
在现实世界的任务中实现人类水平的速度和性能是机器人研究界的北极星。这项工作朝着这个目标迈出了一步,并提出了第一个在竞技乒乓球比赛中达到业余人类水平表现的学习机器人代理。乒乓球是一项对体力要求很高的运动,需要人类运动员经过多年的训练才能达到高水平的熟练程度。在本文中,我们贡献了 (1) 一个分层和模块化的策略架构,包括 (i) 低级控制器及其详细的技能描述符,这些描述符对代理的能力进行建模并帮助弥合模拟到真实的差距,以及 (ii) 一个选择低级技能的高级控制器,(2) 实现零样本模拟到真实的技术,包括一种迭代方法来定义基于现实世界的任务分布并定义自动课程, (3)实时适应看不见的对手。通过29场机器人与人类的比赛来评估政策绩效,其中机器人赢得了45%(13/29)。所有人类都是看不见的玩家,他们的技能水平从初学者到锦标赛级别各不相同。虽然机器人输掉了所有与最高级玩家的比赛,但它赢得了 100% 的比赛与初学者的比赛和 55% 的比赛与中级玩家的比赛,展示了坚实的业余人类水平表现。
赋予动机
尽管最近取得了令人鼓舞的进展,但在准确性、速度和适应性方面实现人类水平的性能对机器人技术来说仍然是一个挑战。
乒乓球需要多年的训练才能让人类掌握,因为它具有复杂的低级技能和战略游戏玩法。 战略上次优但自信可执行的低级技能可能是更好的选择。这使乒乓球有别于国际象棋、围棋等纯粹的战略游戏。
因此,乒乓球是提升机器人能力的宝贵基准,包括高速运动、实时精确和战略决策、系统设计以及与人类对手的直接竞争。
之前没有关于机器人乒乓球的研究解决过机器人与以前看不见的人类进行全面竞争性比赛的挑战。

贡献
我们的方法导致了人类层面的竞争性游戏,以及人类真正喜欢玩的机器人代理。为了实现这一目标,我们做出了四项技术贡献:
分层和模块化的策略架构
实现零样本模拟到真实的技术,包括一种迭代方法来定义基于现实世界的训练任务分布
Real 时间适应看不见的对手
一项用户研究,用于测试我们的模型在物理环境中与看不见的人类进行实际比赛
方法
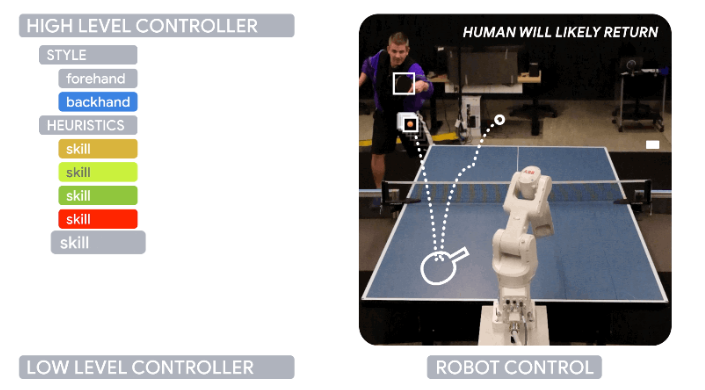
该代理由一个低级技能库 和选择最有效技能的高级控制器组成。每个低级技能策略都专门针对乒乓球的特定方面,例如正手上旋球、反手瞄准或正手发球。除了培训策略本身外,我们还离线和在线收集和存储有关每种低级技能的优势、劣势和局限性的信息。由此产生的技能描述符为机器人提供了有关其能力和缺点的重要信息。反过来,负责编排低级技能的高级控制器会根据当前的游戏统计数据、技能描述符和对手的能力选择最佳技能。
我们收集少量的人与人之间的游戏数据来播种初始任务条件。然后,我们使用 RL 在模拟中训练代理,并采用多种技术(已知的和新颖的)将策略零样本部署到真实硬件。该智能体与人类进行游戏,以生成更多的训练任务条件,并重复训练部署周期。随着机器人的改进,游戏标准变得越来越复杂,同时仍然立足于现实世界的任务条件。 这种混合模拟-现实循环创建了一个自动任务课程,并使机器人的技能能够随着时间的推移而提高。
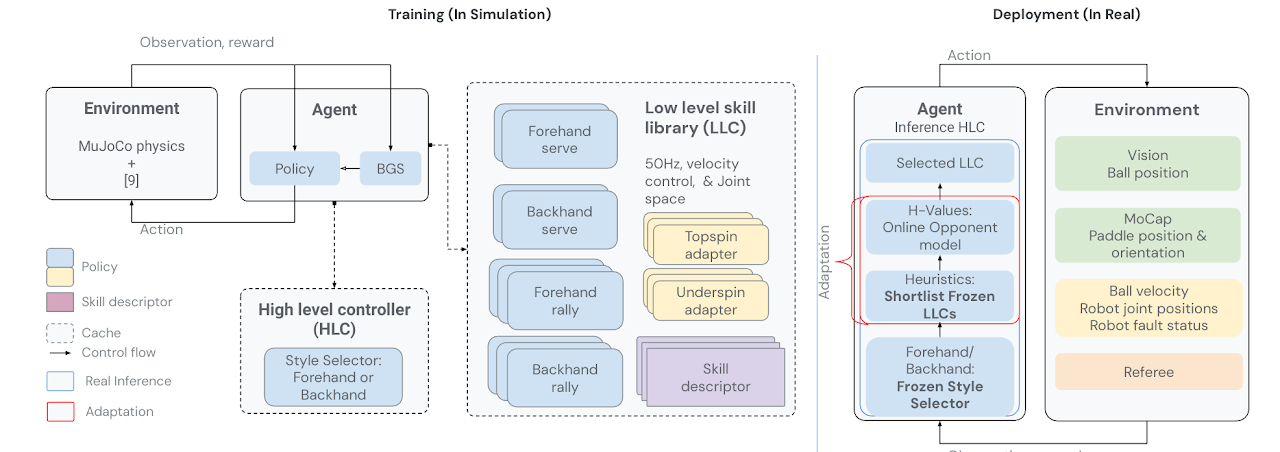
层次控制
选择风格:高级控制器 (HLC) 首先决定使用哪种风格(正手/反手)。
适应:
选择最有效的技能:HLC 根据调整后的 H 值对入围的 LLC 进行抽样。
更新:H值和对手统计数据会持续更新,直到比赛结束。
*
结果
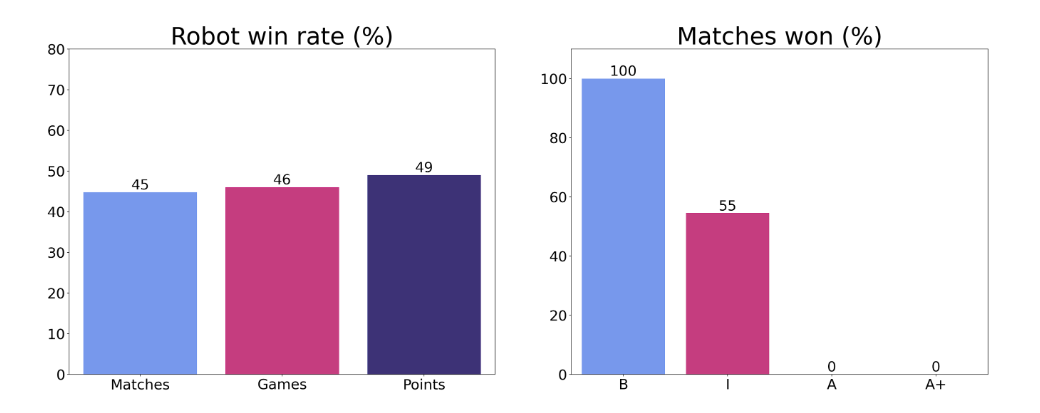
为了评估我们经纪人的技能水平,我们与 29 名不同技能水平的乒乓球运动员进行了竞争性比赛——初级、中级、高级和高级+,由专业乒乓球教练确定。人类按照标准的乒乓球规则与机器人进行了 3 场比赛,但进行了一些修改,因为机器人在身体上无法发球。在所有对手中,机器人赢得了45%的比赛和46%的比赛。按技能水平细分,我们看到机器人赢得了与初学者的所有比赛,输掉了与高级和高级+玩家的所有比赛,并赢得了与中级玩家的55%的比赛。这强烈表明我们的代理人在拉力赛中达到了中级水平的人类游戏。
定性评估
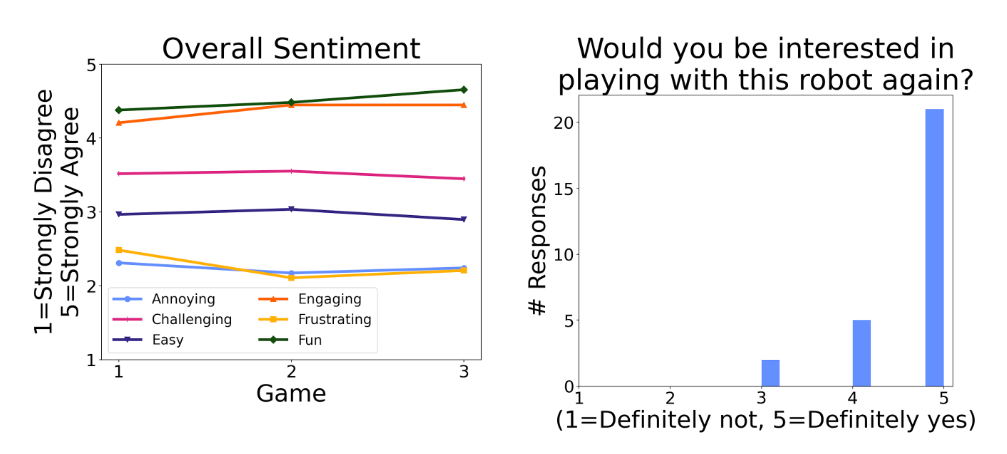
研究参与者喜欢玩机器人,对它的“乐趣”和“吸引力”给予高度评价。这个评级在不同的技能水平上都适用,无论参与者赢了还是输了。他们还压倒性地回答说“绝对是”,想要再次与机器人一起玩。当给机器人自由游戏时间时,他们平均玩了 4 分 06 秒(每 5 分钟)。
高级玩家能够利用机器人政策中的弱点,但他们仍然在玩它时玩得很开心。在赛后的采访中,他们看到了它作为比投球手更有活力的练习伙伴的潜力。



人类战略和政策弱点
最熟练的玩家提到,机器人不擅长处理下旋球。为了验证这一观察结果,我们通过估计的球旋转来绘制机器人的落地率,并且随着面临更多的下旋球,确实看到了很大的下降。这种缺陷部分是由于难以处理低球以避免与球台碰撞,其次难以实时确定球的旋转。幸运的是,这为我们的飞轮的额外培训提供了明确的反馈。
该团队的相关研究
