I recently read papers, including "Conservative Q-Learning for Offline Reinforcement Learning" and "Cal-QL: Calibrated Offline RL Pre-Training for Efficient Online Fine-Tuning".
According to the paper of CQL, I think if a state-action pair exists in the dataset collected by behavior policy, it will not be be punished (the regular term is zero) when training. Because the two sub-terms of the penalty term cancel out. Or if it not in the dataset, it will be punished by the first term, as shown by the following Figure 1 (the regular term is highlighted in blue). Because if the state-action pair is not in dataset, the second sub-term of the penalty term will be zero. So for the state-action pairs collected by behavior policy, perhaps they would be over-estimated due to maximization and bootstrapping training. Because even if a target network is used, it can only alleviate the overestimation problem. Therefore, the relationship between the CQL's estimated values and the true values may look like as shown in Figure 2. Is what I said above right?

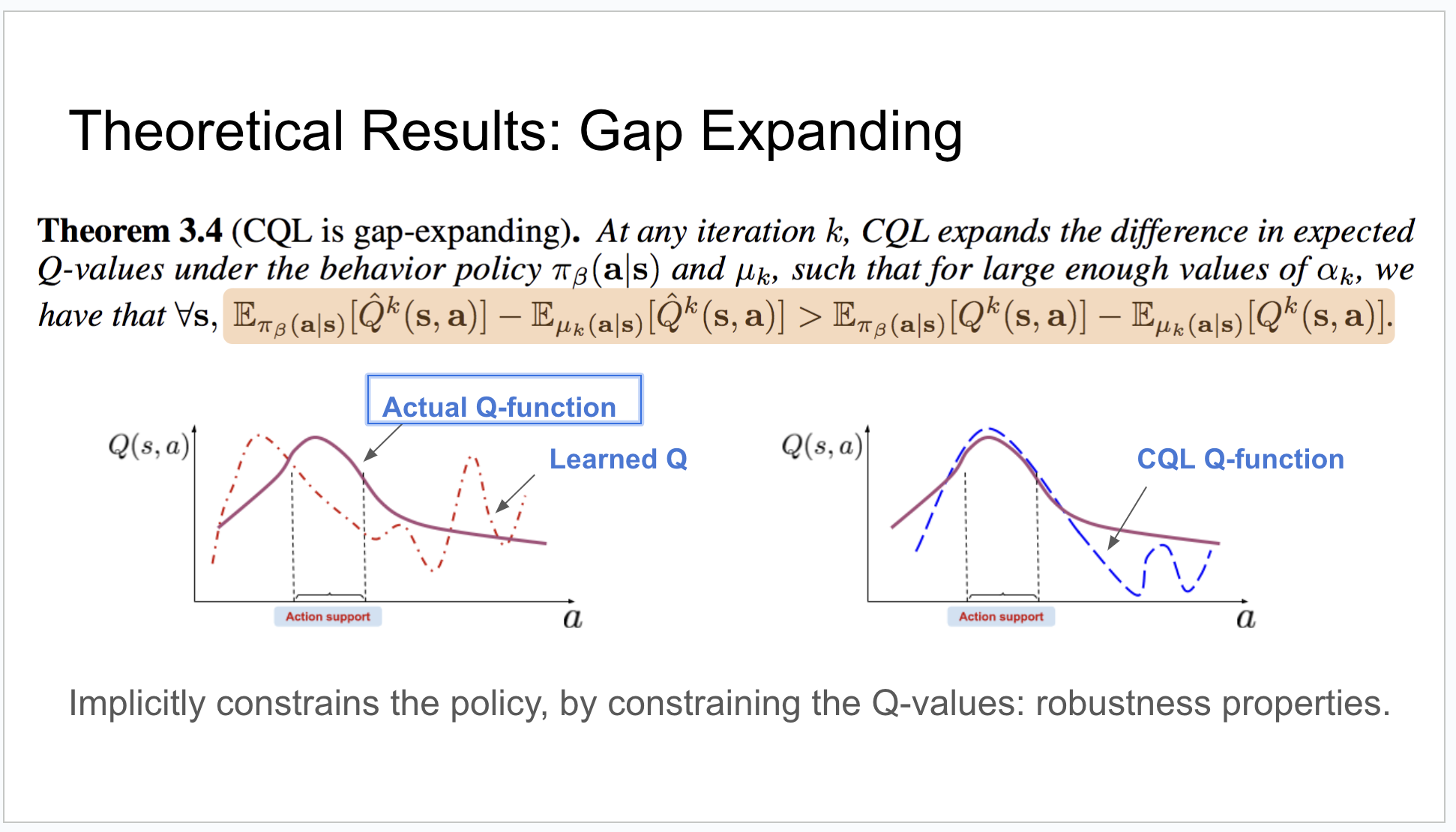
But in Cql-QL, we can see that the CQL's estimated values are significantly lower than the true values, as shown in Figure 3.
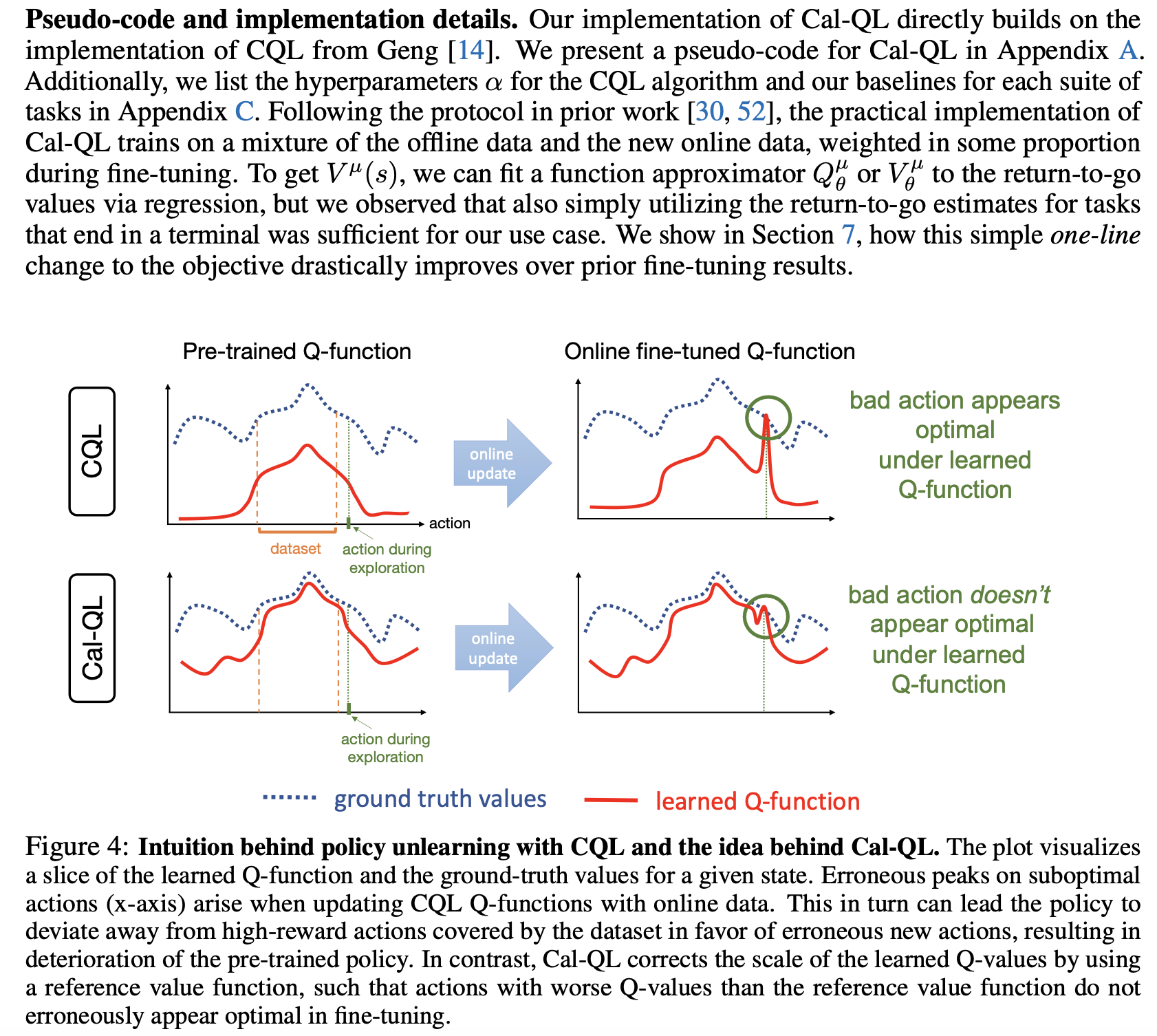
In the papers CQL and Cql-QL, there is a contradiction in the description of the relationship between CQL's estimated values and true values. How to understand this? Is my description above right?