Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms《直接对齐算法中奖励模型过度优化的标度律》
从人类反馈中强化学习(RLHF)对大型语言模型(LLMs)的近期成功至关重要,然而,这通常是一个复杂而脆弱的过程。在经典的RLHF框架中,首先训练一个奖励模型来表示人类偏好,然后由在线强化学习(RL)算法使用该模型来优化LLM。这种方法的一个突出问题是\emph{奖励过度优化}或\emph{奖励黑客},其中由学习的代理奖励模型衡量的性能增加,但真正的质量停滞不前甚至恶化。直接对齐算法(DDA),如直接偏好优化,通过绕过奖励建模阶段,已成为经典RLHF管道的替代方案。然而,尽管DAAs不使用单独的代理奖励模型,但它们仍然经常因过度优化而恶化。虽然所谓的奖励黑客现象对DAA来说并没有明确的定义,但我们仍然发现了类似的趋势:在更高的KL预算下,DAA算法表现出与经典RLHF算法类似的退化模式。特别是,我们发现DAA方法不仅在广泛的KL预算范围内恶化,而且往往在数据集的单个纪元完成之前就恶化了。通过广泛的实证实验,这项工作制定并正式化了DAA的奖励过度优化或黑客问题,并探讨了其在目标、训练制度和模型尺度上的后果。
大型语言模型(LLM)的最新进展极大地拓宽了它们的能力,使其能够应用于代码生成、数学推理、工具使用和交互式通信。这些改进使LLM在各个领域得到了普及。从人类反馈中强化学习(RLHF)在这些进步中发挥了重要作用,现在已成为复杂的法学硕士培训制度的组成部分[10,55]。在对齐之前,LLM在庞大的文本尸体上训练以预测后续的标记[45,8]通常很难操作和使用。如今,领先的LLM结合了RLHF框架的变体[14,68,36],以使其与人类意图相一致,这通常涉及一个多阶段的过程。具体来说,用户评估对各种提示的模型响应,以训练一个包含人类偏好的奖励模型[10,55,71,5,61]。然后,改进的LLM使用强化学习(RL)算法使预期的学习奖励函数最大化[50,1,64]。尽管其有效性,但该过程复杂且计算密集,特别是在后期阶段。
古德哈特定律[25,11]指出,“当一项措施成为目标时,它就不再是一项好措施”,这通常被认为是RLHF的核心缺点。标准RLHF方法优化了一个学习过但不完美的奖励函数,这最终放大了奖励模型的缺点。根据经验,这种现象首先由Gao等人[21]广泛描述,他们创造了“奖励超过优化”一词,并在最近的研究结果中得到了一致的体现[61,16,14]。虽然在上述RLHF过程的背景下研究了奖励过度优化,但最近用于对齐LLM的当代方法绕过了奖励学习过程,因此需要对过度优化现象进行新的表征。
这种新的广义算法,我们称之为直接对齐算法(DAAs),通过在强化学习阶段导出的最优策略直接重新参数化奖励模型,绕过了传统的RLHF管道。DAA方法,如直接偏好优化[46],已经越来越受欢迎[14,28],因为它们通常会减少计算需求。然而,尽管没有拟合奖励函数,DAAs仍然表现出与使用学习奖励函数的传统RLHF方法类似的过度优化趋势。从某种意义上说,这是令人困惑的:DAAs可以被视为简单地通过监督学习来学习一个奖励函数,从中可以确定地映射出最优策略,但似乎比简单的监督学习更重要。
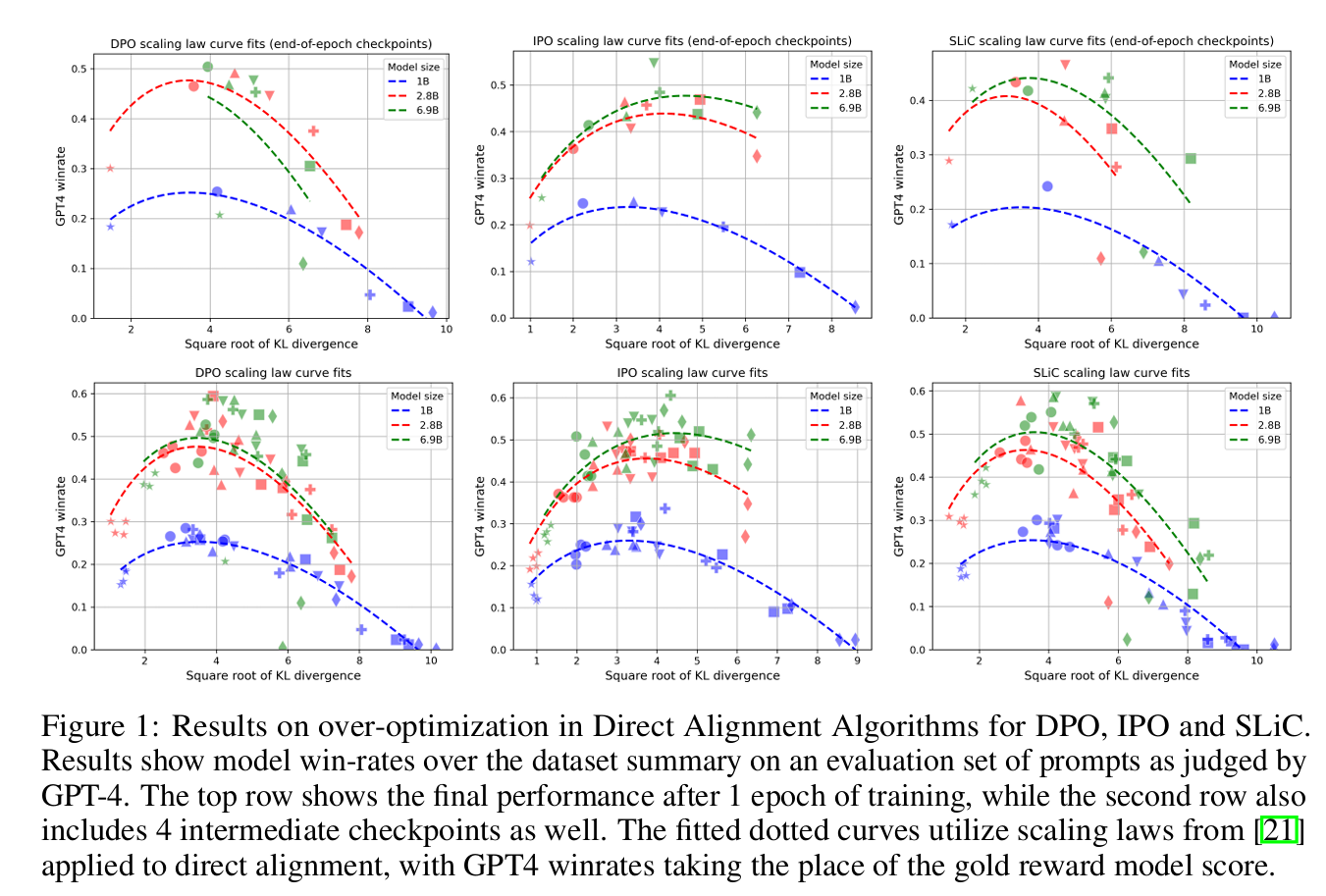
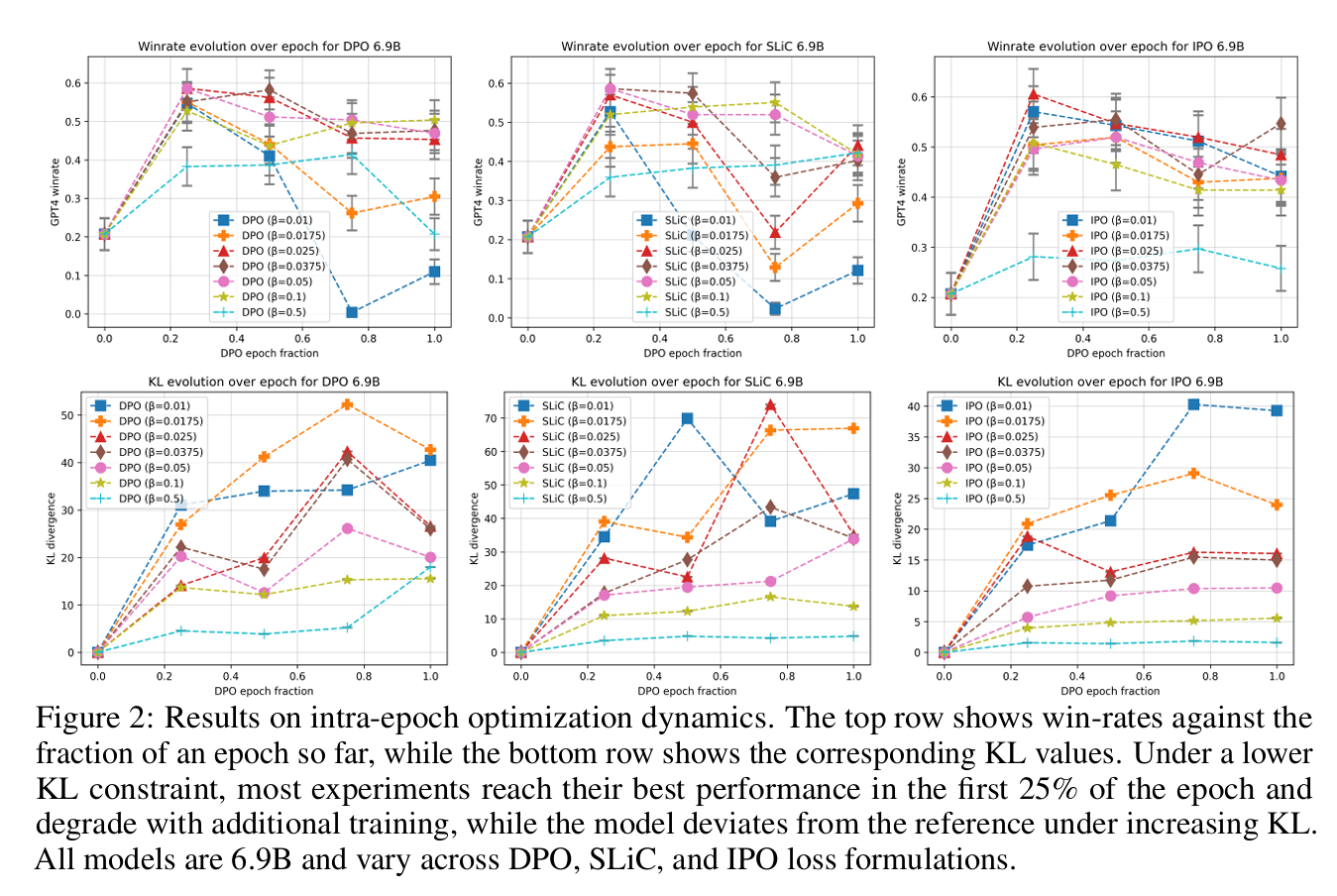
在这项工作中,我们通过广泛的实验研究了DAA算法中存在的过拟合现象。首先,我们在DAA框架下统一了许多不同的最新方法[46,67,4]。然后,在不同的模型尺度和超参数下,我们证明DAA表现出一种与RLHF[21]中先前观察到的相一致的奖励过度优化。具体来说,我们发现在不同的KL散度预算下,DAAs表现出与RLHF中发现的退化模式相似的退化模式。有趣的是,我们还发现,单个纪元内的性能并不总是像DAA预期的那样一致。最后,我们通过诉诸DAAs中使用的优化问题的欠约束性质来解释为什么会发生这种情

2.2 RLHF中的奖励利用
不幸的是,在不仔细调整RL阶段的情况下重复上述过程可能会导致灾难性的性能。这是因为在RLHF的背景下,LLM政策正在优化替代奖励估计rϕ(x,y),而不是像其他领域那样优化真实的奖励函数。因此,先前的工作已经观察到,虽然LLM根据方程式(3)的预期回报增加,但模型输出的实际质量可能会降低[54,43,9,34]。在RLHF文献中,这种奖励利用或黑客问题的特定实例[3]通常被称为奖励“过度优化”,并在对照实验[21]和用户研究[14]中进行了实证研究。对于这种现象的发生,有两种普遍的解释。
1.OOD鲁棒性:在经典RLHF流水线中,使用πθ的非策略样本优化RL目标(方程式(3))。这意味着使用可能不在分布范围内的看不见的模型样本不断查询奖励函数。除了奖励建模分布的支持外,rϕ可能会为低于标准的响应分配高奖励,导致政策在可能不好的情况下相信它做得很好。虽然KL正则化项旨在防止模型偏离分布太远,但事实证明,仅凭这一项不足以防止奖励黑客攻击[21]。
2.奖励规格错误。习得的奖励函数可能会表现出虚假的相关性,导致它们更喜欢意外的行为。虽然这个问题不是法学硕士研究的前沿,但众所周知,它在RL中普遍存在[43,34]。解决这些问题的大多数努力都存在于鲁棒性和离线RL文献[13,66,16]的交叉点,并使用认知不确定性的度量来惩罚预测的奖励。
由于其复杂的多步骤性质,最近的工作寻求了经典RLHF管道的替代品。一类新的算法,我们大致将其归类为直接对齐算法(DAAs),使用用户反馈直接更新LLM的策略πθ,而不是为其拟合奖励函数,然后采用RL算法。也许最著名的例子是直接偏好优化(DPO)。DPO以及其他DAA是使用等式(3)[70]中RLHF目标的闭式解推导出来的,π∗(y|x)├πref(y|x)er(x,y)/β,其中r(x,y)是地面真值奖励。通过在这种关系中分离r(x,y)并将其代入等式(2)中的奖励优化目标,我们得出了一个总体目标,该目标允许我们使用反馈数据直接训练LLM:
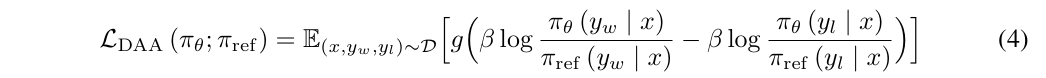
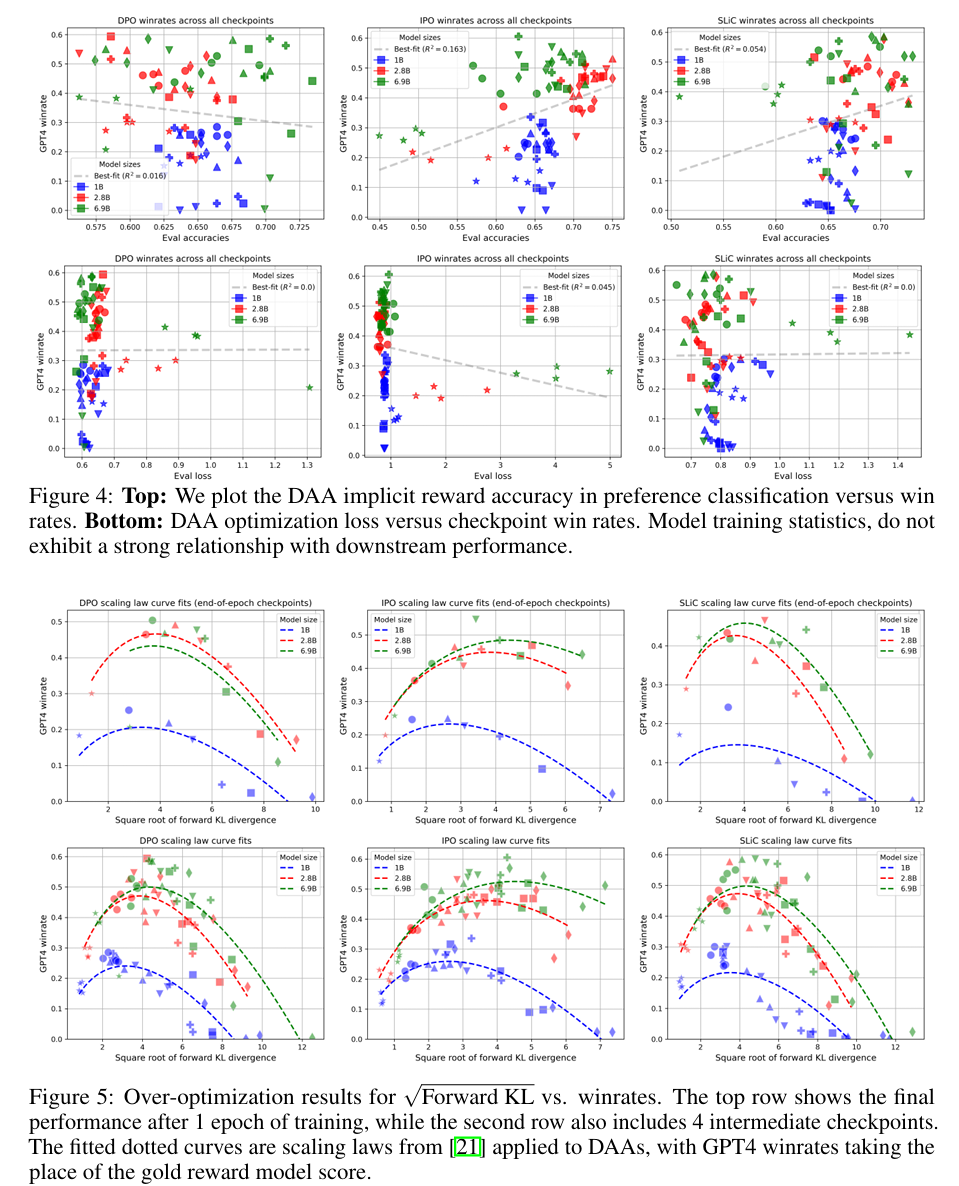
3.4奖励指标相关性
之前的工作通过分类准确性来衡量排名设置中的奖励模型质量。我们在图4中评估了DAA隐式奖励模型准确性与策略绩效之间的关系。DPO和SLiC算法在奖励模型准确性和下游模型性能之间几乎没有相关性。IPO模型显示出微弱的正相关关系,但经进一步检验,这完全是由于模型规模的扩大——更强的模型既能更好地拟合数据,也能产生更好的世代,但在每个特定的模型规模内,DAA隐含奖励准确率与实际政策绩效之间没有明显的关系。在将经验DAA损失与模型性能进行比较时,也存在类似的观察结果,这与监督预训练和指令调优中的观察结果相反[30]。