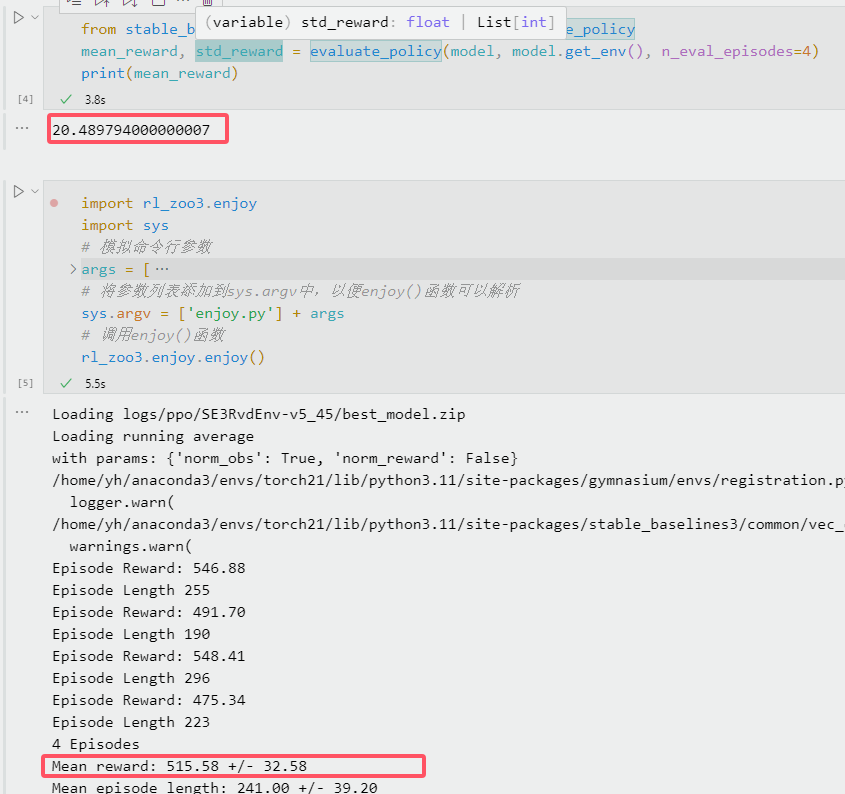
一个已经训练好的PPO模型(使用rl_zoo3.train训练),分别使用stablebaseline3的evaluate_policy和rl_zoo3的rl_zoo3.enjoy测试出来的score差别很大,evaluate_policy和自己写代码循环测出来都是几十,rl_zoo3.enjoy和训练过程中tensorboard看到的都是五百分附近
进一步发现这种现象只出现在我自己定义的一个环境,对如CartPole-v1的经典环境并没有发现该类现象(sb3和rl_zoo3的测试得分几乎一样)
输出每一个reward对比看看是哪个出了问题