经验的使用在强化学习(RL)中起着关键作用。 如何最好地使用这些数据是该领域的主要问题之一。 随着RL代理近年来的发展,解决了更大,更复杂的问题(Atari,Go,StarCraft,Dota),生成的数据的规模和复杂性都在增长。 为了应对这种复杂性,许多RL系统将学习问题分为两个不同的部分:经验producers(演员)和经验consumers (学习者)-允许这些不同的部分并行运行。 数据存储系统通常位于这两个组件之间的交汇处。 如何有效地存储和传输数据的问题本身就是一个具有挑战性的工程问题。
为了应对这一挑战,DeepMind发布了Reverb,这是一种高效,可扩展且易于使用的数据传输和存储系统。
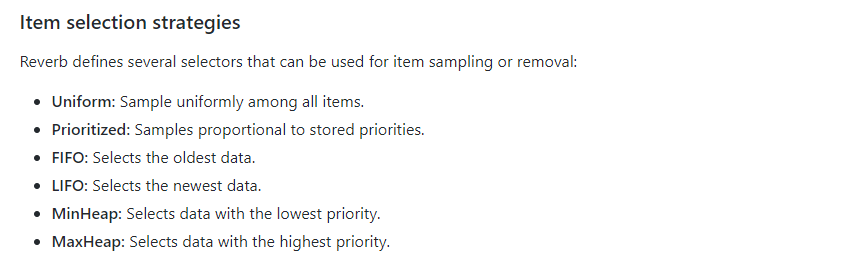
- Reverb可用于实现体验重播(优先级与否),这是许多非策略算法(包括Deep Q-Networks,深度确定性策略梯度,Soft Actor-Critic等)中的关键组成部分。但是,Reverb也可以是用于FIFO,LIFO和基于堆的队列,从而启用基于策略的方法,例如近端策略优化和IMPALA。还可以利用LIFO堆栈和堆来启用其他算法。
- Reverb的另一个优势是它的效率:它也可以用于具有许多经验丰富的生产者和消费者的大型RL智能体中,并且开销最小。研究人员已使用Reverb来管理数千名并行参与者和学习者的经验存储和传输。这种可扩展性(再加上Reverb的灵活性)使研究人员无需担心在将算法应用于需要不同规模的问题时更改基础架构组件的麻烦。
- 此外,Reverb提供了一种易于使用的机制来控制采样数据与插入数据元素的比率。 尽管这种控制形式很容易在简单,同步的设置中完成,但要让许多经验丰富的生产者和消费者都难以实现。 通过限制或限制这种速率,用户可以显式控制数据收集相对于RL实验训练的相对速率-迄今为止一直很难做到这一点。
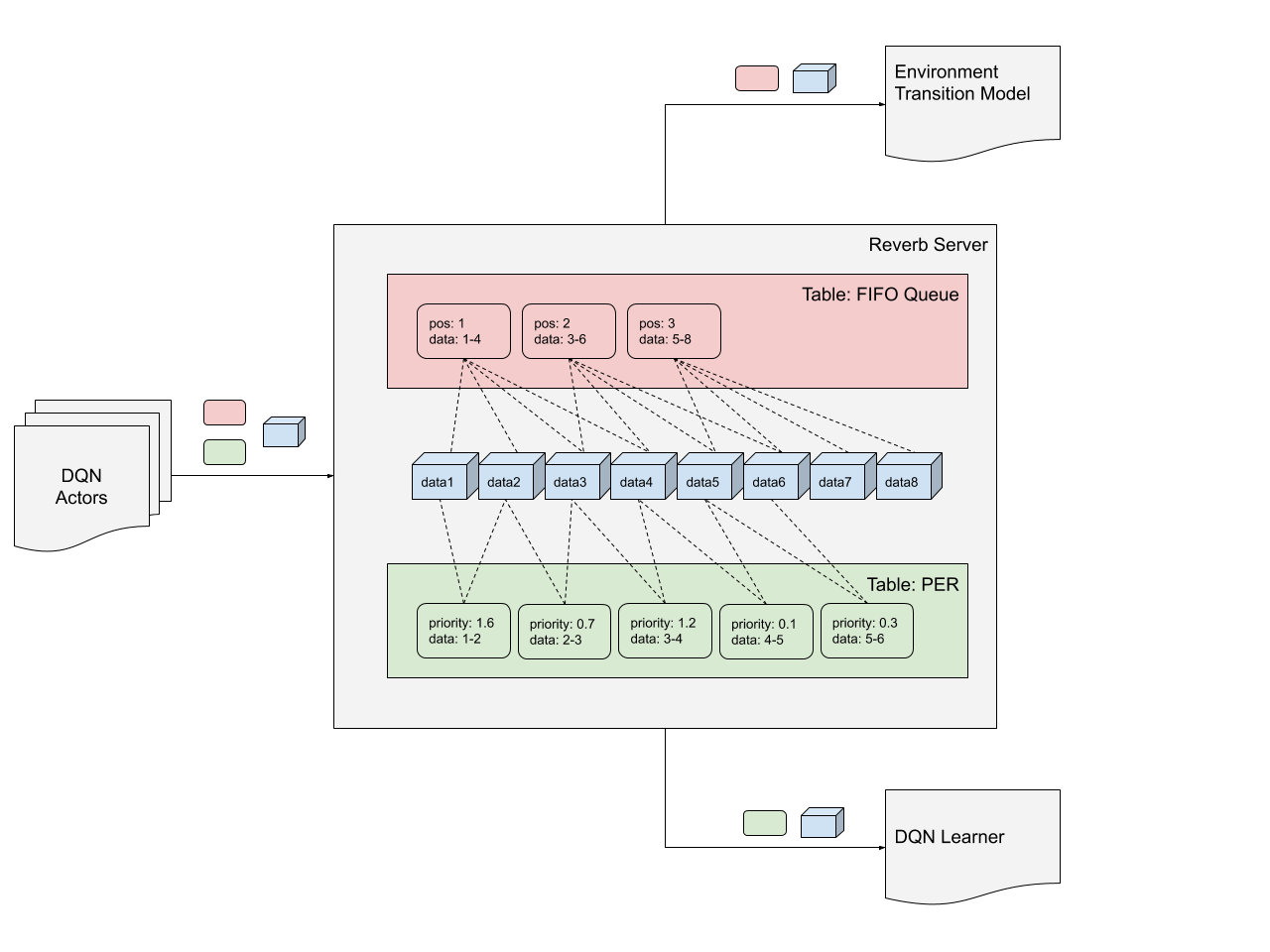
例如,可以将一个表设置为优先体验重放(PER)进行过渡(长度为2的序列),将另一个表设置为长度为3的序列的(FIFO)队列。在这种情况下,PER数据可以 用于训练DQN和FIFO数据以训练环境的转换模型。
安装和使用
⚠️ Reverb currently only supports Linux based OSes.
$ pip install dm-reverb-nightly[tensorflow]
# Without Tensorflow install and version dependency check.
$ pip install dm-reverb-nightly
# 快速使用
import reverb
server = reverb.Server(tables=[
reverb.Table(
name='my_table',
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
max_size=100,
rate_limiter=reverb.rate_limiters.MinSize(1)),
],
port=8000
)
创建客户端以与服务器通信:
client = reverb.Client(‘localhost:8000’)
print(client.server_info())
将一些数据写到表中:
# Creates a single item and data element [0, 1].
client.insert([0, 1], priorities={'my_table': 1.0})
一个项目还可以引用多个数据元素:
# Appends three data elements and inserts a single items which references all
# of them as {'a': [2, 3, 4], 'b': [12, 13, 14]}.
with client.trajectory_writer(num_keep_alive_refs=3) as writer:
writer.append({'a': 2, 'b': 12})
writer.append({'a': 3, 'b': 13})
writer.append({'a': 4, 'b': 14})
# Create an item referencing all the data.
writer.create_item(
table='my_table',
priority=1.0,
trajectory={
'a': writer.history['a'][:],
'b': writer.history['b'][:],
})
# Block until the item has been inserted and confirmed by the server.
writer.flush()
Citation
@software{Reverb,
title = {{Reverb}: An efficient data storage and transport system for ML research},
author = "{Albin Cassirer, Gabriel Barth-Maron, Thibault Sottiaux, Manuel Kroiss, Eugene Brevdo}",
howpublished = {\url{https://github.com/deepmind/reverb}},
url = "https://github.com/deepmind/reverb",
year = 2020,
note = "[Online; accessed 01-June-2020]"
}