2019年
最近刚好做这方面的survey……Multi-Agent RL指环境中的Agent多余一个,考虑的问题从single扩充到Multi的角度,问题的维度和角度相较single-Agent有较大的不同。1)环境非静态,在Agent与环境的交互过程中,Agent与环境,Agent与Agent之间都会进行交互,会导致环境实时都在变化,传统的马尔科夫过程处理方法不再适用;2)不能使用DQN使用的经验回放机制,具体而言,因为环境状态随时间变化,取得的经验信息没有参考意义……等具体文末附件根据Pablo Hernandez-Leal等人的分类,当前的MARL RL主要工作方向包括:1)Analysis of emergent behaviors,主要对当前的RL算法进行研究,偏向研究,诸如DQN,PPO系列,包括对Agent间的合作、对抗或者兼具两者进行分析。

(2)Learning communication,学习Agent间的交流,电子系专业的小伙伴们抓紧了。

(3)Learning cooperation,学习Agent间的合作,顾名思义,不赘述。
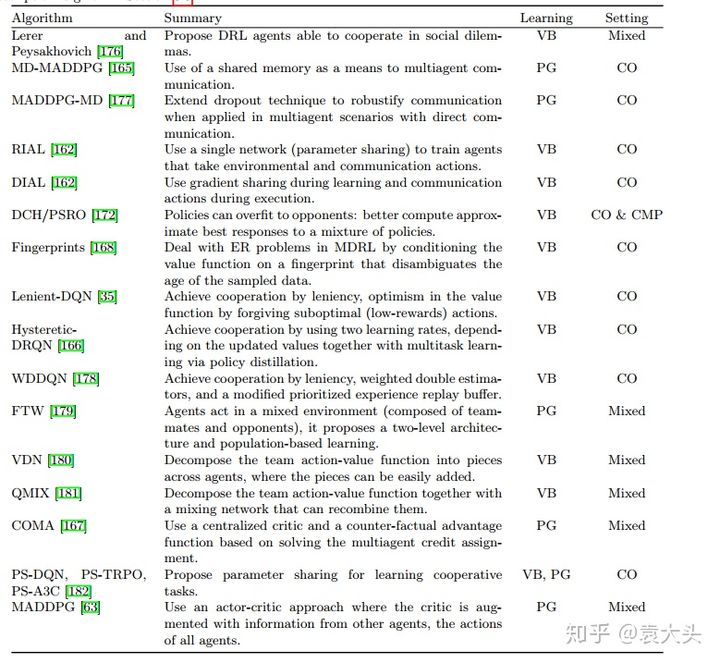
(4)Agents modeling agents,智能体之间建模,包括给对手和队友建模,而不是单纯将其他Agent当做环境的一部分。
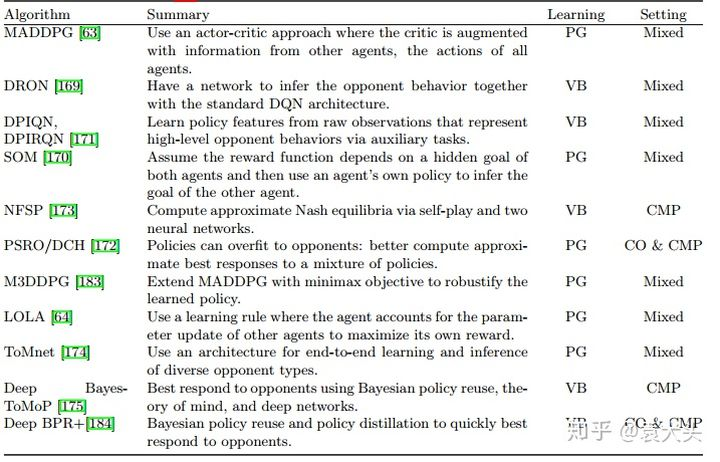
其次,也有MDRL,结合多智能体深度强化学习及结合MDRL与transfer Learning的方面等。总体而言,MARL或者MDRL是一个难度较大的方向和话题,对数学和理论要求比较高,然而很多方面还相对薄弱甚至空白,做该方向的多多交流。对论文感兴趣的可以按参考文献检索,应该会收获较多...
刚好在AAMAS19的会场当volunteer,坐着无聊,简单回答一下。其实随便search一下multi-agent reinforcement learning,survey/tutorial,可以得到一堆文章list。但是如果只推荐一个survey的话,可以考虑看:Is multiagent deep reinforcement learning the answer or the question? A brief survey。这个survey将最近的MADRL的研究工作分成了4大类:Analysis of emergent behaviors;Learning communication;Learning cooperation;Agents modeling agents。对于每一类,都介绍了题主所谓的“流派、思想、著名工作”,我就不重复了。相对于其他survey,这个survey划分的四个分类更符合我对当前工作的理解,而且也都是主流工作(其实第一个大类我现在关注不太多了,不知道近期还有没有比较好的工作)。而且文章对于当前比较好的工作的总结比较全面,能叫出名字的DIAL、CommNet、MADDPG、COMA、BiCNet、VDN、QMIX、DRON、LOLA、DPIQN、SOM、ToMnet都有收录(虽然有一些收录的工作其实也不太好,但不妨碍这篇survey很好)。最后的open question、learned lesson也都是很好的研究方向。最后我自己觉得还可以思考的方向是:如何将single-agent RL中的思想扩展到multi-agent setting;或者更一般的,如何将ML/DL的思想引入到MADRL中,比如very deep net、skip connection等。这篇文章相关联的几篇survey也可以看一下,都很不错。P. Stone, Multiagent learning is not the answer. It is the question, Artificial Intelligence 171 (2007) 402–405.Y. Shoham, R. Powers, T. Grenager, If multi-agent learning is the answer, what is the question?, Artificial Intelligence 171 (2007) 365–377.看这三篇文章的title,是不是想笑。起名字真是艺术。然后从AAMAS19的program中看一下领域内的大佬以及大家在讨论的问题:


2020年
Multi-Agent已经是比较传统的方向了,有几十年的历史,出了很多理论和证明,但主要因为状态空间和行动空间爆炸的难题,在应用上一般来说只用于解一些较小规模并且有明确数学模型的问题。有一些特定方向,比如说Multi-agent planning,通过把多智能体建模成大规模的programming,可以解比较大的问题,当然缺点就是每面对一个新的环境就要重解一次,不像人那样可以随机应变。因为最近Deep RL在游戏上大获成功,大家自然会想到如何用神经网络去建模每个agent的策略和值函数,从而让原本不可解的大规模多智能体问题变得可解。目前的一些有名的工作大家可以在最近的一些survey里面找到。之前的回答也涵盖了。以下是一些将来值得关注的方向(个人见解,可能会有偏差):如何保证理论上的一致性。这个问题总的来说非常难,现在纯DRL的暴力建模方式,和传统的基于多智能体和博弈论的理论分析走的路子太不相同,如何把它们放到同一个框架下去讨论?比如AlphaZero自对弈方案训练出来的模型,其exploitability有没有理论界?Counterfactual regret minimization (CFR)和MCTS有什么关联?等等。多智能体演化的动力学分析。假设每个智能体都是利己的,各自根据最大化自己的利益来调整自己的策略,那整个系统会有什么样的行为?这又是一个巨大的问题。和常规的优化问题不同,在这种情况下,整个系统再没有一个统一的目标函数,所以会出现各种和梯度下降不一样的动力学现象,比如说会出现极限环,比如说用negative momentum可以帮助收敛,等等。如何做到非常有效的分布式执行(decentralized execution),训练的时候可以任意作弊(centralized training),可以用全信息,可以知道其它agent的内部状态,可以知道其它agent的行动目的,等等;但在测试的时候,我们希望每个agent只用自己所见进行决策,同时还能相互配合着完成任务。这是目前一个比较火的方向,但我觉得还有很多搞头。即兴组队(Adhoc team play)。现在大部分多智能体的文章都是先从头训练完团队合作,然后在测试时,看同样的团队是否能完成现有任务或新任务。但放观人类社会,一个有潜力的新人会很快适应现有团队,素未谋面的人们在初次见面时就能完成相当程度的合作,这种就包括如何“察言观色”,如何在很少的互动之后适应对方的行为,并做正确的预测。相比之下,现在用神经网络驱动的多智能体还远远不及。因为问题相当难,目前这样的文章还比较少。高效交流(Efficient Communication)。关于多智能体间自然涌现式的交流(emergent communication)已经有很多文章了。这上面翻了很多花样,比如说可以做梯度反传,可以加信道容量约束,可以量化(quantization) ,可以用现有的自然语言预训练模型,等等。但如何做到高效交流,即用最少的比特交流最多的信息,仍然很难。一个很大的麻烦是局部最优解的问题。两个人进行交流时,双方用的策略往往是彼此锁定的,如果有任意一方想要改变自己的策略,那对方也要跟着变,不然交流马上无效。这就产生了很强的局部最优的效应,而单智能体的强化学习算法,往往假设除了当前考虑的智能体之外,其它因素(包括其它的智能体)都保持不变,这样就会陷入局部极小。并且更糟糕的是,当前所用的策略越好,这个解的局部性就越强,跳出这个解的代价就越大。如何从这个局部极小里面跳出来获得更好的合作解,又是一个难题。智能体间的竞争合作。《毛选》里面说得好,谁是我们的朋友,谁是我们的敌人,这是一个首先要搞清楚的问题。目前的文章里面,队友和竞争者的关系大多是固定的,并且在整个环境的演化过程中保持不变。这当然极大方便了建模,但也就离复杂的现实生活更远。如何从智能体各自的行为中推测各自的目的,并且借助相近利益的其它智能体,来达成自己的目的,又是一个非常困难的问题。最近MIT有一篇文章用CFR来判断狼人杀类似游戏的敌友,很有意思,我相信这个方向只是刚刚开始,接下来有得好做。可复现性和评价体系。现在Multi-agent RL基本上相当于五年前的DRL,各种自制环境满天飞,评价准则也各有不同。调参较单智能体强化学习更加麻烦,调神经网络已然是玄学,叠一层RL是玄之又玄,再叠一层Multi-agent可谓易老庄三玄聚首,任何一处地方有微小的问题,整个系统就训练不起来或者效果很差。所以开源代码势在必行。研究出更稳定更成熟的算法,从而最终能应用于真实场景,也是将来的一大方向。大规模多智能体系统的数值模拟。这个我就不说了,巨大的挑战同时也是巨大的机遇。总的来说,这个方向因为有神经网络的加入,可以说重新获得了巨大的潜力。期待它今后的发展。我将来也会在这个方向上,在OpenGo项目之后继续做一些有意思的探索。
这里重点强调一个方向:(基于智能体邻域和图卷积网络)解决大量智能体协作问题。其实不要说解决大量智能体协作问题,就连解决少量智能体协作都很难,具体表现在:(1)从状态空间的角度看,单个智能体的观测往往只是整个环境状态的一部分,即多智能体环境是部分可观测的(Partially Observable)。(2)从动作空间的角度看,所有智能体的联合动作(Joint Action)空间巨大。(3)从奖励空间的角度看,环境反馈回来的奖励信号由所有智能体的联合动作决定(而不仅仅由单个智能体的动作决定),“信用分配”(Credit Assignment)问题急需解决。(4)从状态转移和奖励转移的角度看,这些转移函数对于单个智能体而言是不稳定的(Non-stationary),即同一个智能体在同一个状态下面执行同一个动作,得到的奖励信号和转移到的新状态将不再确定(因为其它智能体也在影响环境)。对于这些挑战,领域内已经有了一些主流的解决方案,例如:(1)观测历史(Observation History)作为观测;获取其它智能体的观测历史作为观测。(2)每个智能体直接生成自己的动作而不考虑联合动作。(3)差异奖励(Difference Reward)[1]、明确奖励(Clean Reward)[2]、反事实奖励(Counterfactual Reward)[3]。(4)联合动作值函数(joint Q-value function)表征所有智能体的信息,这样状态转移和奖励转移就和联合动作值一一匹配,从而解决非稳定环境问题。但是要解决大量智能体协作问题,上面的这些传统解决方案很难适用,主要是由于它们把所有的智能体当成了一个整体!一个解决大规模智能体协作的思想是对智能体划域,将所有智能体划分成协作最密切的部分智能体;然后对域内智能体进行强协调、对不同域的智能体进行适当弱协调。这种划域的好处很多,最显著的是,每个域内的智能体数量往往有限,即便所有智能体可能成千上万!其实很早的Coordination Graph [4]在就对划域思想进行了正式的描述,最近的代表工作VDN/QMIX/QTRAN [5,6,7]都是这类工作的特例。但是VDN/QMIX/QTRAN还是假设太强,认为是一个hyperlink连接所有智能体;而DCG [8]则认为智能体是pair-to-pair的关系。能不能直接根据智能体的天然拓扑构造协作邻域?北大卢宗青老师组的DGN [9]是第一个探索这方面的工作(该论文这么宣称),结合GNN和Multi-head Attention对多智能体进行协调,效果也很好,从18年提出到现在改了几轮,中了ICLR 2020。站在2020年的时间点上,再看DGN以来的各种结合GNN和Attention的工作(太多了,不再引)已经不太新鲜和有趣,虽然各自解决了论文中的测试场景,但还是觉得论文中提到的协作机制假设太强、不太容易扩展。回到最开始的出发点,还有三个问题没有解决(也是发文章的好切入点):(1)怎么对所有智能体进行动态、自适应划域?(2)怎么对同一邻域内的智能体进行强协调?(3)怎么对不同邻域内的智能体进行适当的弱协调?写了这么多,还是推一下自己最近的AAAI-2020 Oral工作吧,Neighborhood Cognition Consistent Multi-Agent Reinforcement Learning,基于邻域认知一致性的多智能体强化学习。解决的是第(2)个问题,对域内智能体进行强协调。我们受社会心理学领域内非常流行的认知一致性理论(Congnitive Consistency Theory)启发,发现多智能体协作也是适用的:对环境形成一致性的认知是实现良好协作的必要条件;此外,智能体只与具有局部感知的邻居智能体直接交互的事实表明,只要邻居智能体之间相互保持认知一致性通常足以保证系统级的协作。受上述事实启发,我们首次提出了邻域认知一致性(Neighborhood Cognitive Consistency)的概念,并将其应用于划域之后的协作多智能体系统中,为邻居智能体之间形成高效的强协作奠定了基础。其中关键步骤是:NCC-MARL 假设每个邻域都有一个真实的但隐藏的认知表征变量,然后所有的邻居智能体都通过变分推理(Variational Inference)的方法将它们的邻域特定的认知表征与这个真实的认知表征变量进行对齐(Make Alignment),经过训练,所有处于同一邻域的智能体最终都会形成一致的邻域认知。由于邻域特定认知表征之间的一致性以及智能体特定认知表征之间的差异性,相邻的智能体可以基于这两种认知表征的结合来实现即协作又个性化的策略。【实习期间的工作,感谢华为诺亚方舟决策与推理组的刘老师、郝老师、其他小伙伴,以及学校的导师肖老师,帮助非常大!】补充一句,为什么少量智能体协作还没做好,就做大量智能体协作:务实一点的看法是,这个领域的Low-Hanging Fruit还比较多,好发文章;理想一点的看法是,这个世界就是个大规模多智能体世界,大量智能体协作才是在AGI的正道上。[1] Multi-agent reward analysis for learning in noisy domains.[2] CLEANing the reward: counterfactual actions to remove exploratory action noise in multiagent learning.[3] Counterfactual multi-agent policy gradients.[4] Multiagent planning with factored MDPs.[5] Value-Decomposition Networks For Cooperative Multi-Agent Learning.[6] QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning.[7] QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning.[8] Deep coordination graphs.[9] Graph Convolutional Reinforcement Learning for Multi-Agent Cooperation
## 2021年 (欢迎大家一起补充)