性变化的奖励(Even Dar等人,2009;Yu等人,09;Zimin&Neu,2013)。然而,对于对抗性MDP中的无视界RL知之甚少。因此,以下问题仍然悬而未决。
Can we design near-optimal horizon-free RL algorithms under adversarial reward and unknown transition with function approximation employed?
我们能否在对抗性奖励和未知转换的情况下,采用函数近似设计出接近最优的无视界RL算法?
在本文中,我们肯定地回答了全信息反馈下具有对抗性奖励的线性混合MDP的问题(Cai等人,2020;He等人,2022b)。我们提出了一种新的算法,称为无视界占用度量引导的乐观策略搜索(HF-O2PS)。继蔡等(2020);He等人(2022b),我们使用在线镜像下降(OMD)来更新政策和价值目标回归(VTR)(Jia等人,2020;Ayoub等人,2020)来学习这种转变。尽管如此,我们还是证明了基于值函数的镜像下降不可避免地在后悔上界引入了对规划视界H的多项式依赖。为了解决这个问题,受Rosenberg和Mansour(2019a)的启发;Jin等人(2020a)和Kalagarla等人(2020),我们使用入住率指标作为政策的代理,并对入住率指标进行OMD更新。与Jin等人(2020a)一样,我们维护了转换核的置信集,并利用约束OMD来处理未知的转换。为了实现无视界的后悔界,我们还将Zhou&Gu(2022)的高阶矩估计器应用于随机策略,并获得了更严格的Bernstein型置信集。在前K个事件中,我们算法的遗憾可以高概率地达到O(d√K+d2)的上限,其中d是特征映射的维数。据我们所知,我们的算法是第一个在学习对抗性线性混合MDP时实现无视界后悔的算法。我们的三个主要贡献总结如下:•我们提出了一种新的算法HF-O2PS,用于求解对抗性奖励单界为1/H的线性混合MDP。与之前的研究相比(例如,Caietal.(2020);高跟鞋。(2022b)),HF-O2PS使用基于占用度量的OMD而不是直接策略优化。HF-O2PS还使用高阶矩估计器来进一步促进过渡核的学习我们的分析表明,HF-O2PS达到了遗憾界O(d√K+d2),其中K是发作次数,d是特征映射的维度。据我们所知,HF-O2PS是对抗性RL实现无视界后悔上限的第一种算法除了遗憾的上限外,我们还提供硬度结果。首先,我们证明了无界S将导致√H中的下界渐近线性,这证明了我们的假设|S|<∞。
我们还提供了Ω(d√K)的极小极大下界,这表明HF-O2PS的近似最优性。我们用小写字母表示标量,用小写粗体字母表示向量和矩阵。我们用[n]表示集合{1,…,n},并且[n]={0,…n−1}。给定naRd×d∋∑≻0向量∈Rd,我们得到向量L2-normby∥x∤2,并定义\8741 x⊤∑=√xͤ∑x。我们使用包括O(·)、Ω(·)和Θ(.)在内的标准渐近符号,并进一步使用O(.)来隐藏多对数因子。设1{·}表示指示函数,[x][a,b]表示截断函数x·1{a≤x≤b}+a·1{x<a}+b·1{x>b},其中a≤b∈R,x∈R。设∆(·)表示有限集上的概率单纯形。