An Overview of Multi-agent Reinforcement Learning from Game Theoretical Perspective
注:本文仅供交流学习,文献引用见末尾,欢迎大家讨论学习
继AlphaGO系列取得巨大成功之后,2019年是多智能体强化学习(MARL)技术蓬勃发展的一年。 MARL理论主要研究多智能体系统中多个智能体同时学习的问题,它是一个跨博弈论,机器学习,随机控制,心理学和优化理论的学科,拥有非常悠久的历史。尽管MARL在实践中取得了相当大的成功,但缺乏一个完整的文献综述来详细阐述现代MARL方法的博弈论基础,以及总结最近的一些进展。实际上,大多数现有综述不能完全涵盖自2010年以来的最新发展。本文将对MARL的理论基础和研究前沿进行详细地阐述。
本文分为两个部分。从§1到§4,介绍了MARL的基础知识,包括问题的表述,基本的解决方案和现有的挑战。具体来说,我们通过两个有代表性的框架,即随机博弈和estensive-form博弈,以及可以解决的不同形式的博弈,来介绍MARL理论。本部分的目的是使读者,即使是相关背景知识很少的读者,也能够掌握MARL研究中的关键思想。从§5到§9,阐述了MARL算法的最新发展。从MARL方法的分类开始,我们对以前的综述进行了总结。在后面的部分中,将重点介绍MARL研究中的几个现代主题,包括Q函数分解,多智能体软学习,网络化多智能体MDP,随机潜在游戏,零和连续游戏,在线MDP,回合制随机游戏,PSRO,一般和博弈中的近似方法,以及可用于具有无穷个agent游戏中的平均场博弈。在每个主题中,我们选择最基本和最前沿的算法。
本文的目的是,从博弈论的角度,对当前的state-of-art MARL方法进行完备的评述。最后希望这项工作能为即将进入这一领域的研究人员,和领域专家提供帮助。



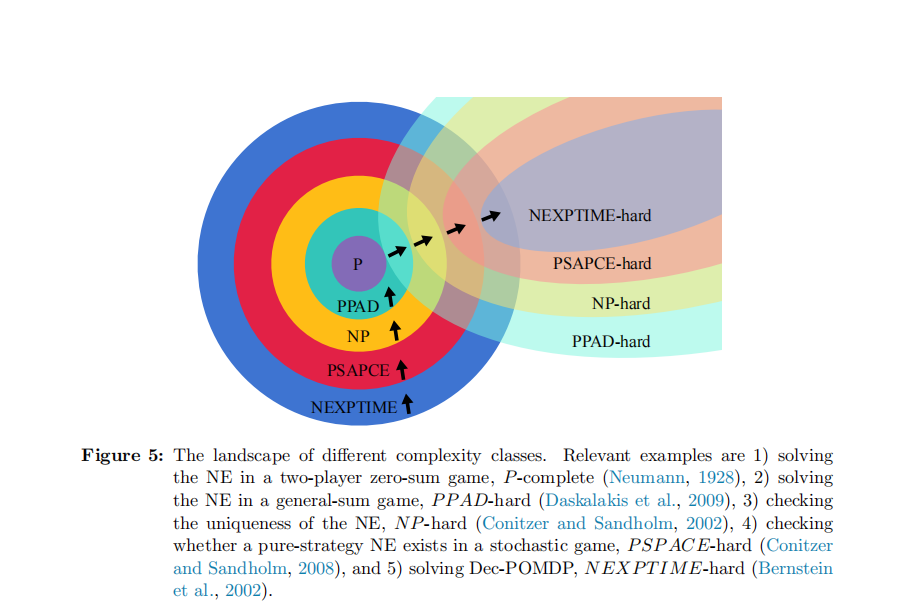
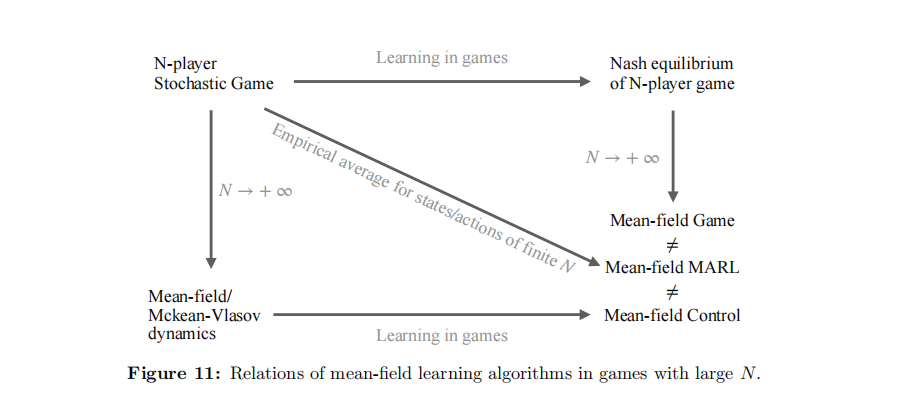
cite:
@misc{2011.00583,
Author = {Yaodong Yang and Jun Wang},
Title = {An Overview of Multi-Agent Reinforcement Learning from Game Theoretical Perspective},
Year = {2020},
Eprint = {arXiv:2011.00583},