在actorloss和critic_loss中,有一些我不理解的地方,可能是一些trick,希望有明白的大佬能帮我解释一下为什么这么处理:
对于actor loss:
`mu, sigma_sq = self.actor.output
pdf = 1. / K.sqrt(2. * np.pi * sigma_sq) * K.exp(-K.square(action - mu) / (2. * sigma_sq))
log_pdf = K.log(pdf + K.epsilon())
entropy = K.sum(0.5 * (K.log(2. * np.pi * sigma_sq) + 1.))
exp_v = log_pdf * advantages
exp_v = K.sum(exp_v + 0.01 * entropy)
actor_loss = -exp_v`
其中 exp_v = K.sum(exp_v + 0.01 * entropy),为什么要求和呢?为什么要sum一下呢?
论文里的算法,在求梯度的时候,就是直接对 log_pi*advantages 求导吧?并没有求和,为什么代码里要求和呢?并且网络能学习,这是trick吗?
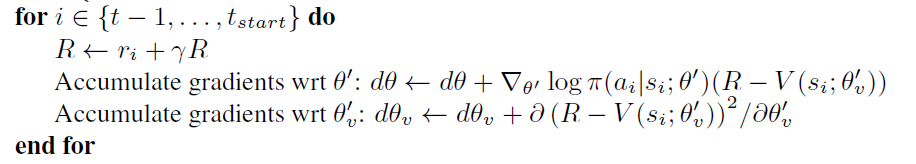
对于critic loss:
`value = self.critic.output
loss = K.mean(K.square(discounted_reward - value))`
为什么要求均值呢?用了mean?为什么啊?求求了,谁能帮我解释一下,是为了让两个loss的数量级一致么?这是一个trick吗?球球大佬解答~~~