
现代强化学习至少受到三条教条的制约。第一个是环境聚光灯,指的是我们倾向于关注建模环境而不是代理。第二,我们将学习视为寻找任务的解决方案,而不是适应。第三种是奖励假说,该假说认为所有目标和目的都可以被视为奖励信号的最大化。这三条教条在很大程度上塑造了我们所认为的强化学习科学。虽然每一种教条都在发展这一领域中发挥了重要作用,但现在是时候让它们浮出水面,反思它们是否属于我们科学范式的基本组成部分了。为了实现强化学习作为研究智能代理的规范框架的潜力,我们建议是时候彻底摆脱第一和第二条教条,并采用细致入微的方法来解决第三条教条了。
1.智能代理的范式
在《科学革命的结构》一书中,托马斯·库恩区分了科学活动的两个阶段(库恩,1962)。第一个阶段库恩称之为“常规科学”,他将其比作解谜,第二个阶段他称为“革命性”阶段,包括对库恩统称为“范式”的科学的基本价值观、方法和承诺的重新想象。人工智能(AI)的历史可以说包括这两个阶段之间的几次波动,以及几种范式。第一阶段始于1956年的达特茅斯研讨会(McCarthy等人,2006),可以说一直持续到Lighthill等人(1973)发表报告的某个时候,该报告被认为对第一个人工智能冬天的到来做出了重大贡献(Haenlein&Kaplan,2019)。在此后的几十年里,我们见证了各种方法和研究框架的兴起,如符号人工智能(Newell&Simon,1961;2007)、基于知识的系统(Buchanan等人,1969)和统计学习理论(Vapnik&Chervonenkis,1971;Valiant,1984;Cortes&Vapnik,1995),最终出现了深度学习(Krizhevsky等人,2012;LeCun等人,2015;Vaswani等人,2017)和大型语言模型(Brown等人,2020;Bommasani等人,2021;Achiam等人,2023)。
在过去的几年里,人工智能系统和应用程序的激增已经无可救药地超过了我们最好的学习和智能科学理论。然而,作为科学家,我们有责任提供了解该领域当前和未来文物的方法,尤其是当这些文物将改变社会时。我们认为,反思当前的范式并超越它是解开这种理解的关键要求。在这份立场文件中,我们提出两项主张。首先,强化学习(RL)是智能代理科学完整范式的一个很好的候选者,正是因为“它明确地考虑了目标导向的代理与不确定环境交互的整个问题”(第3页,Sutton&Barto,2018)。其次,为了让强化学习发挥这一作用,我们必须反思我们科学的组成部分,并转移几个重点。这些转变都是对三个“教条”或隐含假设的微妙偏离,总结如下:
- 环境焦点(第2节):我们更强调环境建模比特工。
- 学习即寻找解决方案(第3节):我们寻找学习解决任务的代理。
- 奖励假说(第4节):假设所有目标都经过深思熟虑奖励最大化。
当我们放松这些教条时,我们得出的观点是,强化学习是对智能体的科学研究,这一愿景与强化学习和人工智能经典教科书中的既定目标(Sutton&Barto,2018;Russell&Norvig,1995)以及控制论(Wiener,2019)密切相关。作为重要的特殊情况,这些代理可能会与马尔可夫决策过程(MDP;Bellman,1957;Puterman,2014)交互,寻求确定特定问题的解决方案,或在存在奖励信号的情况下学习,以最大化奖励信号,但这并不是唯一感兴趣的情况。
2. 教条一:环境焦点
我们称之为环境聚光灯的第一个教条(图1),指的是我们共同关注建模环境和以环境为中心的概念,而不是代理。例如,代理本质上是向MDP交付解决方案的手段,而不是其本身的基础模型。
我们并不完全拒绝这种行为主义观点,但建议平衡它;毕竟,经典的RL图有两个盒子,而不仅仅是一个。我们认为,正如Russell和Norvig(1995)所说,人工智能科学最终是关于智能代理的;然而,我们的大部分思维,以及我们的数学模型、分析和中心结果,都倾向于围绕解决特定问题,而不是围绕代理本身。换句话说,我们缺乏代理的规范形式模型。这是第一条教条的精髓
当我们说我们关注环境时,我们的意思是什么?我们建议只回答以下两个问题中的一个很容易:
1.强化学习中环境的至少一个规范数学模型是什么?
2.强化学习中代理的至少一个规范数学模型是什么?
第一个问题有一个简单的答案:MDP,或其附近的任何变体,如全副武装的土匪(Lattimore&Szepesvári,2020)、情境土匪(Langford&Zhang,2007)或部分可观察的MDP(POMDP;Cassandra等人,1994)。这些都编码了不同版本的决策问题,受制于不同的结构假设——例如,在MDP的情况下,我们通过假设有一个可维护的信息包来做出马尔可夫假设,我们称之为状态,这是对同一信息包上下一个奖励和下一个分布的充分统计。我们假设这些状态是由环境定义的,并且在每个时间步都可以被智能体直接观察到,以用于学习和决策。POMDP放宽了这一假设,只向代理揭示了一个观察结果,而不是状态。通过采用MDP,我们可以导入各种基本结果和算法,这些结果和算法定义了我们的主要研究目标和途径。例如,我们知道每个MDP都至少有一个确定性、最优、平稳的策略,并且可以使用动态规划来识别这个策略(Bellman,1957;Blackwell,1962;Puterman,2014)。此外,我们的社区在探索MDP的变体方面付出了大量努力,如块MDP(Du等人,2019)或富观测MDP(Azizzadenesheli等人,2016)、面向对象MDP(Diuk等人,2008)、Dec-POMDP(Oliehoek等人,2016年)、线性MDP(Todorov,2006)和因子MDP(Guestrin等人,2003)等。这些模型各自前沿不同类型的问题或结构假设,并激发了大量富有启发性的研究。相比之下,第二个问题(“什么是规范代理模型?”)没有明确的答案(Harutyunyan,2020)。我们可能会倾向于以一种特定的流行学习算法的形式做出回应,比如⻓-学习(Watkins&Dayan,1992),但我们认为这是一个错误。𝑄-学习只是代理背后逻辑的一个实例,但它不是对代理实际是什么的通用抽象,与MDP是一系列顺序决策问题的模型不同。正如Harutyunyan(2020)所讨论的那样,我们缺乏代理的规范模型,甚至缺乏基本的概念图。我们认为,在该领域的现阶段,这正成为一种限制,部分原因是我们对环境的关注。事实上,只关注以环境为中心的概念(如动力学模型、环境状态、最优策略等)往往会掩盖代理本身的重要作用。但是,在这里,我们希望重新激发人们对以代理为中心的范式的兴趣,这种范式可以为我们提供发展和发现代理一般原则所需的概念清晰度。目前没有这样的基础,我们甚至很难精确地定义和区分关键代理家族,如“基于模型的”和“无模型”代理(尽管Strehl等人在2006年和Sun等人在2019年给出了一些精确的定义),或者研究关于代理环境边界(Jiang,2019;Harutyunyan,2020)、扩展思维(Clark&Chalmers,1998)、嵌入式代理(Orseau&Ring,2012)、实施效果(Ziemke,2013;Martin,2022)或资源约束(Simon,1955;Griffiths等人,2015;Kumar等人,2023;Aronowitz,2023)对我们代理的更复杂问题。一般的方式。大多数以代理为中心的概念通常超出了我们领域的基本数学语言的范围,因此在我们的实验工作中没有出现。
另一种选择:也把焦点放在代理人身上。我们的建议很简单:除了环境之外,定义、建模和分析代理也很重要。我们应该在Russell&Subramanian(1994)、Wooldridge&Jennings(1995)、Kenton等人(2023)的工作基础上,建立一个代理的规范数学模型,使我们有可能发现管理代理的一般规律(如果存在的话),并呼应Sutton(2022)的呼吁。我们应该从事基础工作,以建立表征重要代理属性和家族的公理,就像Sunehag和Hutter(2011;2015)和Richens和Everitt(2024)的工作一样。我们应该以一种与我们关于代理人的最新经验数据相融合的方式做到这一点,从研究代理人的各种学科中汲取灵感,从心理学、认知科学和哲学,到生物学、人工智能和博弈论。这样做可以扩大我们理解和设计智能代理的科学努力的范围。
3法则二:学习即寻找解决方案
第二个教条植根于我们对待学习概念的方式中。我们倾向于将学习视为一个有限的过程,涉及对给定任务的解决方案的搜索和最终发现。例如,考虑RL代理学习玩棋盘游戏的经典问题,如双陆棋(Tesauro等人,1995)或围棋(Silver等人,2016)。在每种情况下,我们倾向于假设一个好的代理会玩大量的游戏来学习如何有效地玩游戏。然后,最终,在足够多的游戏之后,代理将达到最佳游戏状态,并在获得所需知识后停止学习。换句话说,我们倾向于隐含地假设我们设计的学习代理最终会找到手头任务的解决方案,此时学习可以停止。这也存在于我们的许多经典基准测试中,例如山地车(Taylor等人,2008)或雅达利(Bellemare等人,2013),在这些测试中,智能体会学习直到达到目标。一种观点认为,此类代理可以被理解为在可表示函数的空间中搜索,这些函数捕获了代理可用的可能动作选择策略(Abel等人,2023b),类似于问题空间假说(Newell,1994)。而且,关键的是,这个空间至少包含一个函数,比如MDP的最优策略,其质量足以考虑所解决的相关任务。通常,我们会对设计保证收敛到这样一个端点的学习代理感兴趣,在这个端点,代理可以停止搜索(从而停止学习)。这一过程如图2所示,并在第二条教条中进行了总结。
这种观点嵌入了我们的许多目标中,并且很自然地从MDP作为决策问题模型的使用中得出。众所周知,每个MDP都有至少一个最优的确定性策略,并且这种策略可以通过动态规划或其近似值来学习或计算。我们考虑的许多替代学习环境也是如此。另一种选择:学习即适应。我们的建议是接受学习也可以被视为适应的观点(Barron等人,2015)。因此,我们的重点将从最优性转向RL问题的一个版本,在这个版本中,代理不断改进,而不是专注于试图解决特定问题的代理。当然,这个问题的版本已经通过终身学习(Brunstkill&Li,2014;Schaul等人,2018)、多任务学习(Brunskkill&李,2013)和持续强化学习(Ring,1994;1997;2005;Khetarpal等人,2022;Anand&Precup,2023;Abel等人,2023b;Kumar等人,2023)的视角进行了探索。事实上,Sutton&Barto(2018)在教科书介绍中强调了这一观点:
当我们说强化学习代理的目标是最大化数字奖励信号时,我们当然不是坚持代理必须实际实现最大奖励的目标。试图最大化一个数量并不意味着这个数量总是最大化的。重点是强化学习代理总是试图增加它收到的奖励量。(第10页,Sutton&Barto,2018)。这是一个重点转移的问题:当我们远离最优性时,我们如何看待评估?我们如何准确地定义这种学习形式,并将其与其他学习形式区分开来?执行这种学习形式的基本算法构建块是什么,它们与我们今天使用的算法有什么不同?我们的标准分析工具,如遗憾和样本复杂性,是否仍然适用?这些问题很重要,需要围绕这种学习的替代观点重新定位。我们建议我们作为一个社区摆脱第二个教条,直接研究这些问题。
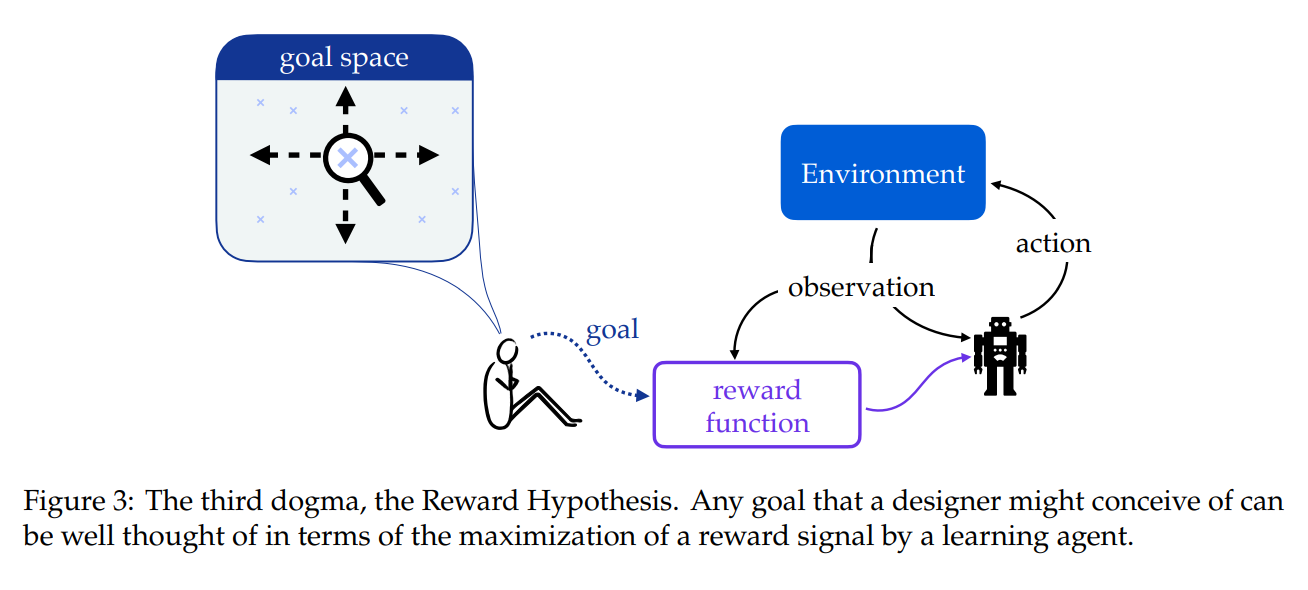
4. 法则三:奖励假说
第三个教条是奖励假说(Sutton,2004;Littman,2015;Christian,2021;Abel等人,2021;Bowling等人,2023),它指出“我们所说的目标和目的都可以很好地被认为是接收到的标量信号(奖励)的累积和的预期值的最大化。”首先,重要的是要承认这个假说根本不值得被称为“教条”。正如最初所说,奖励假说旨在围绕目标和目的组织我们的思维,就像之前的预期效用假说一样(Machina,1990)。而且,奖励假说以一种方式为强化学习的研究计划播下了种子,这种方式导致了我们许多最著名的结果、应用和算法的发展。
然而,随着我们继续探索智能代理的设计(Sutton,2022),认识到假设中的细微差别非常重要。特别是Bowling等人(2023)在Pitis(2019)工作的基础上进行的最新分析;Abel等人(2021)和Shakerinava&Ravanbakhsh(2022)充分描述了假设为真所需的隐含条件。这些条件有两种形式。首先,Bowling等人提供了一对解释性假设,澄清了奖励假设是真是假意味着什么——大致来说,这相当于说了两件事。首先,“目标和宗旨”可以从对可能结果的偏好关系来理解。其次,如果价值函数诱导的对代理的排序与对代理结果的偏好诱导的排序相匹配,则奖励函数会捕获这些偏好。然后,根据这种解释,当且仅当偏好关系满足四个冯·诺伊曼-摩根斯坦公理(von Neumann&Morgenstern,1953)和第五个鲍林等人的调用𝛾-时间无关性时,存在一个马尔可夫奖励函数来捕捉偏好关系。这很重要,因为它表明,当我们写下马尔可夫奖励函数来捕捉一个期望的目标或目的时,我们是在强迫我们的目标或宗旨遵守五个公理,我们必须问自己它是否总是合适的。例如,考虑张(2015)讨论的伦理学价值观不可比性(或不可测量性)的经典挑战。也就是说,某些抽象的美德,如幸福和正义,可能被认为是彼此无法比拟的。或者,同样地,两种具体的体验可能是不可测量的,比如在海滩上散步和吃早餐——我们如何用同一种“货币”来衡量每种体验?张指出,如果不进一步参考特定的用途或背景,两个项目可能无法比较:“一根棍子不能大于一个台球……它必须在某些方面更大,比如质量或长度。”然而,第一个公理,完备性,严格要求隐式偏好关系在所有体验对之间分配一个真正的偏好。因此,如果我们将奖励假设视为真,我们只能将目标或目的编码在一个拒绝不可比性和不可测性的奖励函数中。值得注意的是,Aumann(1962)特别批评了完备性,因为它对持有偏好关系的个人提出了要求。最后,完备性公理并不是限制可行目标和目的空间的唯一公理;公理三,无关替代方案的独立性,也因阿莱斯悖论而拒绝了风险敏感的目标(阿莱斯,1953;Machina,1982)。
另一种选择:认识并拥抱Nuance。我们的建议是简单地提请注意标量奖励的局限性,并向其他语言开放,以描述代理的目标。重要的是,当我们通过奖励信号表示目标或目的时,我们要意识到我们对所考虑的可行目标和目的所施加的隐含限制。我们应该熟悉五个公理的要求,并意识到当我们选择写下奖励函数时,我们可能会放弃什么。在后一点上,未来的工作有着巨大的机会。同样值得强调的是,偏好本身只是描述目标的另一种语言——可能还有其他语言,在我们思考目标寻求的方法中撒一张大网很重要。
5讨论我们在这里认为,强化学习的长期愿景应该是为智能代理科学提供一个全面的范式。为了实现这一愿景,我们建议是时候将我们的关系与迄今为止塑造强化学习各个方面的三个隐含教条相协调了。这三条教条相当于过度强调(1)环境,(2)寻找解决方案,以及(3)奖励作为描述目标的语言。此外,我们对如何进行与这些教条微妙偏离的研究提出了初步建议。首先,我们应该把代理人作为我们研究的中心对象之一。其次,我们必须超越研究为特定任务找到解决方案的代理,还要研究从经验中不断改进的代理。第三,我们应该认识到将奖励作为目标语言的局限性,并考虑其他选择。开放式问题。这些建议中的每一个都可以转化为重要的研究问题,我们鼓励社区进一步探索。首先,我们的代理规范模型是什么?最近出现了几项提案,并在许多方面达成一致。采用一种观点而不是另一种观点的后果是什么?试剂中哪些成分是必需的,而不是无关的?我们建议仔细考虑这些问题,并采用代理人标准模型的惯例。这种模型可用于澄清旧问题,并围绕以代理为中心的概念开辟新的研究方向,如代理环境边界(Todd&Gigerenzer,2007;Orseau&Ring,2012;Harutyunyan,2020)、实施(Ziemke,2013;Martin,2022)、资源约束(Simon,1955;Ortega,2011;Braun&Ortega)、Ortega等人(2015;Griffiths等人,2015;Kumar等人,2023;Aronowitz,2023)和嵌入式代理(Orseau和Ring,2012.)。其次,当我们放弃任务解决方案的概念时,学习的目标是什么?换句话说:当找不到最优解时,我们如何思考学习?我们如何开始评估这些代理人,并衡量他们的学习进度?第三,我们建议对代理人目标的合理解释采取各种各样的观点。这包括继续接受奖励最大化的经典观点,但也考虑了不同的目标,如平均奖励(Mahadevan,1996)、风险(Howard&Matheson,1972;Mihatsch&Neuneier,2002)、约束(Altman,2021)、逻辑目标(Littman等人,2017),甚至开放式目标(Samvelyan等人,2023)。关于“教条”一词。本文的标题和“教条”一词的使用是对奎因(1951)的“经验主义的两个教条”的致敬。“教条”一词对每一项原则的负面影响都比我们预想的要大(尽管,正如库恩(1963)所指出的那样,教条在科学中也有作用)。事实上,正如所讨论的那样,奖励假说最初被认为是一个如其名称所示的假说。尽管如此,这一原则通常被视为构建强化学习领域其他部分的前提,类似于丘奇-图灵论文构建计算的方式——它们都是大多数研究项目的标准前科学承诺(Lakatos,2014)。另外两种教条都是隐含的,而不是我们经常公开和接受的惯例;例如,很少看到强化学习中的工作积极反对思考代理人或代理的重要性。相反,大多数强化学习研究都是通过围绕动态规划和MDP构建我们的研究问题来开始的。从这个意义上说,社区已经被吸引到具体的良好研究路径上,这些路径首先涉及建模环境,而不是直接涉及代理。同样的隐含特征也适用于第二个教条:由于我们关注MDP和相关模型,我们研究的RL问题的实例往往也有一个结构良好的解决方案,已知可以通过动态规划或时间差分学习等手段发现。然后,我们经常使用涉及算法的语言,通过收敛到最优策略来解决任务,反映了第二教条的影响。正是在这个意义上,我们认为“教条”一词适合前两个:我们倾向于不质疑我们研究计划的这些方面,但它们影响了我们的许多方法和目标。值得注意的是,采用这三个教条背后的情绪是可以理解的:通过从马尔可夫模型构建我们的研究,我们可以利用一套基于动态规划的易于理解的高效算法,这要归功于Bellman(1957)、Sutton(1988)、Watkins(1989)和其他人的开创性工作。随机近似的基本结果(Robbins&Monro,1951)影响了许多经典结果,如876;-Watkins和Dayan(1992)的学习或Tsitsiklis和Van Roy(1996)的函数逼近TD学习。灵感。我们并不是第一个建议超越其中一些公约的人。Hutter(2000;2002;2004)及其同事(Lattimore&Hutter,2011;Leike,2016;Cohen等人,2019)关于一般强化学习的工作长期以来一直在最普遍的环境中研究强化学习。事实上,Hutter(2000)关于AIXI的原始工作的既定目标是“……引入通用的人工智能模型”(第3页)。同样,各种工作都明确地关注代理。例如,Russell&Norvig(1995)的经典人工智能教科书将人工智能定义为“对从环境中接收感知并执行动作的代理的研究”(第viii页),并围绕“智能代理的概念”(第vii页)构建了这本书。Russell和Subramanian(1994)还对目标导向的代理进行了总体阐述,这塑造了随后以代理为中心的大部分文献——其中引入的代理函数最近被用作代理的一个模型(Abel等人,2023a;b)。Sutton(2022)提出了“寻求智能决策者的共同模型”,并就如何构建这一追求提供了初步建议。Dong等人(2022)和Lu等人(2021)的工作建立在以代理为中心的建模传统之上,详细描述了代理内部机制的可能构成,类似于Sutton。Kenton等人(2023年)和Richens&Everitt(2024年)的进一步工作探索了代理的因果视角,给出了具体的定义和有见地的结果。在人工智能之外,代理主体本身就是一个重要的话语主体——我们建议读者参考Barandiaran等人(2009)和Dretske(1999)的作品或Tomasello(2022)和Dennett(1989)的书籍,以获取附近社区的进一步见解。同样,各种各样的工作探索了思考目标的替代方法。例如,Little&Sommer(2013)研究了一个学习其环境预测模型的代理,并使用信息论工具为这项研究奠定了基础。这在精神上与Friston(2010)倡导的自由能量原理相似,Hafner等人(2020)最近的工作探索了与RL的联系。偏好也被用作奖励的替代品,如基于偏好的RL(Wirth等人,2017),最近一系列关于人类反馈的RL的工作(Christiano等人,2017;MacGlashan等人,2016;2017)现在在当前的语言模型研究浪潮中发挥着重要作用(Achiam等人,2023)。其他人提出了使用各种逻辑语言来实现基础目标,如线性时态逻辑(Littman等人,2017;Li等人,2017,Hammond等人,2021)和附近的结构,如奖励机器(Icarte等人,2022)。Shah等人(2021)提出的另一种观点明确地将辅助游戏的框架(Hadfield-Menell等人,2016)与奖励最大化进行了对比,并认为前者为设计辅助代理提供了一条更有说服力的途径。最后,各种工作考虑了超出预期累积回报的目标寻求形式,如有序动态规划(Koopmans,1960;Sobel,1975)、凸RL(Zahavy等人,2021;Mutti等人,2022;2023)、其他偏离预期的情况(Bellemare等人,2017;2023),或通过纳入其他目标,如约束(Le等人,2019;Altman,2021)或风险(Mihatsch&Neuneier,2002;Shen等人,2014;Wang等人,2023)。其他教条。强化学习的基本哲学中还有许多其他固有的假设,我们没有讨论过。例如,人们通常关注从白板状态学习的代理,而不是考虑学习的其他阶段。我们还倾向于采用以几何折扣时间表为目标的累积折扣奖励,而不是使用双曲线时间表(Fedus等人,2019),或者考虑环境状态的存在,而不是部分可观察的设置(Cassandra等人,1994;Dong等人,2022)。我们认为,反思这些和其他观点也很重要,但它们已经受到了社会的广泛关注。结论。我们希望这篇论文能够重振RL社区,超越我们目前的框架进行探索。我们认为,这始于接受强化学习是智能代理整体范式的良好候选者这一愿景,并继续仔细反思我们科学实践的价值观、方法和要素,这将使这一范式蓬勃发展。