
HARNESSING DENSITY RATIOS FOR ONLINE REINFORCEMENT LEARNING
利用密度比进行在线强化学习
尽管离线和在线强化学习的理论是并行发展的,但它们已经开始显示出统一的可能性,一种环境的算法和分析技术在另一种环境中往往有天然的对应物。然而,在线强化学习中基本上没有密度比建模的概念,这是离线强化学习中一种新兴的范式,这可能是有充分理由的:密度比的存在和有界性依赖于对具有良好覆盖率的探索性数据集的访问,但在线强化学习的核心挑战是在没有数据集的情况下收集这样的数据集。在这项工作中,我们展示了——也许令人惊讶的是——基于密度比的算法有在线对应物。假设仅存在具有良好覆盖率的探索性分布,这是一种称为覆盖性的结构条件(Xie等人,2023),我们给出了一种新的算法(GLOW),该算法使用密度比可实现性和值函数可实现性来进行样本高效的在线探索。GLOW通过谨慎使用截断来解决无界密度比问题,并将其与乐观主义相结合,以指导勘探。GLOW在计算上效率低下;我们用更有效的对应物HYGLOW来补充它,用于混合RL设置(Song等人,2023),其中在线RL通过额外的离线数据进行增强。HYGLOW是一种更通用的元算法的特例,它提供了一种可证明的从混合RL到离线RL的黑盒缩减,这可能具有独立的意义。
强化学习(RL)的一个基本问题是理解什么建模假设和算法原理会导致样本高效学习保证。对样本高效强化学习算法的研究主要集中在两个单独的公式上:离线强化学习,学习者必须从记录的转换和奖励中优化策略;在线强化学习,学生可以通过与环境交互收集新数据;这两个公式都有一个共同的目标,即学习一个接近最优的策略。在大多数情况下,关于离线和在线强化的研究机构是并行发展的,但它们表现出许多奇怪的相似之处。从算法上讲,离线RL的许多设计原则(例如悲观主义)都有在线对应原则(例如乐观主义),这两种框架的统计高效算法通常需要类似的表示条件(例如,对状态-动作-值函数进行建模的能力)。然而,这些框架存在显著差异:在线RL算法需要探索条件来解决分布偏移的问题(Russo和Van Roy,2013;Jiang等人,2017;Sun等人,2019;Wang等人,2020c;Du等人,2021;Jin等人,2021a;Foster等人,2021),而离线RL算法需要概念上不同的覆盖条件来确保数据记录分布充分覆盖状态空间(Munos,2003;Antos等人,2008;Chen和Jiang,2019;Xie和Jiang2020,2021;Kim等人,2021b;Rashidinejad等人,2021;Foster等人,2022;Zhan e等人,2022)。
最近,Xie等人(2023)揭示了在线和离线RL之间更深层次的联系,表明覆盖性——即存在对离线RL具有良好覆盖的数据分布——本身就是一个充分条件,即使学习者对所述分布没有先验知识,也能在在线RL中进行样本高效探索。这表明了在线和离线强化学习理论统一的可能性,但情况仍然不完整,我们的理解存在许多差距。值得注意的是,离线强化学习中一种有前景的新兴范式利用了为底层MDP建模密度比(也称为边缘化重要性权重或简称为权重函数)的能力。密度比建模为经典值函数近似(或近似动态规划)方法提供了一种替代方案(Munos,2007;Munos和Szepesvári,2008;Chen和Jiang,2019),因为它避免了不稳定性,并且通常在较弱的表示条件下成功(与Bellman完备性假设相反,只需要可实现性条件)。然而,尽管对离线强化学习的密度比方法进行了广泛的研究——无论是在理论上(Liu等人,2018;Uehara等人,2020;Yang等人,2020年;Uehala等人,2021;Jiang和Huang,2020;Xie和Jiang,2020;Zhan等人,2022;Chen和Jiang2022;Rashidinejad等人,2023;Ozdaglar等人,2023)还是在实践中(Nachum等人,2019;Kostrikov等人,2019)——密度比建模在在线强化学习中明显缺失。这让我们不禁要问:
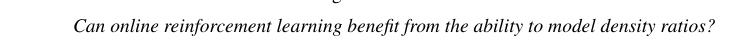
将基于密度比的方法适应具有可证明保证的在线设置,带来了许多概念和技术挑战。首先,由于在线强化学习中的数据分布不断变化,因此尚不清楚应该尝试建模什么密度。其次,大多数离线强化学习算法对数据分布的覆盖率要求相对严格。在在线强化学习中,期望在学习过程早期收集的数据具有良好的覆盖率是不合理的,因此幼稚的算法可能会循环或无法探索。因此,期望密度比建模以与离线相同的方式使在线RL受益可能是不合理的。
我们的贡献。我们表明,尽管存在这些挑战,但密度比建模能够保证以前无法实现的在线强化学习。
- 在线RL的密度比。我们表明(第3节),对于任何低覆盖率的MDP,密度比可实现性和最优状态动作值函数的可实现性足以实现样本高效的在线RL。这一结果是通过一种新的算法GLOW获得的,该算法通过谨慎使用截断的密度比来解决分布偏移问题,并将其与乐观主义相结合以推动探索。这补充了Xie等人(2023)的研究,他们在值函数类的更强Bellman完备性假设下为可覆盖的MDP提供了保证。
- 混合RL的密度比。我们的在线RL算法在计算上效率低下。我们为混合强化学习框架(Song等人,2023)补充了一个更有效的对应物HYGLOW(第4节),在该框架中,学习者可以访问涵盖高质量策略的额外离线数据。
- 混合到离线减少。为了实现上述结果,我们研究了一个更广泛的问题:离线RL算法何时可以按原样适应在线设置?我们提供了一种新的元算法H2O,它通过反复调用给定的离线RL算法作为黑盒,将混合RL简化为离线RL。
我们证明,只要黑盒离线算法满足某些条件,H2O的遗憾率就很低,并证明了一系列现有的离线算法都满足这些条件,从而将它们提升到混合RL设置。虽然我们的结果本质上是理论性的,但我们乐观地认为,它们将进一步研究在线强化学习中密度比建模的力量,并激发实用的算法。




