尽管强化学习最近取得了许多成果,但我们仍然面临很多实际挑战,其中之一就是数据效率低下:在现实世界中的问题(例如,机器人)中,由于时间或硬件限制,并不能像在仿真器中(例如,video game learning)进行百万次实验。因此,在现实世界问题中,强化学习的数据高效性(data-efficiency)就显得尤为重要。就我所知,在这方面研究较为深刻的学者当属 UCL 的 Marc Deisenroth (很可惜实力不够,没申到他的博士)。Deisenroth 的成名作就是在机器人强化学习中经常使用的基线 PILCO,我之前也有专门的学习笔记。他对于利用 Gaussian Processes (GPs) 以及 Bayesian Model 等 Probabilistic Machine Learning 方法加速强化学习的学习过程、提高 sample/data efficiency 很有研究。
Probabilistic Robotics 系列的 Efficient 分章就从 Deisenroth 关于 data-efficient Reinforcement Learning 的 Talk 入手,开始阅读学习data-efficient领域的论文和最新研究成果。
Deisenroth 的 talk 链接:
Talk link
强化学习在机器人领域的问题
我们为什么需要 data-efficient RL?
这就关乎这个方向是否有意义了。可能很多做理论研究的老师和同学会觉得,完全可以通过构建仿真器的方式,使现实问题可以在simulator中并行学习。至于Sim2Real问题,大家也更多地在考虑如何将仿真器做的更逼真,以及如何在仿真器内尽可能多得模拟现实世界的参数变化,从而缩小gap。(最近也会深入学习 Transfer Learning,毕竟几个月没能静下来学习了,如果有什么新进展大家可以提醒一下)然而,Deisenroth 指出 autonomous systems 应该是 No human in the loop 的,也就意味着理论上我们期望机器人能够 Learn directly from data。我的理解是,构建仿真器的这一环节,也迫使 human 投入了大量的精力,尤其是非标机器人,因此我们希望机器人能够直接通过自主的、与现实环境的交互学习策略,这很明显是 autonomous systems 的理想形式。
什么是 data-efficient RL?
简单来说就是,机器人能够 learn from small dataset, or from few samples。(类似于 DL 中的 Few-shot learning)
如何做到 data-efficient RL?
机器人问题无非是三种:Modeling, Predicting, Decision making。
- Modeling 的能力影响了机器人对环境的理解程度,这个环境既包括 External 的环境,也包含机器人自身的运动学、动力学模型;
- Predicting 代表着给定一个控制序列,我们能够预测 long-term 的机器人行为;
- Decision making 就是 control problem,也是RL关心的核心问题。
这其中会有很多的 Uncertainty:sensor noise, unknown processes, limited knowledge (due to the sparse data),以上这些问题的解决方案就在于 Probabilistic Machine Learning。
基于以上分析,Deisenroth 在Talk中给出了三种解决方案。
Model-based Reinforcement Learning

RL 与最优控制的主要区别在于,最优控制中 transition function 是已知的,而 RL 中是未知的,且需要从 data 中学习。
因此,对于可以处理不确定性的 Probabilistic model-based RL,可以分为以下几个步骤。

Model Learning
其中最关键的就是Probabilistic model的学习。一旦学习得到的 model 有很大的 errors,势必会严重影响 Prediction 和 Decision Making 环节的准确性。这也是我在之前 MBRL 系列笔记中强调的 model-based 算法的关键问题。
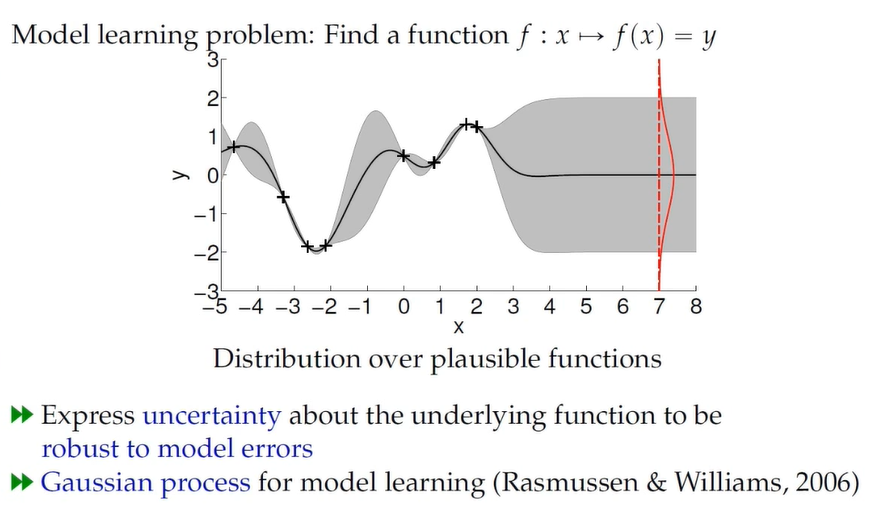
因此,需要使用 Gaussian Process 来学习 model。关于 GPs 的知识就不在这里展开了,详见
Prediction
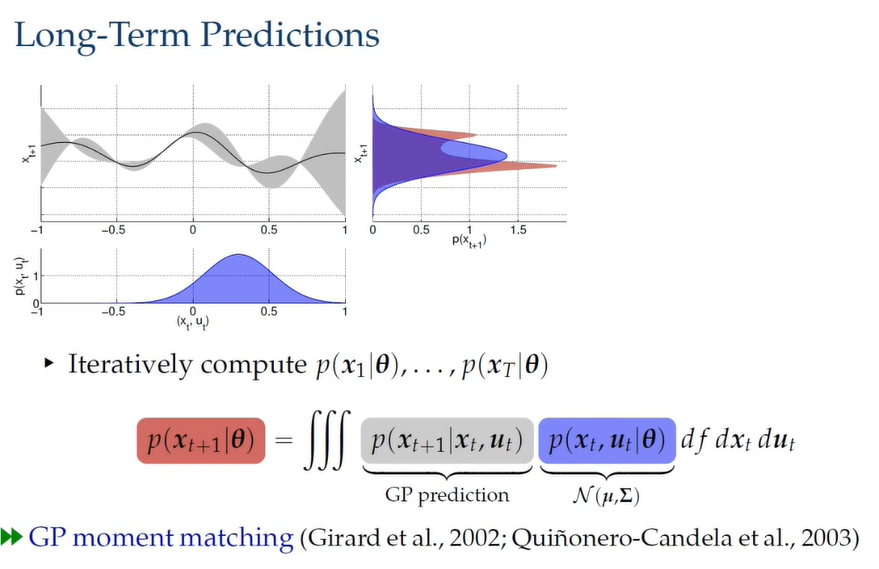
通过对 GPs 预测模型以及 state 与 control 的分布的积分,我们可以得到红色的分布。然而这个分布是没法计算的,因此使用 moment matching (MM) 将这个分布近似为一个高斯分布。
Decision Making

根据 Prediction 的结果,我们就可以通过对序列时刻的分布积分得到 long-term loss,从而更新 policy。
可以关注下图列出的论文

Safe Exploration
这一节是关于现实环境机器人自主探索中需要具备安全探索的能力,因为real-world robotics的实验一旦crash代价很大。
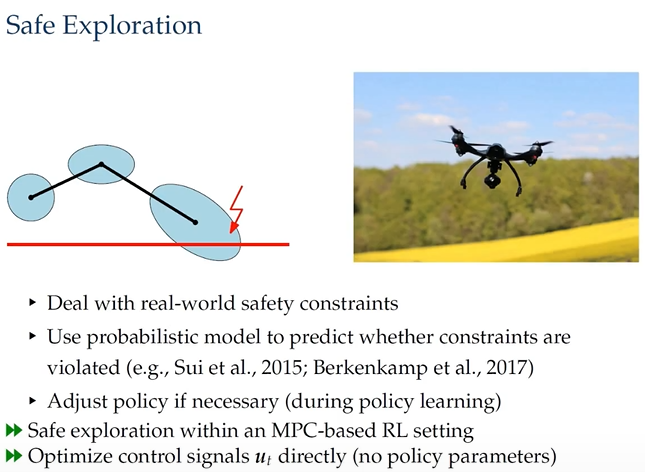
具体的做法就是将 MPC 引入到 RL 中,预测状态分布,并同时判断其安全性。


Meta Reinforcement Learning
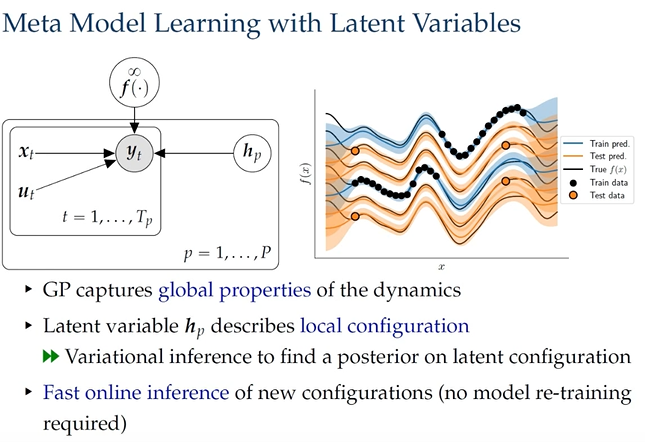
针对不同机器人(参数不同)之间的 knowledge transfer,可以使用 Meta-learning 的思路,使学习得到的控制经验可以在不同类型的机器人之间共享。

具体地,就是将机器人不同的参数配置作为隐变量加入到参数学习之中,使 GPs 能够得到动力学的全局特性,从而在新的机器人上快速的推断出相应的 GPs model。
Conclusion

本文来自个人知乎专栏:RL in Robotics
PR (Probabilistic Robotics) 系列文章是 RL in Robotics 专栏的核心内容,旨在结合 Probability Theory、Probabilistic Graph Model 以及 Representation Learning 等相关理论提升 Reinforcement Learning 在 real-world Robotics 应用中的性能。
Efficient 分章瞄准强化学习在机器人应用中存在的训练样本需求巨大的问题,旨在提升算法的 data/sample-efficient。